1. Introduction
Welcome to the AI Ethics program! Here are a few key things to know about how the program is structured. Throughout the course, you’ll have access to materials in both text and audio formats. In many sections, you’ll find audio narration alongside the text—just click play and follow along at your own pace.
Program Structure
Sprint contain multiple parts. Each part includes written content, accompanied by voice guide. You should go through the content as it is arranged.
After completing each part, you will need to complete a quiz that will allow you to test your knowledge. The quizzes on the Turing platform are meant for self-evaluation — do not be discouraged if you answer some incorrectly because there are absolutely no penalties for that. Instead, if you get some answers wrong, work on figuring out why the correct answer is different.
Finally, after completing the theory-focused parts of each sprint, you will get to work on practical projects. These projects are usually the final parts of each sprint - the current sprint has one, too. Practical projects and project reviews are among the main unique benefits that you will receive as a student at Turing College. To progress to the next sprint, you will need to participate in a live 1-1 call scheduled through the platform with our Turing College mentors. More will be explained in the final Part of this Sprint.
Revision of core Turing College concepts
If you haven’t done so before, be sure to read the following documents about the core aspects of Turing College. The first quizzes may even contain questions that will test your understanding of these topics.
Core Turing College Concepts
In addition to the events mentioned above, AI Ethics learners will have access to dedicated Learning Sessions. These sessions provide an opportunity to engage with a mentor to explore topics in greater depth, share perspectives, and clarify your understanding. You can also use this time to offer feedback on your learning experience. You will find the Learning Sessions on your calendar.
Each part of the program begins with an introduction and is divided into several units. These units are organized within collapsible menus. Be sure to go through all units in a part before moving on to the next one.
Now, let’s dive in!
Context
Sprint 1 establishes the foundation for all subsequent fairness work, focusing on assessment methodology before technical interventions. Without systematic assessment, fairness efforts often target symptoms rather than causes.
This Sprint builds the groundwork for later work: Sprint 2 covers technical intervention strategies, Sprint 3 explores organizational implementation, and Sprint 4A translates concepts into code. The Sprint Project follows a domain-driven approach, working backwards from our desired outcome—a fairness assessment methodology—to its necessary components.
Learning Objectives
By the end of this Sprint, you will:
- Analyze how historical patterns of discrimination manifest in AI systems by mapping bias mechanisms to data attributes and model behaviors.
- Select appropriate fairness definitions based on application context by navigating mathematical fairness formulations.
- Identify potential bias sources throughout the ML lifecycle by mapping where bias enters systems.
- Translate ethical principles into concrete evaluation procedures by connecting abstract values to assessment techniques.
- Develop assessment methodologies that integrate multiple fairness dimensions by synthesizing historical, definitional, and technical components.
Sprint Project Overview
Project Description
In Sprint 1, you will develop a Fairness Audit Playbook—a methodology for evaluating AI systems across multiple fairness dimensions. This framework assesses whether AI systems perpetuate historical biases, how they align with fairness definitions, where bias enters systems, and how these issues manifest in measurable outcomes.

The Playbook operationalizes fairness through historical analysis, precise definitions, bias identification, and measurement—creating accountability through documented evaluation processes.
Project Structure
The project builds across five Parts, with each developing a critical component:
- Part 1: Historical Context Assessment Tool—identifies historical discrimination patterns and maps them to application risks.
- Part 2: Fairness Definition Selection Tool—guides selection of appropriate fairness definitions.
- Part 3: Bias Source Identification Tool—locates potential bias entry points throughout the AI lifecycle.
- Part 4: Fairness Metrics Tool—provides approaches for measuring fairness.
- Part 5: Fairness Audit Playbook—synthesizes these components into a cohesive methodology.
Historical patterns from Part 1 inform fairness definition selection in Part 2, which guides bias source identification in Part 3, which shapes metric selection in Part 4. All components integrate through standardized workflows in Part 5.
Key Questions and Topics
How do historical patterns of discrimination manifest in modern AI systems, and how can historical analysis identify high-risk applications?
Many AI systems continue patterns of discrimination established in pre-digital systems through mechanisms that appear neutral but reproduce historical inequities. Examples include predictive policing algorithms that reinforce over-policing or lending algorithms that reproduce redlining practices. The Historical Context Assessment Tool you'll develop creates a methodology for identifying relevant historical patterns and mapping them to system risks, helping pinpoint which applications require scrutiny.
How do we translate abstract fairness concepts into precise mathematical definitions, and how do we select appropriate definitions for specific contexts?
Fairness encompasses multiple mathematical definitions that operationalize different ethical principles. A central challenge is that multiple desirable fairness definitions cannot be simultaneously satisfied. For example, choosing between equal opportunity and demographic parity represents a choice about prioritizing meritocratic principles or representation goals. The Fairness Definition Selection Tool you'll develop will provide guidance for navigating these trade-offs, creating transparency around fairness priorities in specific contexts.
Where and how does bias enter AI systems throughout the machine learning lifecycle, and what methodologies enable tracing unfairness to specific sources?
Different bias types require different mitigation strategies. Historical bias stemming from societal inequities requires different interventions than representation bias from sampling procedures. The Bias Source Identification Tool you'll develop enables assessment of which bias types are most relevant for specific applications and where they enter the system, transforming bias identification from an ad hoc process to a methodical approach.
How do we quantify fairness through metrics, and how should we address statistical challenges when measuring fairness?
Fairness measurement requires translating abstract definitions into concrete metrics. Measurement without statistical validation can lead to spurious conclusions, particularly when comparing performance across groups with different sample sizes. The Fairness Metrics Tool you'll develop provides metric definitions, validation approaches, and reporting formats for empirical assessment, enabling you to determine whether systems achieve their intended fairness goals.
Part Overviews
Part 1: Historical & Societal Foundations of AI Fairness examines how historical patterns of discrimination manifest in technology. You will analyze historical continuity in technological bias, representation politics in data systems, and technology's role in social stratification. This Part culminates in developing the Historical Context Assessment Tool, which identifies historical patterns relevant to specific AI applications and maps them to potential system risks.
Part 2: Defining and Contextualizing Fairness explores translating abstract ethical concepts into precise mathematical definitions. You will examine philosophical foundations, mathematical formulations, and tensions between different fairness criteria. This Part concludes with developing the Fairness Definition Selection Tool, a methodology for selecting appropriate fairness definitions based on application context, ethical principles, and legal requirements.
Part 3: Types and Sources of Bias investigates where and how bias enters the machine learning lifecycle. You will develop a taxonomy of bias types, examine how different biases manifest at different pipeline stages, and create methods for bias identification. This Part culminates in developing the Bias Source Identification Tool, a framework for locating potential bias entry points throughout the ML lifecycle.
Part 4: Fairness Metrics and Evaluation focuses on quantifying fairness through metrics. You will learn to translate fairness definitions into measurable criteria, implement statistical validation, and communicate results. This Part concludes with developing the Fairness Metrics Tool, a methodology for selecting, implementing, and interpreting fairness metrics.
Part 5: Fairness Audit Playbook synthesizes the previous components into a cohesive assessment methodology. You will integrate historical context, fairness definitions, bias sources, and metrics into standardized workflows with clear documentation. This Part brings all components together into the complete Fairness Audit Playbook, enabling systematic fairness evaluation across diverse AI applications.
Part 1: Historical & Societal Foundations of AI Fairness

Context
Understanding historical discrimination patterns is essential for effective AI fairness work. This Part establishes a framework for analyzing how historical biases manifest in AI systems, teaching you to recognize AI biases as manifestations of longstanding discrimination patterns rather than isolated technical problems.
Technologies consistently reflect and reinforce social hierarchies—from medical technologies calibrated for male bodies to speech recognition systems performing poorly for non-native accents. These patterns persist across technological transitions. Data categorization systems (like census categories for race or medical classification systems) embed political assumptions that shape who benefits or faces harm when these practices inform contemporary datasets.
Throughout history, technologies have both reflected social hierarchies and reinforced them. Mid-20th century mortgage lending technologies encoded redlining practices, while today's algorithmic systems may reproduce similar patterns through variables correlated with protected attributes.

Historical patterns manifest across ML system components—from problem formulation to data collection, feature engineering, evaluation metrics, and deployment contexts. Furthermore, discrimination operates through complex interactions between multiple forms of marginalization, requiring intersectional analysis that examines how protected attributes interact rather than treating each in isolation.
The Historical Context Assessment Tool you'll develop in Unit 5 represents the first component of the Fairness Audit Playbook (Sprint Project). This tool will help you identify relevant historical discrimination patterns for specific AI applications and map them to potential system risks, ensuring interventions address root causes rather than symptoms.

Learning Objectives
By the end of this Part, you will be able to:
- Analyze how historical patterns of discrimination manifest in technology. You will identify recurring mechanisms through which historical biases persist across technological transitions, recognizing how seemingly neutral design decisions can encode discriminatory patterns.
- Evaluate how social contexts shape data representation. You will examine how power relations influence data collection, categorization, and representation practices, enabling critical assessment of data sources and representation choices.
- Apply ethical frameworks to historical fairness analysis. You will utilize various ethical perspectives to evaluate fairness across different cultural and temporal contexts, enabling navigation of complex normative questions.
- Identify high-risk AI applications based on historical patterns. You will systematically connect historical discrimination patterns to specific AI applications, enabling proactive fairness interventions focused on high-risk domains.
- Develop intersectional approaches to historical analysis. You will create analytical approaches examining how multiple forms of discrimination interact, moving beyond single-attribute analysis to understand complex patterns across overlapping demographic categories.
Units
Unit 1
Unit 1: Historical Patterns of Discrimination in Technology
1. Conceptual Foundation and Relevance
Guiding Questions
- Question 1: How have technologies throughout history reflected, reinforced, and sometimes challenged existing social hierarchies and discriminatory patterns?
- Question 2: What recurring mechanisms enable bias to persist across technological transitions, from mechanical systems to computerization to contemporary AI?
Conceptual Context
Understanding historical patterns of discrimination in technology is foundational to addressing fairness in AI systems. Far from being novel phenomena, the biases we observe in machine learning applications today often represent technological continuations of long-established discriminatory patterns. As Crawford (2021) notes in her analysis of AI systems, "the past is prologue" — historical arrangements of power and privilege become encoded in our technological infrastructure, creating what she terms "political machines" rather than neutral tools.
This historical perspective is essential because it shifts your focus from treating algorithmic bias as merely a technical problem requiring technical solutions to recognizing it as a sociotechnical phenomenon with deep historical roots. When you understand how technologies have consistently reflected and often amplified existing social hierarchies, you develop a more comprehensive framework for identifying potential fairness issues before they manifest in deployed systems.
This Unit builds the cornerstone for subsequent analysis in this Part and the broader Sprint. By examining recurring patterns of technological discrimination, you establish historical templates that inform data representation analysis in Unit 2, provide context for ethical frameworks in Unit 3, and create comparative foundations for analyzing modern manifestations in Unit 4. These insights will directly contribute to the Historical Context Assessment Tool you'll develop in Unit 5, enabling systematic identification of relevant historical patterns for specific AI applications.
2. Key Concepts
Technological Continuity of Discriminatory Patterns
Technologies throughout history have consistently reflected and often reinforced existing social hierarchies rather than disrupting them. This concept is crucial for AI fairness because it helps you recognize that algorithmic bias represents a technological evolution of historical discrimination patterns rather than a novel phenomenon. By identifying these continuities, you can anticipate potential fairness issues in AI systems based on historical precedents.
This concept connects to other fairness concepts by establishing historical templates that inform data representation politics, problem formulation choices, and evaluation criteria. Understanding these historical continuities provides the foundation for identifying which applications require particular scrutiny based on their connection to domains with established discrimination patterns.
Historian of technology Mar (2016) demonstrates this continuity by tracing how telephone technologies in the early 20th century maintained social stratification through differential access. Despite the telephone's technical potential to democratize communication, economic and social barriers resulted in telephone networks that primarily connected privileged communities while excluding marginalized populations. The tiered service model—with party lines for lower-income communities and private lines for wealthier areas—functionally extended existing social hierarchies into the new technological infrastructure.
This pattern persists in contemporary digital technologies. For instance, Eubanks (2018) documents how welfare administration systems automate and intensify existing patterns of surveillance and punishment directed at economically marginalized communities. These systems subject benefit recipients to intensive data collection, algorithmic assessment, and automated decision-making in ways that echo historical patterns of control over these populations.
For the Historical Context Assessment Tool you'll develop, understanding technological continuity enables you to systematically identify relevant historical patterns for specific AI applications. By recognizing these continuities, you can anticipate which historical patterns might manifest in particular technological contexts, focusing fairness assessments on the most relevant historical precedents.
Encoded Social Categories and Classification Systems
Technologies encode social classifications that reflect specific historical and political contexts rather than objective or natural categories. This concept is fundamental to AI fairness because machine learning systems inevitably inherit and sometimes amplify these historically contingent classification schemes through their training data and problem formulations.
This concept interacts with data representation by highlighting how seemingly technical classification decisions embody specific historical perspectives. It connects to fairness metrics by demonstrating why certain attributes become protected categories requiring particular attention in fairness evaluations.
Bowker and Star's (1999) influential analysis of classification systems demonstrates how medical diagnostic categories evolved through complex social and political processes rather than simply reflecting natural biological distinctions. Their research shows how the International Classification of Diseases (ICD) has shifted dramatically over time, as categories emerged from negotiations between medical, insurance, and government stakeholders rather than from objective scientific discovery alone.
In AI systems, these historical classification decisions become encoded through training data. For example, facial analysis technologies often employ binary gender classification (male/female) that erases non-binary and transgender identities. When datasets like Labeled Faces in the Wild (LFW) contain these binary classifications, the machine learning systems trained on them inevitably reproduce and sometimes amplify this categorical erasure (Keyes, 2018).
For the Historical Context Assessment Tool, understanding encoded social categories helps you identify how historical classification systems might influence contemporary AI applications. By recognizing the historical contingency of classifications used in training data, problem formulations, and evaluation metrics, you can better assess which aspects of an AI system might reproduce problematic categorization patterns.
Technology's Role in Social Stratification
Technologies have historically functioned as mechanisms for maintaining or challenging existing social hierarchies, often determining who benefits from technological advances and who bears their burdens. This concept is essential for AI fairness because it helps you recognize how AI systems may similarly maintain or amplify social stratification when deployed in contexts with existing power imbalances.
This concept connects to fairness evaluation by highlighting the importance of examining not just technical performance but also social impact. It interacts with fairness metrics by demonstrating why disaggregated analysis across social groups is essential for understanding differential effects.
Noble's (2018) research on search engine algorithms demonstrates how these technologies often reinforce existing racial and gender stereotypes. Her analysis of Google search results shows how algorithms could return dehumanizing and sexualized results for searches related to Black women, effectively amplifying existing patterns of marginalization. Noble terms this phenomenon "technological redlining," drawing an explicit connection to historical housing discrimination practices.
Similarly, Benjamin (2019) documents how facial recognition technologies consistently perform worse on darker-skinned faces, particularly for women, creating what she terms a "New Jim Code" that extends historical patterns of racial discrimination into the algorithmic era. These technologies don't merely reflect existing social hierarchies but actively intensify them by subjecting certain populations to higher error rates and their negative consequences.
For the Historical Context Assessment Tool, understanding technology's role in social stratification helps you identify which applications present the highest risk of perpetuating or amplifying existing hierarchies. By examining historical precedents of how technologies have affected social stratification, you can better assess which contemporary AI applications require particularly careful fairness evaluation.
Selective Optimization in Technical Development
Throughout history, technologies have been selectively optimized for the needs, bodies, and contexts of dominant groups, creating systematic performance disparities when applied to marginalized populations. This concept is critical for AI fairness because machine learning systems similarly learn to optimize for majority patterns represented in training data, potentially creating performance disparities across demographic groups.
This concept interacts with fairness metrics by highlighting why simply optimizing for overall accuracy can perpetuate historical disparities. It connects to data representation by demonstrating how certain populations become "edge cases" due to their underrepresentation in the development process.
Criado Perez (2019) documents how supposedly "universal" technologies from automotive safety features to medical devices have historically been designed primarily for male bodies, creating potentially dangerous performance disparities for women. For instance, crash test dummies based on male physiology led to seatbelt and airbag designs that provided less protection for the average woman, leading to higher injury rates in accidents.
In AI systems, similar optimization patterns emerge when facial recognition technologies are primarily developed and tested on lighter-skinned male faces. Buolamwini and Gebru's (2018) landmark "Gender Shades" study demonstrated that commercial facial analysis technologies exhibited error rate disparities of up to 34.4% between light-skinned men and dark-skinned women, reflecting the selective optimization of these systems for majority groups.
For the Historical Context Assessment Tool, understanding selective optimization helps you identify potential performance disparities in AI applications based on historical precedents. By recognizing which populations have historically been treated as "edge cases" in specific domains, you can better assess which groups might experience similar marginalization in contemporary AI systems.
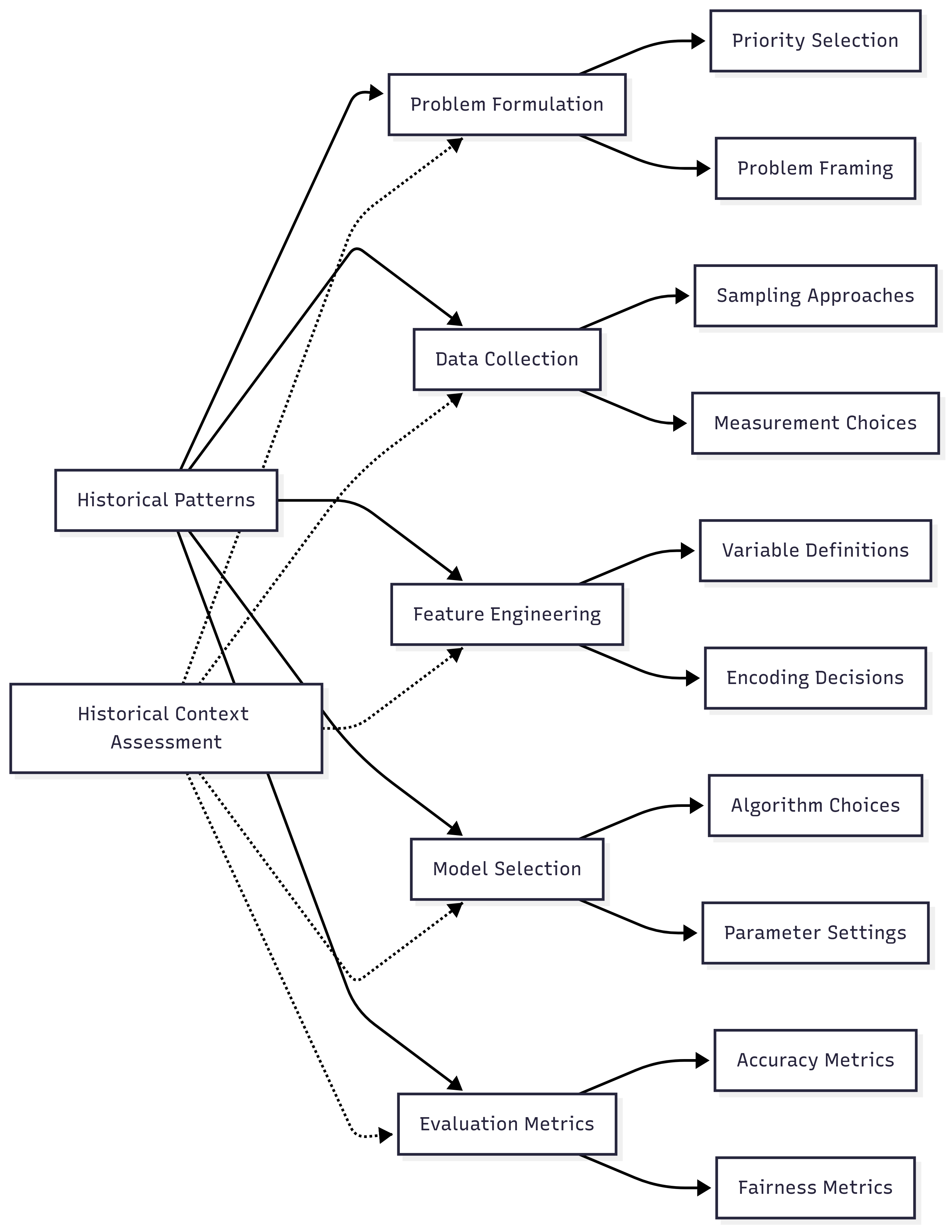
Domain Modeling Perspective
From a domain modeling perspective, historical patterns of discrimination map to specific components of ML systems:
- Problem Formulation: Historical problems and priorities influence which issues are deemed worthy of technological intervention and how success is defined.
- Data Collection: Historical sampling biases shape who is represented in datasets and what attributes are measured.
- Feature Engineering: Historical classification systems determine how variables are defined and encoded.
- Model Selection: Historical performance expectations influence which algorithms are selected and how they're configured.
- Evaluation Metrics: Historical values determine which outcomes are prioritized and which disparities are deemed acceptable.
This domain mapping helps you understand how historical patterns manifest at different stages of the ML lifecycle rather than treating bias as a generic technical issue. The Historical Context Assessment Tool will incorporate this mapping to identify stage-specific risks based on relevant historical patterns.
Conceptual Clarification
To clarify these abstract historical concepts, consider the following analogies:
- Technological continuity of discrimination functions like architectural inheritance in cities—just as modern buildings are constructed on foundations laid by previous generations, creating structural continuities despite surface-level changes, new technologies build upon existing social infrastructures. Even when their interfaces change dramatically, they often preserve and sometimes intensify historical patterns of access and exclusion. This helps explain why technologies that appear radically new often reproduce familiar patterns of discrimination.
- Encoded social categories operate like measurement systems—just as the choice between metric and imperial units represents specific historical contexts rather than natural distinctions, social classification systems reflect particular historical perspectives rather than objective realities. When technologies adopt these classification systems, they inevitably inherit the historical perspectives embedded within them. This explains why seemingly technical decisions about categories can have profound fairness implications.
- Technology's role in social stratification resembles how transportation infrastructure shapes city development—just as highway placement decisions in mid-20th century American cities often reinforced residential segregation by cutting through Black neighborhoods while connecting white suburbs, technological infrastructure can either reinforce or challenge existing social boundaries. This helps you recognize why the deployment context of AI systems significantly influences their fairness implications.
Intersectionality Consideration
Historical patterns of discrimination have never operated along single identity dimensions but through complex interactions between multiple forms of marginalization. Crenshaw's (1989) foundational work on intersectionality demonstrates that analyzing discrimination along single axes (e.g., only race or only gender) fails to capture unique forms of marginalization experienced at their intersections.
For technologies, this means discrimination patterns often manifest differently across intersectional identities. For example, Benjamin (2019) notes that facial recognition technologies typically perform worst on darker-skinned women—a pattern that wouldn't be captured by examining either racial or gender disparities in isolation.
The Historical Context Assessment Tool must explicitly incorporate intersectional analysis by:
- Examining historical patterns across multiple dimensions simultaneously rather than treating each protected attribute in isolation;
- Identifying unique discrimination mechanisms that operate at demographic intersections;
- Recognizing how multiple forms of marginalization interact to create distinct technological experiences.
By incorporating these intersectional considerations, the tool will enable more comprehensive identification of relevant historical patterns, avoiding the analytical blindspots that occur when examining protected attributes independently.
3. Practical Considerations
Implementation Framework
To systematically analyze historical patterns of discrimination in technology, follow this structured methodology:
-
Historical Pattern Identification
-
Examine historical discrimination in the specific domain where the AI system will be deployed (e.g., healthcare, criminal justice, hiring).
- Research how previous technologies in this domain have reflected, reinforced, or challenged existing social hierarchies.
-
Identify recurring mechanisms through which bias has persisted across technological transitions in this domain.
-
Pattern-to-Risk Mapping
-
Map identified historical patterns to specific components of the ML system under consideration.
- Determine how historical classification systems might influence feature definitions and encodings.
- Assess how historical performance disparities might manifest in model accuracy across groups.
-
Analyze how historical optimization priorities might shape evaluation metrics and thresholds.
-
Prioritization Framework
-
Assess the strength of the historical connection between identified patterns and the current application.
- Evaluate the potential harm if historical patterns were to recur in the current system.
- Determine the visibility of potential bias (some forms are more readily apparent than others).
- Prioritize which historical patterns require particular attention in subsequent fairness assessments.
These methodologies should integrate with standard ML workflows by informing initial risk assessment during problem formulation, guiding data collection and feature engineering decisions, and establishing evaluation criteria that account for historical disparities.
Implementation Challenges
When implementing historical analysis in AI fairness assessments, practitioners commonly face these challenges:
-
Limited Historical Knowledge: Most data scientists lack deep historical knowledge about discrimination patterns in specific domains. Address this by:
-
Collaborating with domain experts who understand the historical context.
- Creating accessible resources summarizing key historical patterns for commonly used applications.
-
Developing standard templates that guide non-historians through the essential questions.
-
Communicating Historical Relevance to Technical Teams: Teams may resist historical analysis as irrelevant to technical implementation. Address this by:
-
Framing historical patterns as risk factors that directly impact system performance.
- Providing concrete examples where historical understanding prevented fairness issues.
- Developing visualizations that explicitly connect historical patterns to system components.
Successfully implementing historical analysis requires resources including time for research, access to domain experts, and educational materials that make historical patterns accessible to technical practitioners without extensive background knowledge.
Evaluation Approach
To assess whether your historical analysis is effective, implement these evaluation strategies:
-
Coverage Assessment:
-
Verify that the analysis examines multiple historical periods, not just recent precedents.
- Ensure assessment covers various discrimination mechanisms, not just the most obvious forms.
-
Confirm the analysis addresses intersectional considerations rather than treating protected attributes in isolation.
-
Connection Verification:
-
Evaluate whether identified historical patterns have clear connections to the current application.
- Verify that mapped risks are specific to system components rather than general concerns.
-
Assess whether prioritization decisions are justified by evidence rather than assumptions.
-
Actionability Check:
-
Determine whether the analysis produces actionable insights for subsequent fairness work.
- Verify that identified historical patterns inform concrete assessment approaches.
- Ensure the analysis suggests specific monitoring metrics based on historical patterns.
These evaluation approaches should be integrated with your organization's fairness governance process, providing a systematic way to verify that historical context has been appropriately considered in the AI development process.
4. Case Study: Criminal Risk Assessment Systems
Scenario Context
A government agency is developing a machine learning-based risk assessment system to predict recidivism risk for individuals awaiting trial, with predictions informing pre-trial detention decisions. Stakeholders include the judicial system seeking efficiency, defendants whose liberty is at stake, communities affected by crime and incarceration, and government officials concerned with both public safety and system fairness.
This scenario presents significant fairness challenges due to the domain's extensive history of racial discrimination and the high stakes of prediction errors for both individuals and communities.
Problem Analysis
Applying core concepts from this Unit reveals several historical patterns highly relevant to this application:
- Technological Continuity: Historical risk assessment in criminal justice has consistently reflected racial biases in the broader system. Harcourt's (2010) research demonstrates how early 20th century parole prediction instruments—using factors like "family criminality" and neighborhood characteristics—functionally embedded racial discrimination in seemingly objective assessments, creating a precedent for algorithms that predict higher risk for Black defendants.
- Encoded Social Categories: The criminal justice system has historically employed categories that reflect specific power relations rather than objective classifications. For instance, the category of "prior police contact" treats discretionary police attention as an objective measure of criminal tendency—despite extensive evidence that policing has historically focused disproportionately on Black neighborhoods regardless of actual crime rates (Hinton, 2016).
- Technology's Role in Social Stratification: Technologies in criminal justice have historically amplified existing disparities. Ferguson (2017) documents how early data-driven policing technologies directed additional police resources to already over-policed areas, creating feedback loops that intensified racial disparities in the criminal justice system.
- Selective Optimization: Criminal risk assessment tools have historically been optimized for predicting outcomes defined by a system with documented racial biases. Richardson et al. (2019) demonstrate how these tools often predict future arrest (which reflects policing patterns) rather than actual criminal behavior, optimizing for a variable shaped by historical discrimination.
From an intersectional perspective, these patterns manifest differently across demographic intersections. For example, Ritchie (2017) documents how Black women experience unique forms of criminalization that wouldn't be captured by examining either racial or gender disparities in isolation. This suggests the risk assessment system might create distinctive fairness issues for specific intersectional groups.
Solution Implementation
To address these historical patterns, the team implemented a structured historical analysis approach:
- They first conducted comprehensive historical research on criminal risk assessment, examining both academic literature and consulting with criminal justice reform advocates who provided historical context about how similar tools have affected marginalized communities.
-
They developed a detailed mapping between historical discrimination patterns and specific components of the proposed system:
-
Problem formulation: Questioned whether predicting "recidivism" operationalized as re-arrest rather than reconviction reproduces historical policing biases.
- Data collection: Identified that training data reflected historical patterns of over-policing in certain communities.
- Feature selection: Recognized that variables like "prior police contact" and "neighborhood characteristics" have functioned as proxies for race throughout criminal justice history.
-
Evaluation metrics: Determined that optimizing only for overall accuracy would likely reproduce historical disparities.
-
They created a prioritization framework that identified the use of arrest-based outcome measures and neighborhood-based features as highest-risk elements based on their strong historical connection to documented discrimination patterns.
- They implemented an intersectional analysis component that examined how prediction patterns might differ across specific demographic intersections, particularly focusing on how the system might affect Black women differently than other groups.
Throughout implementation, they maintained detailed documentation of identified historical patterns and their connection to specific system components, creating an audit trail that informed subsequent fairness assessments.
Outcomes and Lessons
The historical pattern analysis yielded several critical insights that significantly influenced the system development:
- The team redefined the prediction target from "any re-arrest" to "conviction for a violent offense," reducing the influence of discriminatory policing patterns on the outcome variable.
- They eliminated neighborhood-based features with strong historical connections to redlining and segregation, reducing a major source of proxy discrimination.
- They implemented disaggregated performance evaluation across both broad demographic categories and specific intersections, revealing performance disparities that wouldn't have been apparent in aggregate metrics.
- They developed custom fairness metrics based on the specific historical patterns identified, rather than applying generic fairness definitions.
Key generalizable lessons included:
- Historical analysis is most effective when it produces specific, actionable insights rather than general observations about discrimination.
- Collaboration between technical teams and domain experts with historical knowledge significantly improves the quality of historical pattern identification.
- Explicit documentation of historical patterns creates accountability and ensures historical insights inform the entire development process.
- Intersectional analysis reveals unique fairness concerns that wouldn't be captured by examining protected attributes in isolation.
These insights directly informed the development of the Historical Context Assessment Tool, particularly the need for structured methodologies that connect specific historical patterns to concrete technical components.
5. Frequently Asked Questions
FAQ 1: Historical Relevance to Technical Implementation
Q: How does historical analysis practically impact technical implementation decisions in machine learning systems?
A: Historical analysis directly informs several critical technical decisions: First, it helps identify high-risk features that have historically functioned as proxies for protected attributes, guiding feature selection and engineering. Second, it informs outcome variable definition by revealing how certain operationalizations may embed historical biases, leading to more careful problem formulation. Third, it guides the selection of appropriate fairness metrics and thresholds based on historical disparities in the domain. Fourth, it informs disaggregated evaluation strategies by identifying which demographic groups and intersections have historically experienced unique discrimination patterns. Rather than a separate "historical analysis" phase, this approach should integrate throughout the technical development process, informing design decisions at each stage.
FAQ 2: Balancing Historical Awareness With Innovation
Q: How can we acknowledge historical discrimination patterns without assuming a new system will necessarily reproduce them?
A: Historical analysis should function as risk assessment rather than deterministic prediction—identifying where bias might emerge without assuming it inevitably will. The goal is targeted vigilance rather than technological pessimism. Practically, you should: (1) Document relevant historical patterns as specific risk factors rather than foregone conclusions; (2) Design targeted testing and evaluation focused on these risk factors; (3) Implement monitoring systems that track whether historical patterns actually emerge in the deployed system; and (4) Create feedback mechanisms that enable continuous improvement based on observed outcomes. This approach treats historical patterns as important warning signs warranting careful attention rather than inescapable constraints, allowing for innovation while maintaining appropriate caution in high-risk domains.
6. Summary and Next Steps
Key Takeaways
Throughout this Unit, you've explored how technologies throughout history have reflected, reinforced, and sometimes challenged existing social hierarchies. Key insights include:
- Technological Continuity: Discrimination patterns persist across technological transitions, with new technologies often reproducing and sometimes intensifying historical inequities despite surface-level changes.
- Encoded Social Categories: Technologies inevitably embed classification systems that reflect specific historical and political contexts rather than objective realities.
- Social Stratification: Technologies have historically functioned as mechanisms for maintaining or challenging existing social hierarchies, determining who benefits and who bears burdens.
- Selective Optimization: Technologies are typically optimized for dominant groups, creating systematic performance disparities when applied to marginalized populations.
These concepts directly address our guiding questions by explaining how historical patterns persist in modern systems and identifying the recurring mechanisms that enable this continuity. They provide the essential foundation for the Historical Context Assessment Tool by establishing what patterns to look for and how they typically manifest.
Application Guidance
To apply these concepts in your practical work:
- For each new AI application, research the specific history of technology use and discrimination in that domain rather than relying on generic patterns.
- Examine the categories embedded in your data and question their historical origins rather than treating them as natural or inevitable.
- Consider who has historically benefited from and been harmed by technologies in your application domain, and assess whether your current system might reproduce these patterns.
- Document identified historical patterns specifically enough to inform concrete technical decisions, not just general fairness aspirations.
If you're new to historical analysis in AI, start with well-documented domains like criminal justice, hiring, or healthcare, where extensive research already exists on historical discrimination patterns. Build your analytical capabilities in these areas before tackling domains with less established historical analysis.
Looking Ahead
In the next Unit, we'll build on this historical foundation by examining how social contexts shape data representation. You will learn how classification systems and measurement practices encode power relations, how missing data reflects strategic decisions rather than random omissions, and how data collection practices amplify or mitigate historical biases.
The historical patterns you've learned to identify will directly inform this data representation analysis, helping you recognize how classification decisions in modern datasets might reflect and reproduce historical discrimination patterns. By connecting historical awareness to specific data practices, you'll develop a more comprehensive understanding of how bias enters AI systems through seemingly technical data representation choices.
References
Benjamin, R. (2019). Race after technology: Abolitionist tools for the new Jim Code. Polity.
Bertrand, M., & Mullainathan, S. (2004). Are Emily and Greg more employable than Lakisha and Jamal? A field experiment on labor market discrimination. American Economic Review, 94(4), 991-1013.
Bowker, G. C., & Star, S. L. (1999). Sorting things out: Classification and its consequences. MIT Press.
Buolamwini, J., & Gebru, T. (2018). Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the 1st Conference on Fairness, Accountability, and Transparency (pp. 77–91).
Collins, P. H. (2000). Black feminist thought: Knowledge, consciousness, and the politics of empowerment (2nd ed.). Routledge.
Crawford, K. (2021). Atlas of AI: Power, politics, and the planetary costs of artificial intelligence. Yale University Press.
Crenshaw, K. (1989). Demarginalizing the intersection of race and sex: A Black feminist critique of antidiscrimination doctrine, feminist theory and antiracist politics. University of Chicago Legal Forum, 1989(1), 139-167.
Criado Perez, C. (2019). Invisible women: Data bias in a world designed for men. Abrams Press.
Eubanks, V. (2018). Automating inequality: How high-tech tools profile, police, and punish the poor. St. Martin's Press.
Ferguson, A. G. (2017). The rise of big data policing: Surveillance, race, and the future of law enforcement. NYU Press.
Harcourt, B. E. (2010). Against prediction: Profiling, policing, and punishing in an actuarial age. University of Chicago Press.
Hinton, E. (2016). From the war on poverty to the war on crime: The making of mass incarceration in America. Harvard University Press.
Keyes, O. (2018). The misgendering machines: Trans/HCI implications of automatic gender recognition. Proceedings of the ACM on Human-Computer Interaction, 2(CSCW), 1-22.
Mar, S. T. (2016). The mechanics of racial segregation in telecommunication networks. Ethnic and Racial Studies, 39(8), 1339-1358.
Noble, S. U. (2018). Algorithms of oppression: How search engines reinforce racism. NYU Press.
Richardson, R., Schultz, J. M., & Crawford, K. (2019). Dirty data, bad predictions: How civil rights violations impact police data, predictive policing systems, and justice. New York University Law Review Online, 94, 15-55.
Ritchie, A. J. (2017). Invisible no more: Police violence against Black women and women of color. Beacon Press.
Roberts, D. (2012). Fatal invention: How science, politics, and big business re-create race in the twenty-first century. The New Press.
Unit 2
Unit 2: Data Representation and Social Context
1. Conceptual Foundation and Relevance
Guiding Questions
- Question 1: How do social contexts and power structures influence data representation in ways that can introduce or amplify bias in AI systems?
- Question 2: How can data scientists critically examine the social assumptions embedded in their dataset construction, categorization schemes, and feature representations to create more equitable AI systems?
Conceptual Context
Data representation—how we collect, categorize, and encode information about the world for machine learning systems—lies at the critical intersection of technical implementation and social meaning. While data collection and preparation often appear as purely technical tasks, they fundamentally involve social decisions about what information matters, how identity categories should be defined, and which distinctions are relevant for a particular task.
These representation choices directly influence AI fairness because they determine which aspects of reality become visible or invisible to learning algorithms. As D'Ignazio and Klein (2020) emphasize in their seminal work Data Feminism, data are not neutral reflections of reality but rather constructed artifacts that embed specific perspectives, priorities, and power structures. When these representations encode or amplify existing social inequities, AI systems trained on such data will inevitably reproduce and potentially magnify these patterns (D'Ignazio & Klein, 2020).
This Unit builds directly on the historical foundations established in Unit 1 by examining how historical patterns of discrimination shape contemporary data representation practices. It provides the essential foundation for understanding algorithm design biases in Unit 3 by establishing how social contexts influence the raw material that algorithms process. The insights you develop in this Unit will directly inform the Historical Context Assessment Tool we will develop in Unit 5, particularly in analyzing how social assumptions embedded in data representation connect to historical patterns of discrimination.
2. Key Concepts
The Politics of Classification
Classification systems—the ways we divide the world into discrete categories—are not neutral technical frameworks but rather social constructs that embed specific historical contexts, power relations, and worldviews. This concept is fundamental to AI fairness because machine learning relies heavily on classifications for both input features and prediction targets, with these classification choices directly shaping what systems can perceive and predict.
Classification connects to other fairness concepts by establishing the fundamental categories that will be used throughout the machine learning pipeline. These initial classification decisions constrain all subsequent fairness interventions, as techniques can only address biases in categories that have been recognized and encoded.
Research by Bowker and Star (1999) demonstrates how classification systems that appear technical or objective actually embed specific sociopolitical assumptions. In their landmark book Sorting Things Out, they examine how medical classification systems like the International Classification of Diseases (ICD) developed through complex political negotiations rather than purely scientific processes, with significant consequences for how health conditions are understood, treated, and funded (Bowker & Star, 1999).
These insights apply directly to AI fairness when considering how protected attribute categories are defined in datasets. For instance, binary gender classifications (male/female) exclude non-binary individuals and reinforce gender as a simple binary rather than a complex social and biological spectrum. Similarly, racial classifications vary dramatically across cultures and historical periods, yet are often treated as fixed, objective categories in machine learning datasets.
For the Historical Context Assessment Tool we will develop, understanding the politics of classification will help identify how historical power structures influence contemporary data categories, revealing potential sources of bias before model development begins. By questioning classification systems rather than accepting them as given, you can identify which social assumptions are being encoded in your data and how these might privilege certain groups over others.
Missing Data and Strategic Ignorance
Missing data in datasets often reflects not just random technical limitations but "strategic ignorance"—systematic patterns of which populations, variables, and phenomena are consistently undercounted or overlooked in data collection. This concept is crucial for AI fairness because these gaps in representation can create invisible biases that standard fairness metrics fail to detect, as they typically only evaluate disparities among groups actually present in the data.
Missing data interacts with classification politics by shaping not just how phenomenon are categorized but whether they are measured at all. Together, these concepts determine which aspects of reality become visible and actionable within AI systems.
D'Ignazio and Klein (2020) illustrate this strategic ignorance through numerous examples, such as the systematic undercounting of maternal mortality in the United States, particularly for Black women. This data gap prevented recognition of a serious public health disparity for decades. Similarly, they highlight how data on sexual harassment and assault were not systematically collected until feminist activists fought for such measurement, demonstrating how power structures influence which problems are deemed worthy of data collection (D'Ignazio & Klein, 2020).
For AI systems, these gaps create significant fairness challenges. For example, Buolamwini and Gebru's (2018) landmark Gender Shades study demonstrated that facial recognition datasets contained dramatically fewer dark-skinned women, leading to higher error rates for this demographic. The absence of comprehensive data made these disparities invisible until specifically tested with a more demographically balanced evaluation set (Buolamwini & Gebru, 2018).
For our Historical Context Assessment Tool, understanding strategic ignorance will guide the development of data auditing approaches that look beyond the available data to identify which populations, variables, or contexts might be systematically missing. This approach transforms missing data from an inevitable technical limitation into an actionable fairness consideration with historical roots that can be identified and addressed.
Codification of Social Categories
The process of translating complex social categories into discrete computational representations—often through simplistic encodings like one-hot vectors or numeric scales—involves significant reduction of social complexity. This codification is fundamental to AI fairness because the technical implementation of social categories directly shapes how algorithms perceive and process social differences.
Codification connects directly to classification politics by implementing classification decisions in computational form, often further simplifying already reductive categories. This technical encoding can amplify biases present in classification systems or introduce new distortions through inappropriate mathematical representations.
As Benjamin (2019) demonstrates in her book Race After Technology, the reduction of race to simplistic computational categories fails to capture its social, historical, and contextual complexity. For instance, representing race as a set of mutually exclusive categories (e.g., one-hot encoding) mathematically enforces the problematic assumption that racial categories are clean, discrete, and universal, rather than socially constructed, overlapping, and contextually variable (Benjamin, 2019).
This codification challenge extends beyond protected attributes to proxy variables. Obermeyer et al. (2019) revealed how healthcare algorithms using medical costs as a proxy for medical needs systematically disadvantaged Black patients because the proxy failed to account for historical disparities in healthcare access. The mathematical relationship between the codified proxy (costs) and the intended concept (medical need) varied by race due to systemic inequities, creating significant algorithmic bias (Obermeyer et al., 2019).
For the Historical Context Assessment Tool, analyzing codification practices will help identify how technical implementations of social categories might embed or amplify historical biases. This includes examining not just the explicit encoding of protected attributes but also the mathematical relationships between proxy variables and social categories under various historical conditions.
Power Asymmetries in Data Production
Data production—who collects data, about whom, for what purpose, and under what conditions—involves fundamental power asymmetries that shape resulting datasets. This concept is essential for AI fairness because these asymmetries directly influence which perspectives are represented in training data and how different populations are characterized.
Power asymmetries interact with all previously discussed concepts: they influence which classifications are used, which data are collected or ignored, and how social categories are codified. Together, these interactions create complex patterns of advantage and disadvantage in data representations.
Eubanks (2018) demonstrates in her book Automating Inequality how data about poor and working-class people are disproportionately collected through surveillance and compliance systems rather than voluntary participation. This asymmetry creates datasets where marginalized groups appear primarily as problems to be solved rather than as full persons with agency and diverse experiences, shaping how these populations are represented in resulting models (Eubanks, 2018).
Similarly, research on content moderation datasets has shown that platform workers—often from the Global South—label data according to guidelines developed primarily in Western contexts, creating global datasets that nevertheless embed specific cultural assumptions about appropriate content (Roberts, 2019). This asymmetry between who develops classification schemes and who implements them creates datasets that appear universal but actually privilege particular cultural perspectives.
For our Historical Context Assessment Tool, analyzing power asymmetries in data production will help identify how historical patterns of advantage and disadvantage shape contemporary datasets through collection procedures, annotation processes, and validation practices. By examining who has agency in data production and how this agency is distributed across demographic groups, we can identify potential sources of bias that standard statistical analyses might miss.
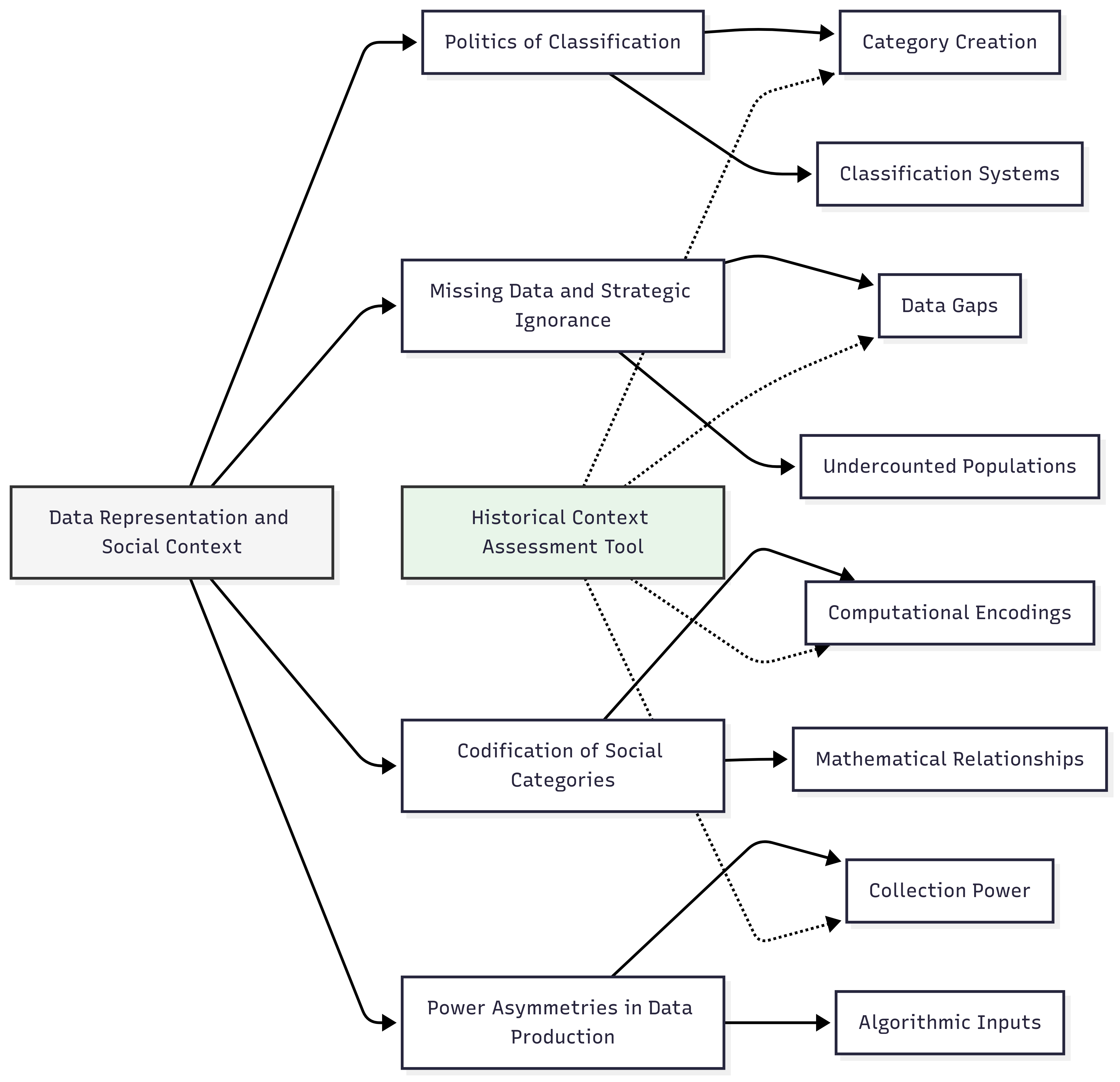
Domain Modeling Perspective
From a domain modeling perspective, data representation and social context connect to specific components of ML systems:
- Variable Selection: Which phenomena are deemed worth measuring and how these selections reflect social priorities and power structures.
- Feature Engineering: How raw measurements are transformed into features through processes that may embed social assumptions about what constitutes meaningful variation.
- Data Schema Design: How relational structures between data elements encode assumptions about which relationships matter and which can be ignored.
- Encoding Mechanisms: How categorical variables are mathematically represented and what assumptions these encodings make about category relationships.
- Metadata Frameworks: What contextual information about data collection is preserved or discarded and how this shapes interpretation.
This domain mapping helps you understand how social contexts influence specific technical components of ML systems rather than viewing bias as a generic problem. The Historical Context Assessment Tool will incorporate this mapping to help practitioners identify where and how historical patterns of discrimination might manifest in their data representations.
Conceptual Clarification
To clarify these abstract concepts, consider the following analogies:
- Classification systems function like maps that highlight certain features of terrain while necessarily omitting others. Just as mapmakers must decide which elements of geography to include and how to represent them—decisions shaped by their purpose, perspective, and historical context—data scientists select which aspects of complex social reality to encode as discrete categories. Neither maps nor classification systems are neutral representations of objective reality; both reflect specific priorities and perspectives that determine what becomes visible or invisible.
- Strategic ignorance in data collection resembles a grocery store inventory system that meticulously tracks certain products while completely ignoring others. If the inventory system carefully counts packaged foods but doesn't track fresh produce at all, analytics based on this data would provide a distorted view of overall sales patterns and customer preferences. Similarly, when data collection systematically overlooks certain populations or variables, analyses based on these incomplete datasets create distorted representations that make some issues invisible.
- Power asymmetries in data production can be understood through the analogy of restaurant reviews. When only food critics write reviews, we get a particular perspective focused on specific aspects of dining (perhaps sophisticated flavors and presentation) while missing others (like value for money or family-friendliness). Similarly, when data about marginalized communities are primarily collected by outsiders for compliance or surveillance purposes, those datasets capture particular aspects of these communities (often focused on problems) while missing others (like community strengths and internal diversity).
Intersectionality Consideration
Data representation practices present unique challenges for intersectional fairness, where multiple aspects of identity interact to create distinct experiences that cannot be understood by examining each dimension independently. Traditional data structures often flatten these intersectional experiences through simplistic, single-attribute categorizations or independent treatment of identity dimensions.
For example, analysis by Buolamwini and Gebru (2018) demonstrated that facial recognition accuracy for darker-skinned women was substantially lower than what would be predicted by examining either gender or skin tone effects independently. This intersectional effect revealed distinct patterns that would remain invisible if examining demographic disparities along single dimensions (Buolamwini & Gebru, 2018).
Similarly, Crenshaw's (1989) foundational work on intersectionality examined how employment discrimination against Black women created unique patterns that were not captured by analyzing either racial discrimination or gender discrimination in isolation. Data representation schemes that treat protected attributes as independent variables can systematically obscure these intersectional patterns (Crenshaw, 1989).
For the Historical Context Assessment Tool, addressing intersectionality in data representation requires:
- Examining how classification systems might erase or distort intersectional identities by forcing individuals into mutually exclusive categories;
- Identifying which intersectional populations might be systematically missing or undercounted in datasets;
- Analyzing how power asymmetries in data production might particularly disadvantage individuals at specific intersections; and
- Evaluating whether codification practices preserve or erase the unique patterns that emerge at demographic intersections.
By explicitly incorporating these intersectional considerations, the tool will help identify subtle representational biases that might otherwise remain undetected.
3. Practical Considerations
Implementation Framework
To systematically examine social contexts in data representation, implement this structured methodology:
-
Classification Audit:
-
Document all classification systems used in your dataset, including protected attributes and potential proxies.
- Research the historical development of these classification systems to identify potential embedded biases.
- Evaluate whether classifications capture the full diversity of the relevant population or artificially constrain representation.
-
Analyze whether classification boundaries reflect meaningful distinctions for your task or arbitrary divisions with historical baggage.
-
Representation Gap Analysis:
-
Compare dataset demographics to relevant population benchmarks to identify underrepresented groups.
- Document variables that might be systematically missing for certain populations.
- Examine whether proxy variables have consistent meaning across demographic groups.
-
Identify potential "data deserts" where information is systematically sparse due to historical collection patterns.
-
Codification Evaluation:
-
Analyze how social categories are mathematically encoded and what assumptions these encodings embed.
- Test whether distance metrics in feature space reflect meaningful similarities or arbitrary technical choices.
- Evaluate whether technical implementations preserve important social nuances or flatten complex identities.
-
Document potential information loss in the translation from social categories to computational representations.
-
Power Analysis in Data Lifecycle:
-
Document who designed the data schema and whether diverse perspectives informed these decisions.
- Analyze who collected the data and under what conditions (mandatory compliance, voluntary participation, etc.).
- Evaluate who labeled or annotated the data and what guidelines shaped these interpretations.
- Assess who validates data quality and what metrics they use to determine representativeness.
These methodologies should integrate with standard ML workflows by extending exploratory data analysis to explicitly incorporate critical social analysis. While adding complexity to data preparation, these approaches help identify potential fairness issues before they become encoded in model behavior.
Implementation Challenges
When implementing these analytical approaches, practitioners commonly face these challenges:
-
Limited Historical and Social Context Knowledge: Many data scientists lack background knowledge about the historical development of classification systems or social contexts of data production. Address this by:
-
Collaborating with domain experts from relevant social science fields;
- Researching the historical development of key classifications used in your dataset; and
-
Documenting assumptions and limitations in your understanding of social contexts.
-
Communicating Social Representation Issues in Technical Environments: Technical teams may resist considerations they view as "political" rather than technical. Address this by:
-
Framing representation issues in terms of concrete technical consequences for model performance;
- Providing specific examples where social context analysis identified issues that affected system accuracy or reliability; and
- Developing clear visualizations that illustrate representation disparities and their potential impacts.
Successfully implementing these approaches requires resources including time for deeper analysis beyond standard data profiling, access to relevant literature on social classification systems, and ideally collaboration with experts in relevant domains who can provide historical and social context for representation practices.
Evaluation Approach
To assess whether your analysis of data representation and social context is effective, implement these evaluation strategies:
-
Representation Completeness Assessment:
-
Calculate coverage metrics showing what percentage of relevant social variation is captured in your classification systems.
- Establish minimum thresholds for representation across demographic groups and intersections.
-
Document limitations in classification systems and their potential impacts on model performance.
-
Context Documentation Review:
-
Develop a rubric for evaluating the completeness of social context documentation.
- Assess whether documentation enables new team members to understand the historical and social background of key data representations.
-
Verify that limitations and assumptions about social categories are explicitly documented.
-
Stakeholder Validation:
-
Engage representatives from relevant communities to review representation choices.
- Document feedback on whether classifications and encodings respect community self-understanding.
- Implement revision processes when representation issues are identified.
These evaluation approaches should be integrated with your organization's broader data governance framework, providing structured assessments of representation quality alongside more traditional data quality metrics.
4. Case Study: Health Risk Assessment Algorithm
Scenario Context
A healthcare company is developing a machine learning system to identify patients who would benefit from enhanced care management programs. The algorithm will analyze patient records to predict future healthcare needs and assign risk scores that determine resource allocation. Key stakeholders include healthcare providers seeking efficient resource allocation, patients who would benefit from additional services, insurance companies concerned with costs, and regulators monitoring healthcare equity.
Fairness is particularly critical in this domain due to historical disparities in healthcare access, outcomes, and representation in medical data. The system will directly impact which patients receive additional resources, making representation fairness both an ethical and legal requirement under healthcare regulations.
Problem Analysis
Applying core concepts from this Unit reveals several potential representation issues in the healthcare risk assessment scenario:
- Classification Politics: The medical classification systems used in the dataset (ICD-10 codes, procedure codes, etc.) developed through complex historical processes that embed particular understandings of health and disease. Analysis reveals that certain conditions affecting different demographic groups have different historical patterns of recognition and codification. For example, conditions primarily affecting women historically received less research attention and have less granular classification than comparable conditions affecting men.
- Missing Data and Strategic Ignorance: Examination of the dataset reveals systematic patterns in missing data that correspond to historical healthcare access disparities. Patients from lower socioeconomic backgrounds have fewer preventive care visits documented, creating a pattern where their health issues often appear only when more severe. Similarly, certain racial and ethnic groups show different patterns of diagnosis that reflect access barriers rather than underlying health differences.
- Codification of Social Categories: The dataset encodes race and ethnicity using outdated classification systems that do not align with contemporary understanding or patient self-identification. Additionally, socioeconomic factors are represented through simplistic proxies like ZIP code, which flatten complex patterns of advantage and disadvantage into single variables with inconsistent meanings across geographic contexts.
- Power Asymmetries in Data Production: The electronic health record data were primarily collected by healthcare professionals rather than reflecting patient experiences directly. Documentation practices vary systematically across clinical settings that serve different demographic populations, with more detailed documentation in well-resourced facilities serving advantaged populations.
From an intersectional perspective, the dataset shows particularly complex patterns at the intersections of race, gender, and socioeconomic status. For example, the medical records of lower-income women of color show distinct documentation patterns that differ from what would be predicted by examining these factors independently.
Solution Implementation
To address these identified representation issues, the team implemented a structured approach:
-
For Classification Politics, they:
-
Collaborated with medical anthropologists to understand the historical development of relevant medical classifications;
- Identified conditions with historically biased classification and developed more balanced feature representations; and
-
Created composite features that captured health needs through multiple complementary classification systems.
-
For Missing Data and Strategic Ignorance, they:
-
Implemented statistical methods to identify and address systematic patterns in missing data;
- Developed features that explicitly captured data sparsity patterns rather than treating them as random; and
-
Created synthetic data approaches to test model sensitivity to historically underrepresented patterns.
-
For Codification of Social Categories, they:
-
Updated demographic category encodings to align with contemporary understanding and patient self-identification;
- Replaced ZIP code with more granular community-level indicators of resource access; and
-
Implemented more nuanced encodings of social determinants of health rather than simplistic proxies.
-
For Power Asymmetries in Data Production, they:
-
Incorporated patient-reported outcomes alongside clinical documentation to balance perspectives;
- Adjusted for documentation thoroughness across different clinical settings; and
- Developed features sensitive to different communication patterns between providers and patients from different backgrounds.
Throughout implementation, they maintained explicit focus on intersectional effects, ensuring that their representation improvements addressed the specific challenges faced by patients at the intersection of multiple marginalized identities.
Outcomes and Lessons
The implementation resulted in significant improvements across multiple dimensions:
- The revised algorithm showed a 45% reduction in racial disparities in resource allocation compared to the original approach.
- Previously invisible health needs in underrepresented populations became detectable through improved representation.
- The model maintained strong overall predictive performance while achieving more equitable outcomes.
Key challenges remained, including ongoing data gaps for some population subgroups and the inherent limitations of working with historically biased medical data.
The most generalizable lessons included:
- The critical importance of examining historical contexts behind medical classification systems, revealing how seemingly objective disease codes actually embed specific historical perspectives and priorities.
- The significant impact of making systematic data gaps explicit rather than treating missing data as random, enabling the model to account for these patterns rather than propagating them.
- The value of incorporating multiple perspectives in data representation, balancing provider documentation with patient-reported experiences to create more comprehensive health profiles.
These insights directly informed the development of the Historical Context Assessment Tool, particularly in creating domain-specific questions that help identify how historical patterns shape contemporary data representations across sectors.
5. Frequently Asked Questions
FAQ 1: Balancing Critical Analysis With Practical Implementation
Q: How can I incorporate critical analysis of data representation into practical ML workflows without dramatically increasing development time or creating analysis paralysis?
A: Start by incorporating targeted social context questions into existing data profiling workflows rather than creating entirely separate processes. Develop reusable templates for examining classification systems, representation gaps, codification choices, and power dynamics that can be efficiently applied across projects. Focus initial analysis on high-impact features and protected attributes, then expand as resources allow. Create documentation templates that make insights from this analysis clearly actionable for technical implementation. Most importantly, frame this analysis not as an additional burden but as an essential quality check that improves model performance and reduces downstream risks, similar to how security analysis is now integrated into development rather than treated as optional.
FAQ 2: Addressing Representation Issues With Limited Data Access
Q: What approaches can I use when working with datasets where I cannot modify the underlying representation choices or access additional data to address identified gaps?
A: When constrained by fixed datasets, focus on transparency, modeling choices, and careful interpretation. First, document the identified representation limitations and their potential impacts on model performance across groups, making these constraints explicit to stakeholders. Second, implement modeling approaches that account for known representational biases, such as reweighting techniques, fairness constraints, or specialized architectures that are robust to specific representation issues. Third, develop appropriate confidence intervals or uncertainty metrics that reflect data quality differences across groups. Finally, design decision processes that incorporate these limitations—for instance, by implementing higher manual review thresholds for predictions affecting underrepresented groups or adjusting decision thresholds to account for known representation disparities.
6. Summary and Next Steps
Key Takeaways
Data representation is not a neutral technical process but rather a social practice that embeds specific historical contexts, power relations, and worldviews. The key concepts from this Unit include:
- Classification politics reveals how apparently objective categorization systems actually embed specific social and historical perspectives that can perpetuate historical inequities.
- Strategic ignorance in data collection creates systematic patterns of missing data that reflect and potentially reinforce historical power structures.
- Codification practices translate complex social categories into computational representations through processes that often flatten social complexity and embed problematic assumptions.
- Power asymmetries in data production influence which perspectives shape datasets and how different populations are represented.
These concepts directly address our guiding questions by explaining how social contexts and power structures influence data representation and by providing systematic approaches to examine the social assumptions embedded in dataset construction and categorization schemes.
Application Guidance
To apply these concepts in your practical work:
- Incorporate critical questions about data representation into your standard exploratory data analysis processes.
- Document the historical development of key classification systems used in your datasets.
- Identify and explicitly acknowledge limitations in representation, particularly for historically marginalized groups.
- Design data schemas and encoding practices that preserve social complexity rather than flattening it.
For organizations new to these considerations, start by focusing on the most critical classification systems and representation gaps in your domain, then progressively expand this analysis as organizational capacity develops.
Looking Ahead
In the next Unit, we will build on this foundation by examining ethical frameworks for fairness evaluation. You will learn how different philosophical traditions conceptualize fairness and justice, how these frameworks can be applied to AI systems, and how to navigate tensions between competing ethical perspectives.
The social context insights we have developed here will directly inform that ethical analysis by providing the concrete representational practices through which abstract ethical principles must be implemented. Understanding both social representation and ethical frameworks is essential for developing AI systems that are not just technically sophisticated but also socially responsible and contextually appropriate.
References
Benjamin, R. (2019). Race after technology: Abolitionist tools for the new Jim Code. Polity.
Bowker, G. C., & Star, S. L. (1999). Sorting things out: Classification and its consequences. MIT Press.
Buolamwini, J., & Gebru, T. (2018). Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the 1st Conference on Fairness, Accountability, and Transparency (pp. 77–91). https://proceedings.mlr.press/v81/buolamwini18a.html
Crenshaw, K. (1989). Demarginalizing the intersection of race and sex: A black feminist critique of antidiscrimination doctrine, feminist theory, and antiracist politics. University of Chicago Legal Forum, 1989(1), 139–167.
D'Ignazio, C., & Klein, L. F. (2020). Data feminism. MIT Press. https://data-feminism.mitpress.mit.edu/
Eubanks, V. (2018). Automating inequality: How high-tech tools profile, police, and punish the poor. St. Martin's Press.
Obermeyer, Z., Powers, B., Vogeli, C., & Mullainathan, S. (2019). Dissecting racial bias in an algorithm used to manage the health of populations. Science, 366(6464), 447–453. https://doi.org/10.1126/science.aax2342
Roberts, S. T. (2019). Behind the screen: Content moderation in the shadows of social media. Yale University Press.
Unit 3
Unit 3: Ethical Frameworks for Fairness Evaluation
1. Conceptual Foundation and Relevance
Guiding Questions
- Question 1: How do different philosophical traditions conceptualize fairness and justice in ways that inform our approach to AI systems?
- Question 2: How can we navigate competing ethical frameworks when making concrete decisions about fairness in algorithmic systems?
Conceptual Context
The ethical evaluation of AI fairness requires moving beyond purely technical metrics to engage with fundamental questions about what "fairness" actually means. While computational approaches can quantify certain notions of equality, they cannot by themselves tell us which conception of fairness is most appropriate for a given context. Different cultures, philosophical traditions, and stakeholder groups may hold distinct—and sometimes conflicting—views about what constitutes a fair outcome or a just process.
This normative foundation is crucial because technical implementations of fairness inevitably operationalize specific ethical perspectives. When a data scientist chooses to optimize for demographic parity versus equal opportunity, they are not making a purely technical decision, but rather prioritizing one conception of fairness (equality of outcomes) over another (equality of opportunity for similarly qualified individuals). Without explicit engagement with the ethical frameworks underlying these choices, fairness interventions risk implementing value systems that may be misaligned with the intended application context or stakeholder expectations.
This Unit builds directly on the historical patterns of discrimination explored in Units 1 and 2 by providing frameworks for evaluating these patterns from multiple ethical perspectives. It establishes the normative foundation necessary for selecting appropriate fairness definitions in Part 2 and prioritizing bias sources in Part 3. For the Historical Context Assessment Tool we will develop in Unit 5, understanding these ethical frameworks will help you evaluate the severity and relevance of historical patterns across different contexts, ensuring your assessments incorporate diverse perspectives on fairness rather than defaulting to a single normative framework.
2. Key Concepts
Consequentialist Frameworks for Fairness
Consequentialist frameworks evaluate the fairness of AI systems based on their outcomes or consequences rather than on the processes that produced them. This approach is central to AI fairness because it focuses attention on the actual impacts algorithmic systems have on people's lives, beyond their technical design or the intentions of their creators.
Within consequentialism, various perspectives offer distinct approaches to fairness. Utilitarianism—widely influential in technology policy—emphasizes maximizing overall welfare or utility across a population. In contrast, prioritarianism gives extra weight to the welfare of the worst-off groups, and egalitarianism focuses on equalizing outcomes across different groups regardless of potential efficiency losses.
Research by Mullainathan (2018) demonstrates how these distinctions matter in practice. A medical resource allocation algorithm optimized for utilitarian efficiency might maximize overall health outcomes but potentially exacerbate existing health disparities by directing resources away from already-disadvantaged populations. Conversely, a prioritarian approach might accept some reduction in aggregate efficacy to ensure benefits reach those with the greatest needs (Mullainathan, 2018).
These consequentialist perspectives directly inform different mathematical fairness definitions. Demographic parity (equalizing prediction rates across groups) operationalizes an egalitarian perspective focused on equality of outcomes. In contrast, a utility-maximizing approach might accept some disparities in outcomes if they increase overall system accuracy.
The Historical Context Assessment Tool must incorporate these consequentialist perspectives when evaluating the impacts of historical discrimination patterns. By assessing historical harms through multiple consequentialist lenses, you can identify which fairness definitions best address the specific patterns relevant to your application domain.
Deontological Approaches to Algorithmic Justice
Deontological ethical frameworks focus on the inherent rightness or wrongness of actions themselves, regardless of their consequences. These approaches evaluate fairness based on whether AI systems adhere to certain moral duties, rights, or rules. This perspective is crucial for AI fairness because it establishes boundaries that should not be crossed even when doing so might improve aggregate outcomes.
Kantian ethics, with its emphasis on human dignity and treating people as ends rather than merely means, provides one influential deontological perspective. Rawlsian justice theories, with their focus on procedural fairness from behind a "veil of ignorance," offer another approach that has significantly influenced fairness discussions in AI ethics.
As Wong (2020) argues, deontological frameworks lead to distinctly different fairness interventions than consequentialist approaches. Rather than focusing solely on equalizing error rates or outcomes, a deontological approach might prioritize informed consent, transparency about system limitations, or ensuring that algorithmic decisions can be meaningfully contested by affected individuals (Wong, 2020).
These deontological perspectives directly inform procedural fairness considerations in AI systems. Individual fairness definitions, which ensure similar individuals receive similar treatment regardless of group membership, reflect deontological concerns about treating each person in accordance with relevant characteristics rather than arbitrary group classifications.
The Historical Context Assessment Tool must incorporate these deontological frameworks to evaluate not just the consequences of historical discrimination patterns, but also the procedural injustices that enabled them. This perspective helps identify when fairness interventions should focus on procedural reforms rather than merely outcome adjustments.
Virtue Ethics and Character-Centered Approaches
Virtue ethics shifts focus from rules or outcomes to the character traits and values embodied in the development and deployment of AI systems. This perspective evaluates fairness based on whether AI systems reflect virtues like justice, impartiality, and compassion. Virtue ethics is particularly valuable for AI fairness because it addresses the intentions and professional ethics of those designing and deploying algorithmic systems.
Mittelstadt (2019) argues that virtues like epistemic humility (acknowledging the limits of algorithmic knowledge), justice (ensuring benefits and burdens are distributed fairly), and transparency (making system limitations clear to stakeholders) provide a framework for evaluating AI systems that complements rule-based or outcome-focused approaches. This perspective recognizes that technical systems encode not just algorithms but values and worldviews (Mittelstadt, 2019).
Virtue ethics connects directly to practices like responsible AI development, which emphasizes continuous learning, stakeholder engagement, and a commitment to addressing harms as they emerge. Rather than viewing fairness as a technical property to be optimized, virtue ethics frames it as an ongoing practice of responsible development.
For the Historical Context Assessment Tool, virtue ethics provides a framework for evaluating the institutional practices and professional values that shaped historical technologies. This perspective helps identify when fairness interventions should address organizational cultures and professional practices rather than focusing narrowly on technical implementations.
Non-Western Ethical Traditions and Global Fairness
Fairness conceptions vary significantly across cultural traditions, with non-Western ethical frameworks offering important perspectives often neglected in dominant AI ethics discussions. This cross-cultural dimension is essential for AI fairness because algorithmic systems increasingly operate across global contexts where Western ethical assumptions may not align with local values and priorities.
Research by Wong and Khanna (2022) demonstrates how principles like Ubuntu (emphasizing communal harmony and interdependence), Confucian ethics (focusing on relational propriety and social harmony), and Indigenous value systems (emphasizing relationships with land and community) offer distinctive perspectives on what constitutes fair algorithmic treatment. These traditions often emphasize collective welfare and relational harmony in ways that challenge the individualistic assumptions underlying many Western fairness frameworks (Wong & Khanna, 2022).
Sambasivan et al. (2021) further illustrate these differences in their study of fairness perspectives in India, where conceptions of algorithmic justice are shaped by colonial histories, caste considerations, and communal relations that differ significantly from Western contexts. Their work demonstrates that fairness interventions designed without attention to local ethical traditions may miss critical dimensions of justice relevant to affected communities (Sambasivan et al., 2021).
For the Historical Context Assessment Tool, incorporating these diverse ethical traditions is essential for evaluating historical patterns across global contexts. This perspective helps identify when fairness interventions should be adapted to different cultural contexts rather than assuming universal applicability of specific fairness definitions.
Domain Modeling Perspective
From a domain modeling perspective, ethical frameworks map to specific components of ML systems:
- Problem Formulation: Ethical frameworks shape how problems are defined and what objectives are prioritized.
- Data Collection: Ethical perspectives influence decisions about representation, consent, and measurement.
- Model Development: Different frameworks suggest distinct approaches to balancing competing values during optimization.
- Evaluation: Ethical traditions inform which metrics are prioritized and how trade-offs are navigated.
- Deployment: Ethical considerations guide decisions about transparency, explainability, and stakeholder engagement.
This domain mapping helps you understand how ethical frameworks influence specific technical decisions throughout the ML lifecycle rather than viewing ethics as a separate consideration. The Historical Context Assessment Tool will incorporate this mapping to help practitioners identify how ethical perspectives shape technical implementations across different system components.

Conceptual Clarification
To clarify these abstract ethical frameworks, consider the following analogies:
- Consequentialist frameworks function like public health policies that might restrict individual freedoms (like quarantine measures) to maximize overall population health. Similarly, consequentialist approaches to AI fairness might accept trade-offs that limit some benefits for privileged groups if doing so significantly improves outcomes for disadvantaged groups. The focus remains on measurable results rather than the processes that produced them.
- Deontological frameworks operate like constitutional rights that cannot be overridden even for significant social benefit. Just as freedom of speech protects expression even when unpopular, deontological approaches to AI fairness establish certain principles (like informed consent or proportionality) that must be respected regardless of their impact on model performance or aggregate outcomes.
- Virtue ethics resembles professional codes of conduct that focus on developing practitioner character rather than prescribing specific actions for every situation. Like medical ethics that emphasize virtues such as compassion and integrity alongside technical skills, virtue ethics in AI fairness cultivates dispositions like epistemic humility and justice that guide decision-making across diverse contexts.
Intersectionality Consideration
Ethical frameworks must be adapted to address the complex interactions between multiple forms of discrimination that occur at demographic intersections. Many traditional ethical approaches have treated people as members of single identity categories, failing to account for how multiple forms of marginalization create unique ethical considerations at their intersection.
Crenshaw's (1989) foundational work on intersectionality demonstrated that discrimination against Black women cannot be understood by separately examining either racism or sexism, but requires analyzing how these forms of oppression interact to create distinct experiences. This intersectional analysis reveals ethical considerations invisible to single-axis frameworks (Crenshaw, 1989).
For AI systems, this means ethical evaluations must consider how fairness interventions affect multiply-marginalized groups specifically, not just demographic categories in isolation. For example, a hiring algorithm that appears fair when evaluated separately for gender and race might still systematically disadvantage women of color in ways that single-attribute analyses would miss.
The Historical Context Assessment Tool must explicitly incorporate intersectional ethical analysis by:
- Examining how multiple ethical frameworks might yield different evaluations at demographic intersections;
- Ensuring historical pattern identification considers overlapping forms of discrimination rather than treating each in isolation;
- Developing evaluation approaches that prioritize impacts on the most marginalized intersectional groups rather than focusing solely on aggregate outcomes.
This intersectional perspective transforms ethical evaluation from a single-axis assessment to a multi-dimensional analysis that captures the complex reality of how discrimination operates across overlapping identity categories.
3. Practical Considerations
Implementation Framework
To systematically apply ethical frameworks to fairness evaluation, implement this structured methodology:
-
Multi-framework Analysis:
-
Analyze fairness questions through at least three distinct ethical lenses (e.g., consequentialist, deontological, and virtue ethics).
- Document how different frameworks would evaluate key decisions about data collection, feature selection, and optimization objectives.
-
Identify areas where frameworks agree and where they suggest different approaches.
-
Stakeholder-Centered Ethical Mapping:
-
Identify which ethical frameworks most closely align with different stakeholder groups' priorities and values.
- Map potential conflicts between stakeholder ethical perspectives.
-
Document how these different ethical perspectives might evaluate system outcomes differently.
-
Contextual Adaptation:
-
Analyze how application domain and cultural context should influence which ethical frameworks receive priority.
- Consider historical patterns of discrimination in the domain and which ethical frameworks best address these patterns.
-
Document domain-specific ethical considerations that standard frameworks might miss.
-
Trade-off Documentation:
-
Create explicit documentation of ethical trade-offs when different frameworks suggest conflicting approaches.
- Develop clear rationales for prioritizing certain ethical considerations over others in specific contexts.
- Establish processes for revisiting these trade-offs when conditions change.
This methodological framework integrates with standard ML workflows by extending requirements gathering, evaluation planning, and documentation processes to explicitly incorporate ethical dimensions. While adding complexity, this structured approach reduces the risk of implementing fairness interventions that conflict with stakeholder values or neglect critical ethical considerations.
Implementation Challenges
When implementing ethical frameworks for fairness evaluation, practitioners commonly face these challenges:
-
Value Pluralism and Ethical Disagreement: Stakeholders often hold genuinely different ethical perspectives, making it difficult to establish consensus on fairness priorities. Address this by:
-
Documenting different ethical perspectives rather than assuming consensus.
- Creating decision processes that acknowledge legitimate ethical disagreement.
-
Developing approaches for navigating trade-offs that respect different ethical commitments.
-
Communicating Ethical Concepts to Technical Teams: Technical practitioners may struggle to connect abstract ethical frameworks to concrete implementation decisions. Address this by:
-
Translating ethical principles into specific technical requirements.
- Using concrete examples that demonstrate how ethical frameworks inform technical choices.
- Developing shared vocabulary that bridges ethical and technical domains.
Successfully implementing ethical frameworks requires resources including time for stakeholder engagement, expertise in both ethical theory and technical implementation, and organizational commitment to navigating complex value trade-offs. Most importantly, it requires willingness to engage with normative questions rather than treating fairness as a purely technical problem.
Evaluation Approach
To assess whether your ethical framework implementation is effective, apply these evaluation strategies:
-
Perspectival Completeness Assessment:
-
Evaluate whether multiple ethical perspectives have been considered, including both dominant and marginalized viewpoints.
- Verify that both Western and non-Western ethical traditions inform the analysis.
-
Check that intersectional perspectives are explicitly included rather than treating identity categories in isolation.
-
Documentation Quality Evaluation:
-
Assess whether ethical considerations are clearly documented in ways accessible to both technical and non-technical stakeholders.
- Verify that ethical trade-offs are explicitly acknowledged rather than hidden.
-
Check that the rationale for ethical priorities is clearly articulated.
-
Stakeholder Alignment Verification:
-
Evaluate whether the prioritized ethical frameworks align with values important to affected communities.
- Verify that marginalized stakeholders' ethical perspectives are genuinely incorporated, not just consulted.
- Check that the evaluation approach can adapt to different cultural contexts and application domains.
These evaluation approaches should be integrated into your organization's broader AI governance framework, ensuring that ethical considerations are assessed with the same rigor as technical or business requirements.
4. Case Study: Medical Resource Allocation Algorithm
Scenario Context
A major healthcare system is developing an algorithm to prioritize patients for specialized care programs with limited capacity. The system will analyze patient data—including medical history, socioeconomic factors, predicted health trajectories, and healthcare utilization patterns—to identify patients who would benefit most from enrollment. The algorithm will directly influence which patients receive enhanced care management, making fairness considerations particularly critical.
Key stakeholders include clinicians concerned with improving patient outcomes, administrators focused on resource efficiency, patients with complex health needs, patient advocacy organizations, and regulatory bodies overseeing healthcare equity. The fairness challenge lies in defining what constitutes a "fair" allocation when demand exceeds capacity, and when historical health disparities have created unequal baseline conditions across demographic groups.
Problem Analysis
Applying ethical frameworks reveals distinct perspectives on what fairness means in this context:
From a utilitarian consequentialist perspective, fairness might mean maximizing the total health improvement across all patients, which could prioritize those most likely to respond positively to interventions. However, research by Obermeyer et al. (2019) revealed that this approach can inadvertently discriminate against Black patients when using healthcare costs as a proxy for health needs, as historically Black patients have received less care for the same level of need.
From a Rawlsian justice perspective, fairness would require designing the system from behind a "veil of ignorance," prioritizing the welfare of the worst-off patients. This might lead to allocating more resources to historically underserved populations to compensate for past inequities, even if this doesn't maximize total health improvements in the short term.
From a virtue ethics standpoint, the system should embody virtues like compassion, justice, and epistemic humility—acknowledging the limitations of algorithmic prediction and ensuring human oversight particularly for edge cases or when predictions might perpetuate existing disparities.
An Indigenous value systems perspective might emphasize communal aspects of health and well-being beyond individual medical metrics, considering family and community impacts of health interventions and prioritizing holistic approaches to care.
Intersectional analysis reveals that discrimination patterns in healthcare differ significantly at demographic intersections. For example, Black women face unique barriers to care that differ from challenges faced by either white women or Black men, requiring specific consideration rather than assuming that addressing either gender or racial disparities separately would be sufficient.
Solution Implementation
To navigate these complex ethical considerations, the team implemented a structured approach for ethical fairness evaluation:
- They began with a multi-framework ethical analysis that explicitly documented how different ethical perspectives would evaluate the allocation system. This analysis revealed that while a pure utility-maximizing approach would optimize for expected health improvements, a Rawlsian perspective highlighted the need to address historical access disparities that affected baseline health status.
- They conducted stakeholder-centered ethical mapping through community workshops and clinical focus groups. This process revealed that patients and community advocates prioritized equitable access across demographic groups, while clinicians emphasized individual clinical appropriateness, and administrators focused on maximizing aggregate health improvements.
- For contextual adaptation, they examined historical discrimination patterns in healthcare delivery specific to their region. This analysis identified particularly severe historical disparities in chronic disease management for specific demographic groups, suggesting these areas required particular attention.
- They created explicit trade-off documentation acknowledging that perfect alignment between ethical frameworks was impossible. For example, they documented the tension between maximizing short-term health improvements and addressing long-term health equity, ultimately deciding to implement a blended approach that incorporated both considerations with greater weight given to equity for the most severely underserved populations.
The team operationalized these ethical insights by:
- Developing distinct fairness metrics aligned with different ethical frameworks
- Creating a dashboard that showed allocation patterns across both demographic categories and intersectional groups
- Implementing a review process for cases where ethical frameworks suggested conflicting approaches
- Documenting the ethical rationale for algorithm design decisions alongside technical specifications
Outcomes and Lessons
The ethical framework implementation resulted in several important outcomes:
- The algorithm achieved a more balanced distribution of resources across demographic groups than the previous manual system, while still maintaining strong health improvement outcomes.
- When deployed, the system received higher acceptance from community stakeholders who appreciated the explicit engagement with equity considerations.
- The documented ethical trade-offs provided valuable context for clinicians who maintained oversight of algorithmic recommendations.
Key challenges remained, including tension between standardized health metrics and culturally-specific health conceptions, and difficulty in quantifying historical disparities to inform "fair" allocations.
The most generalizable lessons included:
- The importance of moving beyond single-framework ethical analysis to incorporate multiple perspectives on fairness.
- The value of explicit documentation of ethical trade-offs, which enhanced transparency and trust even when perfect solutions were impossible.
- The necessity of adapting ethical frameworks to specific healthcare contexts rather than applying generic fairness definitions.
These insights directly inform the Historical Context Assessment Tool by demonstrating how ethical frameworks can help evaluate the severity and relevance of historical discrimination patterns in healthcare, guiding which patterns require particular attention in contemporary applications.
5. Frequently Asked Questions
FAQ 1: Navigating Competing Ethical Frameworks
Q: When different ethical frameworks suggest conflicting approaches to fairness in an AI system, how should I determine which framework to prioritize?
A: Rather than viewing ethical frameworks as mutually exclusive, approach them as complementary perspectives highlighting different dimensions of fairness. First, make the conflict explicit by documenting how each framework evaluates the situation differently. Then, consider contextual factors including: the specific application domain and its historical patterns of discrimination; the values and priorities of affected communities, particularly those historically marginalized; and the specific harms at stake. Document your reasoning process transparently, acknowledging that perfect resolution may be impossible. In many cases, a blended approach that incorporates elements from multiple frameworks while giving priority to addressing the most severe historical injustices provides the most robust solution. The key is not to default to a single framework across all contexts, but to develop contextually appropriate ethical reasoning that respects diverse perspectives while prioritizing the welfare of those most vulnerable to algorithmic harm.
FAQ 2: Ethical Frameworks and Technical Implementations
Q: How do abstract ethical frameworks translate into specific technical choices when implementing fairness in machine learning systems?
A: Ethical frameworks directly inform technical implementations by shaping how fairness is operationalized mathematically. Consequentialist frameworks like utilitarianism typically align with group fairness metrics that focus on outcome distributions, such as demographic parity (when equality of outcomes is prioritized) or equalized odds (when equality of error rates is central). Deontological approaches often manifest in individual fairness metrics that ensure similar individuals receive similar treatment regardless of group membership, implementing the principle that people should be treated according to relevant characteristics rather than arbitrary groups. Virtue ethics might emphasize explainability and transparency mechanisms that enable practitioners to demonstrate appropriate care and responsibility. When implementing fairness technically, begin by explicitly identifying which ethical frameworks inform your definition of fairness, then select metrics and constraints that operationalize those specific principles. This approach transforms ethics from abstract philosophy to concrete technical specifications, ensuring that your system's mathematical properties align with your intended ethical commitments.
6. Summary and Next Steps
Key Takeaways
This Unit has examined how diverse ethical frameworks provide essential perspectives for evaluating fairness in AI systems. We've explored how consequentialist approaches focus on outcomes and impacts across demographic groups; deontological frameworks emphasize rights, duties, and procedural fairness; virtue ethics addresses the character and values embodied in AI development; and diverse cultural traditions offer perspectives often neglected in dominant AI ethics discussions.
These ethical frameworks directly address our guiding questions by demonstrating how different philosophical traditions conceptualize fairness in ways that inform technical implementation, and by providing structured approaches for navigating competing ethical perspectives when making concrete fairness decisions. Rather than positioning any single framework as universally correct, we've emphasized the importance of multi-perspective analysis that incorporates diverse ethical viewpoints.
These ethical foundations are critical for the Historical Context Assessment Tool we're developing, as they provide frameworks for evaluating the severity and relevance of historical patterns of discrimination across different contexts. By incorporating multiple ethical perspectives, the tool will enable more nuanced assessment of which historical patterns require particular attention in contemporary AI applications.
Application Guidance
To apply these ethical frameworks in your practical work:
- Start by explicitly identifying which ethical frameworks inform your understanding of fairness rather than treating your perspective as universal or assuming consensus among stakeholders.
- Incorporate multiple ethical perspectives in your fairness evaluations, documenting how different frameworks might assess the same situation differently.
- Pay particular attention to the values and perspectives of historically marginalized communities, especially at demographic intersections where unique ethical considerations may emerge.
- Create clear documentation of ethical trade-offs and the rationale for prioritizing certain considerations over others in specific contexts.
For organizations new to ethical fairness evaluation, begin with a simple analysis comparing utilitarian (outcome-focused) and rights-based (process-focused) perspectives on your specific application. Even this basic multi-perspective approach can reveal important dimensions of fairness that a single framework might miss.
Looking Ahead
In the next Unit, we will build on these ethical foundations by examining how historical patterns of discrimination manifest in contemporary AI systems. You will learn to identify specific mechanisms through which historical biases appear in modern algorithms, applying the ethical frameworks developed in this Unit to evaluate their impacts and prioritize intervention approaches.
The ethical frameworks you have explored here will directly inform this analysis by providing multiple lenses through which to evaluate the significance of observed bias patterns. Rather than relying on technical metrics alone, you will be able to assess these patterns through diverse ethical perspectives, creating a more comprehensive understanding of their implications for different stakeholders and contexts.
References
Crenshaw, K. (1989). Demarginalizing the intersection of race and sex: A black feminist critique of antidiscrimination doctrine, feminist theory, and antiracist politics. University of Chicago Legal Forum, 1989(1), 139–167. https://chicagounbound.uchicago.edu/uclf/vol1989/iss1/8/
Mittelstadt, B. (2019). Principles alone cannot guarantee ethical AI. Nature Machine Intelligence, 1(11), 501–507. https://doi.org/10.1038/s42256-019-0114-4
Mullainathan, S. (2018). Algorithmic fairness and the social welfare function. In Proceedings of the 2018 ACM Conference on Economics and Computation (EC '18). ACM, New York, NY, USA, 1–1.
Obermeyer, Z., Powers, B., Vogeli, C., & Mullainathan, S. (2019). Dissecting racial bias in an algorithm used to manage the health of populations. Science, 366(6464), 447–453. https://doi.org/10.1126/science.aax2342
Sambasivan, N., Arnesen, E., Hutchinson, B., Doshi, T., & Prabhakaran, V. (2021). Re-imagining algorithmic fairness in India and beyond. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT '21). Association for Computing Machinery, New York, NY, USA, 315–328. https://doi.org/10.1145/3442188.3445896
Wong, P. H. (2020). Democratizing algorithmic fairness. Philosophy & Technology, 33(2), 225–244. https://doi.org/10.1007/s13347-019-00355-w
Wong, P. H., & Khanna, T. (2022). Value sensitive design and the global south: A multi-cultural approach to fairness in AI. Computers and Society, 51(1), 173–190.
Unit 4
Unit 4: Modern Manifestations of Historical Biases
1. Conceptual Foundation and Relevance
Guiding Questions
- Question 1: How do historical patterns of discrimination manifest in contemporary AI systems despite advances in technical capabilities and increased awareness of fairness issues?
- Question 2: What specific technical mechanisms translate historical biases into algorithmic contexts, and how can practitioners identify these mechanisms before they cause harm?
Conceptual Context
Understanding how historical biases manifest in modern AI systems is essential for effective fairness work because these manifestations often appear as seemingly technical issues rather than obvious continuations of historical discrimination. The technical complexity of modern machine learning can obscure how these systems reproduce and sometimes amplify historical patterns of inequality, making systematic analysis vital.
This Unit bridges historical understanding and technical implementation by tracing concrete pathways through which historical biases become encoded in contemporary systems. While previous Units established the theoretical foundations of historical bias and data representation politics, this Unit demonstrates how these abstract concepts materialize in specific AI applications across domains including criminal justice, healthcare, hiring, lending, and content recommendation.
Building directly on the historical patterns examined in Unit 1, the data representation issues from Unit 2, and the ethical frameworks from Unit 3, this Unit provides the crucial case studies that will inform the Historical Context Assessment Tool you'll develop in Unit 5. By analyzing real-world examples of bias manifestation, you'll develop the pattern recognition capabilities necessary to identify potential fairness issues before they emerge in your own systems.
2. Key Concepts
Technical Instantiation of Historical Bias
Historical biases become instantiated in contemporary AI systems through specific technical mechanisms that transform abstract social patterns into concrete computational outcomes. This concept is fundamental to AI fairness because it bridges historical analysis and technical implementation, helping practitioners identify exactly how and where historical patterns manifest in modern systems.
Technical instantiation connects to other fairness concepts by providing concrete examples of how historical patterns (Unit 1) materialize through specific data representations (Unit 2), raising ethical questions about responsibility and intervention (Unit 3). This concept transforms abstract historical understanding into actionable technical insights by demonstrating exactly how discrimination becomes encoded in algorithms.
Research by Obermeyer et al. (2019) provides a striking example in their analysis of a widely-used healthcare algorithm that dramatically underestimated the medical needs of Black patients. The algorithm used healthcare costs as a proxy for health needs, but due to historical patterns of unequal healthcare access and utilization, Black patients had systematically lower healthcare costs than white patients with the same medical conditions. The algorithm thus inherited this historical disparity, encoding it as a seemingly neutral optimization for cost prediction (Obermeyer et al., 2019).
For criminal justice, Angwin et al. (2016) demonstrated how risk assessment algorithms used in pretrial decisions reflected historical patterns of over-policing in minority neighborhoods. By training on historical arrest data shaped by discriminatory policing practices, these algorithms learned to associate ZIP codes and other demographic proxies with higher risk, potentially perpetuating the very disparities they were built upon (Angwin et al., 2016).
For the Historical Context Assessment Tool you'll develop in Unit 5, understanding technical instantiation provides a crucial framework for identifying how specific historical patterns might manifest in particular AI applications, helping predict and prevent potential fairness issues before implementation.
Proxy Discrimination Mechanisms
Proxy discrimination occurs when algorithms utilize seemingly neutral features that correlate with protected attributes to make decisions that disproportionately impact certain demographic groups. This mechanism is central to AI fairness because it enables discriminatory outcomes even when protected attributes are explicitly excluded from the model, creating fairness challenges that superficial approaches often miss.
Proxy discrimination interacts with other fairness concepts by demonstrating how representation issues (Unit 2) create concrete pathways for historical biases (Unit 1) to manifest in modern systems, raising complex ethical questions (Unit 3) about how to address features that have legitimate predictive value but also serve as demographic proxies.
Research by Barocas and Selbst (2016) illustrates how location data such as ZIP codes can serve as proxies for race in predictive models due to historical residential segregation patterns. Models using location to predict outcomes like loan repayment or insurance risk may reproduce historical redlining patterns without explicitly considering race. Similarly, variables like education and employment history can function as gender proxies due to historical occupational segregation (Barocas & Selbst, 2016).
In natural language processing, Bolukbasi et al. (2016) demonstrated how word embeddings trained on historical texts encoded gender biases present in those texts, with problematic analogies like "man is to computer programmer as woman is to homemaker" emerging from the embedding space. These embeddings, when used in downstream applications like resume screening, could perpetuate historical gender disparities in employment (Bolukbasi et al., 2016).
For the Historical Context Assessment Tool, understanding proxy discrimination mechanisms enables practitioners to systematically identify potential proxy variables based on historical patterns, ensuring that fairness assessments extend beyond obvious direct discrimination to capture more subtle indirect pathways.
Feedback Loop Amplification
Feedback loops in AI systems can amplify initially small biases into significant disparities over time through self-reinforcing cycles that strengthen historical patterns. This amplification mechanism is critical to AI fairness because it explains how systems can create increasing harm even when initial bias is relatively minor, highlighting the importance of early intervention.
Feedback amplification connects to other fairness concepts by showing how historical patterns (Unit 1) and data representation issues (Unit 2) can intensify through system dynamics, raising ethical questions (Unit 3) about responsibility for emergent properties that weren't explicitly designed but arise through deployment.
Ensign et al. (2018) provide a clear example in their analysis of predictive policing systems, where initial data reflecting historical bias in policing patterns leads to increased police presence in already over-policed neighborhoods. This increased presence naturally results in more arrests, which are then fed back into the system as new training data, creating a self-reinforcing cycle that intensifies the original disparity. They term this the "runaway feedback loop" problem in predictive policing (Ensign et al., 2018).
Similarly, recommendation systems can create filter bubbles that intensify existing patterns of information segregation. As analyzed by Noble (2018) in "Algorithms of Oppression," search engines can reinforce stereotypical associations through their ranking algorithms, prioritizing results that align with historical stereotypes and thus further cementing those associations (Noble, 2018).
For the Historical Context Assessment Tool, understanding feedback amplification enables practitioners to identify high-risk applications where historical patterns might not just persist but actually intensify over time, highlighting domains where proactive intervention is particularly crucial.
Domain-Specific Manifestation Patterns
Historical biases manifest differently across application domains, with distinct technical mechanisms and outcomes in areas like criminal justice, healthcare, hiring, and finance. This domain specificity is essential to AI fairness because it requires tailored analysis approaches rather than generic assessments that might miss domain-specific risk factors.
Domain-specific manifestation connects to other fairness concepts by showing how general historical patterns (Unit 1) and data representation issues (Unit 2) take particular forms in specific contexts, requiring contextualized ethical frameworks (Unit 3) rather than one-size-fits-all approaches.
In healthcare, Ferryman and Pitcan (2018) document how AI systems can reproduce historical healthcare disparities through mechanisms specific to medical data, including unrepresentative clinical trials, biased diagnostic criteria, and differential access to care that shapes what conditions are diagnosed and recorded. These domain-specific factors create unique pathways for historical bias to manifest in healthcare AI (Ferryman & Pitcan, 2018).
In facial recognition, Buolamwini and Gebru's (2018) landmark "Gender Shades" study revealed significant accuracy disparities across skin tone and gender, with particularly poor performance for darker-skinned women. These disparities reflected domain-specific issues including historical underrepresentation in computer vision datasets, technical challenges in imaging darker skin tones, and benchmark evaluation practices that didn't adequately assess intersectional performance (Buolamwini & Gebru, 2018).
For the Historical Context Assessment Tool, understanding domain-specific manifestation patterns enables the development of targeted assessment approaches that address the particular mechanisms through which historical bias manifests in different application areas, enhancing the tool's effectiveness across diverse contexts.
Domain Modeling Perspective
From a domain modeling perspective, modern manifestations of historical bias map to specific components of ML systems:
- Problem Formulation: How the definition of the problem itself may embed historical assumptions about what outcomes matter and how success is defined.
- Data Sources: How the selection of training data sources may reproduce historical patterns of who is represented and how.
- Feature Engineering: How variable creation and transformation choices may embed historical categorization systems or measurement practices.
- Model Architecture: How algorithm selection and design decisions may be more or less robust to certain types of historical bias.
- Evaluation Framework: How testing procedures and metrics may fail to capture performance disparities across demographic groups.
- Deployment Context: How system integration and user interaction patterns may create new manifestations of historical bias.
This domain mapping helps practitioners systematically examine how historical biases might manifest across the entire ML pipeline rather than focusing narrowly on data representation alone. The Historical Context Assessment Tool will leverage this mapping to create structured analysis approaches for each pipeline component.
Conceptual Clarification
To clarify these abstract concepts, consider the following analogies:
- Technical instantiation of historical bias resembles how architectural designs reflect their historical context. Just as buildings from different eras incorporate the social assumptions, technological capabilities, and aesthetic preferences of their time, AI systems encode the data practices, social categories, and measurement approaches of their historical moment. This encoding isn't usually intentional—it emerges naturally from using historically situated data and practices to build contemporary systems.
- Proxy discrimination mechanisms function like water finding its way through a dam's cracks. Even when we explicitly block protected attributes (the main channel), related variables (small cracks) can still carry the same information through the system. Just as water pressure eventually widens small cracks, algorithmic optimization progressively identifies and exploits these correlations, potentially creating significant disparities through initially subtle pathways.
- Feedback loop amplification operates like compound interest in financial systems. Small initial disparities that seem insignificant can grow exponentially over time through the power of compounding. Similarly, when AI systems influence the environments they measure (like predictive policing influencing where arrests occur), small initial biases can compound into significant disparities through successive cycles of prediction and data collection.
Intersectionality Consideration
Modern manifestations of historical bias often appear most acutely at the intersections of multiple marginalized identities, creating unique patterns that single-attribute analyses would miss. As Buolamwini and Gebru (2018) demonstrated in their "Gender Shades" research, facial recognition systems showed dramatically worse performance for darker-skinned women compared to both darker-skinned men and lighter-skinned women, revealing intersectional effects that would remain invisible if examining either race or gender in isolation.
Similarly, Kearns et al. (2018) found that fairness metrics evaluated on aggregate groups (e.g., across all women or all racial minorities) could mask significant discrimination against specific intersectional subgroups. Their work on "subgroup fairness" demonstrated mathematically how fairness guarantees for broad groups don't necessarily extend to their intersections, creating potential blind spots in fairness assessment (Kearns et al., 2018).
The Historical Context Assessment Tool must explicitly incorporate intersectionality by:
- Examining historical patterns that specifically affected intersectional groups rather than treating discrimination patterns as uniform across protected attributes.
- Identifying unique technical mechanisms through which these intersectional patterns might manifest in contemporary systems.
- Creating assessment approaches that explicitly examine system performance at demographic intersections rather than only measuring along single attributes.
By centering intersectionality, the tool will capture fairness issues that might otherwise remain invisible, ensuring more comprehensive and effective fairness assessment.
3. Practical Considerations
Implementation Framework
To systematically analyze how historical biases manifest in modern AI systems, follow this structured methodology:
-
Map Historical Patterns to Technical Mechanisms
-
Identify relevant historical discrimination patterns for your application domain.
- Document specific technical mechanisms through which these patterns might manifest in modern systems.
-
Analyze which components of your ML pipeline are most vulnerable to these specific patterns.
-
Conduct Proxy Variable Analysis
-
Examine your feature set for variables that might correlate with protected attributes.
- Quantify these correlations using techniques like mutual information or prediction tasks.
-
Document which historical patterns these proxy relationships might reflect.
-
Perform Feedback Loop Assessment
-
Identify whether your system's predictions will influence future data collection.
- Trace potential cycles where initial bias might amplify over time.
-
Develop monitoring approaches to detect emerging feedback patterns.
-
Implement Domain-Specific Analysis
-
Apply specialized assessment techniques relevant to your application domain.
- Reference case studies from similar domains to identify common manifestation patterns.
- Adapt general fairness approaches to address domain-specific mechanisms.
These methodologies should integrate with standard ML workflows by extending exploratory data analysis to include historical pattern mapping, incorporating proxy analysis into feature selection, and adding feedback loop assessment to system design reviews.
Implementation Challenges
When analyzing modern manifestations of historical bias, practitioners commonly face these challenges:
-
Limited Historical Knowledge: Many data scientists lack deep understanding of historical discrimination patterns relevant to their domain. Address this by:
-
Collaborating with domain experts who understand historical context.
- Reviewing literature on historical discrimination in relevant fields.
-
Creating accessible summaries of key historical patterns for technical teams.
-
Technical-Historical Connection: Practitioners often struggle to connect abstract historical patterns to specific technical mechanisms. Address this by:
-
Developing clear taxonomies that map historical patterns to technical instantiations.
- Creating case study libraries that document established connections.
- Implementing structured analysis templates that guide the connection process.
Successful implementation requires resources including:
- Access to relevant historical scholarship and domain expertise.
- Computational tools for proxy variable detection and correlation analysis.
- Frameworks for simulation and analysis of potential feedback dynamics.
- Documentation templates for recording identified manifestation patterns.
Evaluation Approach
To assess whether your analysis of modern manifestations is effective, apply these evaluation strategies:
-
Pattern Coverage Assessment
-
Verify that you've examined relevant historical patterns across multiple domains.
- Confirm that analysis addresses both obvious and subtle manifestation mechanisms.
-
Ensure assessment covers all relevant components of the ML pipeline.
-
Technical Mechanism Validation
-
Test whether identified mechanisms actually produce bias in your specific context.
- Implement simulation approaches to verify causal connections between historical patterns and observed disparities.
-
Document the strength of evidence for each identified manifestation pathway.
-
Intersectional Verification
-
Check that analysis examines outcomes across demographic intersections, not just main groups.
- Verify that assessment approaches can detect intersectional effects despite data sparsity challenges.
- Ensure documentation explicitly addresses unique patterns at demographic intersections.
These evaluation approaches should be integrated with your broader system assessment framework, providing structured validation of whether you've effectively identified how historical patterns might manifest in your specific application.
4. Case Study: Automated Hiring Systems
Scenario Context
A large technology company is implementing an AI-powered resume screening system to efficiently evaluate thousands of job applicants. The system analyzes resumes to predict which candidates are most likely to succeed based on historical hiring and performance data from the past decade.
The ML task involves text classification and ranking, with the business objective of increasing hiring efficiency while maintaining or improving the quality of candidates who receive interviews. Key stakeholders include the HR department seeking efficiency, hiring managers concerned about candidate quality, executive leadership focusing on diversity goals, and applicants who want fair consideration.
The fairness challenge in this context is particularly significant because historical hiring data likely reflects industry-wide patterns of gender and racial disparities in technology roles, potentially creating a system that perpetuates or amplifies these disparities while appearing objective and data-driven.
Problem Analysis
Applying the Unit's core concepts to this scenario reveals several critical fairness concerns:
- Technical Instantiation of Historical Bias: The technology industry has well-documented historical gender and racial disparities, with women and minorities historically underrepresented in technical roles. This historical pattern becomes technically instantiated when the model is trained on past hiring decisions that reflected these disparities. The system might learn to associate characteristics more common in resumes from historically advantaged groups (certain universities, technical terms, extracurricular activities) with positive outcomes, effectively encoding historical preferences as prediction rules.
- Proxy Discrimination Mechanisms: Even if the system explicitly excludes protected attributes like gender and race, numerous proxy variables in resume data correlate with these attributes. Universities attended may correlate with race due to historical segregation patterns in higher education. Participation in certain activities may correlate with gender (e.g., women's sports teams, fraternity leadership). Even subtle language patterns differ across demographic groups, as demonstrated by Gaucher et al. (2011), who found that job descriptions with masculine-coded language discouraged female applicants.
- Feedback Loop Amplification: If implemented without intervention, the system could create a self-reinforcing cycle. Initial model bias leads to hiring more candidates from historically advantaged groups, whose subsequent performance data reinforces the original pattern, progressively narrowing the definition of "success" to characteristics associated with the dominant group.
From an intersectional perspective, the historical patterns in technology hiring have created particularly significant barriers for women of color, who face compounded disadvantages. The automated screening system might create especially severe disparities for these candidates, as the historical data would contain very few examples of successful candidates with these intersectional identities.
Solution Implementation
To address these identified fairness concerns, the company implements a structured approach:
- For Technical Instantiation: The team conducts a comprehensive audit of historical hiring patterns, identifying specific success indicators that might reflect historical bias rather than job-relevant skills. They modify the problem formulation to focus on concrete performance metrics rather than subjective evaluations that might encode historical preferences. They also implement balanced training approaches that adjust for historical underrepresentation.
- For Proxy Discrimination: The team conducts statistical analysis to identify resume features that correlate with protected attributes. They find that certain university affiliations, activity descriptions, and language patterns serve as strong demographic proxies. Rather than removing these features entirely, they implement a fairness-aware feature engineering approach that preserves job-relevant information while reducing demographic correlation.
- For Feedback Loops: The team designs a monitoring system that tracks demographic patterns in system recommendations over time, with automatic alerts if disparities increase across successive hiring cycles. They also implement a mixed-decision approach where the system's recommendations are combined with randomized selection for a portion of candidates, ensuring diversity in the feedback data.
- For Intersectionality: The team implements specific monitoring for candidates at demographic intersections, with heightened scrutiny of system performance for groups like women of color in technical roles. They design targeted validation approaches that assess system performance across multiple demographic dimensions simultaneously despite data sparsity challenges.
Throughout implementation, the team applies domain-specific knowledge of hiring practices in technology, referencing research on effective predictors of job performance versus predictors that merely correlate with dominant group membership.
Outcomes and Lessons
The implementation results in significant improvements compared to the original design:
- The system's recommendations show substantially smaller demographic disparities while maintaining or improving the quality of candidates receiving interviews.
- Ongoing monitoring reveals that intersectional disparities remain a challenge but have decreased from the original design.
- The explicit focus on historical patterns enables more effective communication with stakeholders about why certain design decisions were necessary.
Key challenges remained, including difficulties in distinguishing job-relevant features from demographic proxies and the need for continuous monitoring as industry demographics evolve.
The most generalizable lessons included:
- The importance of examining historical patterns specific to the application domain rather than applying generic fairness approaches.
- The value of explicitly tracing how historical patterns might manifest through specific technical mechanisms rather than treating bias as a black-box property.
- The need for monitoring approaches that can detect emerging feedback loops before they create significant disparities.
- The crucial importance of intersectional analysis rather than single-attribute assessment.
These insights directly inform the Historical Context Assessment Tool by demonstrating how structured historical analysis can identify specific technical mechanisms through which bias might manifest, enabling more targeted and effective interventions.
5. Frequently Asked Questions
FAQ 1: Distinguishing Historical Bias From Modern Technical Issues
Q: How can I determine whether observed disparities in my AI system reflect historical bias rather than technical issues like data quality or algorithmic limitations?
A: This distinction requires systematic analysis rather than intuition. First, examine whether the disparity pattern aligns with known historical discrimination in your domain—if your facial recognition system performs worse on darker skin tones, this aligns with historical patterns of underrepresentation in visual datasets. Second, test whether the disparity persists across different technical implementations—if changing algorithms or hyperparameters doesn't resolve the issue, historical patterns are likely involved. Third, analyze performance on counterfactual examples where historical factors are controlled—if generating synthetic data without historical patterns eliminates the disparity, this confirms the historical connection. Remember that technical issues and historical bias often interact; poor data quality for certain groups frequently reflects historical patterns of who was deemed worth measuring accurately. The key is establishing whether addressing purely technical factors resolves the disparity or whether the root cause lies in historical patterns embedded in your data or problem formulation.
FAQ 2: Addressing Historical Bias Without Complete Historical Knowledge
Q: My team lacks deep historical knowledge about discrimination patterns relevant to our application. How can we effectively identify potential manifestations of historical bias without becoming historical experts?
A: While deep historical expertise is valuable, you can implement a structured approach that systematically identifies potential issues even with limited historical knowledge. First, consult existing research on fairness issues in similar applications, as patterns often recur across systems in the same domain. Second, implement comprehensive demographic disaggregation in your testing, examining performance across all available demographic dimensions and their intersections—disparities often reveal historical patterns even when you don't initially recognize their origins. Third, conduct stakeholder consultations with individuals from potentially affected groups who can identify concerns your team might miss. Fourth, implement dynamic monitoring that tracks performance across demographic groups over time, which can detect emerging disparities regardless of their historical origins. While these approaches don't replace historical expertise, they create systematic safeguards that help identify potential issues even without complete historical context, which you can then further investigate as needed.
6. Summary and Next Steps
Key Takeaways
This Unit has examined how historical patterns of discrimination manifest in contemporary AI systems through specific technical mechanisms. Key concepts include:
- Technical instantiation of historical bias - the concrete pathways through which historical patterns become encoded in modern algorithms, from problem formulation through deployment.
- Proxy discrimination mechanisms - how seemingly neutral variables can serve as proxies for protected attributes due to historical correlations, enabling discrimination even when protected attributes are explicitly excluded.
- Feedback loop amplification - how initially small biases can intensify over time through self-reinforcing cycles where system predictions influence future data collection.
- Domain-specific manifestation patterns - how historical biases take different forms across application domains, requiring tailored analysis approaches.
These concepts directly address our guiding questions by demonstrating how historical biases persist in modern systems despite technical advances and by identifying specific mechanisms that translate historical patterns into algorithmic contexts.
Application Guidance
To apply these concepts in your practical work:
- When developing new AI systems, systematically map relevant historical discrimination patterns to potential technical manifestations in your specific application.
- Conduct proxy variable analysis on your feature set, quantifying correlations between features and protected attributes to identify potential indirect discrimination pathways.
- Analyze whether your system creates feedback loops where predictions influence future data, and implement monitoring approaches to detect emerging patterns.
- Adapt your fairness assessment approaches to the specific manifestation patterns common in your application domain rather than applying generic methods.
For organizations new to these considerations, start with comprehensive demographic disaggregation in your testing—examining performance across all available demographic dimensions and their intersections—as this often reveals manifestation patterns even without deep historical knowledge.
Looking Ahead
In the next Unit, you will develop the Historical Context Assessment Tool that systematically incorporates the insights from all previous Units. You will create structured methodologies for identifying relevant historical patterns, mapping them to specific AI application risks, and developing targeted assessment approaches.
The analysis of modern manifestations you've learned in this Unit provides essential case studies that will inform the tool's development. By understanding how historical patterns have manifested in existing systems, you'll be better equipped to predict and prevent similar issues in new applications.
References
Angwin, J., Larson, J., Mattu, S., & Kirchner, L. (2016). Machine bias. ProPublica. Retrieved from https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
Barocas, S., & Selbst, A. D. (2016). Big data's disparate impact. California Law Review, 104(3), 671–732. https://doi.org/10.15779/Z38BG31
Bolukbasi, T., Chang, K.-W., Zou, J. Y., Saligrama, V., & Kalai, A. T. (2016). Man is to computer programmer as woman is to homemaker? Debiasing word embeddings. In Advances in Neural Information Processing Systems (pp. 4349–4357).
Buolamwini, J., & Gebru, T. (2018). Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the 1st Conference on Fairness, Accountability, and Transparency (pp. 77–91). https://proceedings.mlr.press/v81/buolamwini18a.html
Ensign, D., Friedler, S. A., Neville, S., Scheidegger, C., & Venkatasubramanian, S. (2018). Runaway feedback loops in predictive policing. In Proceedings of the 1st Conference on Fairness, Accountability and Transparency (pp. 160–171).
Ferryman, K., & Pitcan, M. (2018). Fairness in precision medicine. Data & Society. Retrieved from https://datasociety.net/library/fairness-in-precision-medicine/
Gaucher, D., Friesen, J., & Kay, A. C. (2011). Evidence that gendered wording in job advertisements exists and sustains gender inequality. Journal of Personality and Social Psychology, 101(1), 109–128. https://doi.org/10.1037/a0022530
Kearns, M., Neel, S., Roth, A., & Wu, Z. S. (2018). Preventing fairness gerrymandering: Auditing and learning for subgroup fairness. In Proceedings of the 35th International Conference on Machine Learning (pp. 2564–2572).
Noble, S. U. (2018). Algorithms of oppression: How search engines reinforce racism. NYU Press.
Obermeyer, Z., Powers, B., Vogeli, C., & Mullainathan, S. (2019). Dissecting racial bias in an algorithm used to manage the health of populations. Science, 366(6464), 447–453. https://doi.org/10.1126/science.aax2342
Unit 5
Unit 5: Historical Context Assessment Tool
1. Introduction
In Part 1, you learned about the historical and societal foundations of AI fairness. You examined how patterns of discrimination persist across technological transitions, how social contexts shape data representation, and how technologies can reinforce existing social hierarchies. You also explored concrete case studies of how historical biases manifest in modern AI systems. Now it's time to apply these insights by developing a practical tool that helps engineering teams identify relevant historical patterns and connect them to specific AI risks. The Historical Context Assessment Tool you'll create will serve as the first component of the Sprint 1 Project - Fairness Audit Playbook, ensuring that fairness assessments address root causes rather than merely symptoms of bias.
2. Context
Imagine you are a staff engineer at a tech company that uses AI systems across multiple products. You've been approached by an engineering team scoping an AI-powered internal loan application system. This system will allow platform users to purchase products and pay for them in installments. The team recognizes the sensitivity of this feature and has requested your help.
After initial discussions with the team, you've determined that understanding the historical context of discrimination is essential for designing and implementing further fairness evaluations and interventions. You've agreed to develop a tool that will help the team conduct a sufficient historical analysis that follows best scientific fairness practices. You'll also prepare a short case study demonstrating how to use your tool for the internal loan application system the team is developing.
You've realized that their challenge represents a broader opportunity: developing a tool that all teams can use to assess historical discrimination patterns relevant to their AI applications. You've named it the "Historical Context Assessment Tool."
In most companies, the first step in any new project is checking whether someone has already tackled a similar one. Fortunately, a former colleague completed a closely related project, and you can use their work as a reference (see the Sample Solution section below).
3. Objectives
By completing this project component, you will practice:
- Translating historical discrimination concepts into a practical assessment methodology for engineering teams.
- Mapping specific historical patterns to concrete AI system risks.
- Communicating complex societal and historical issues to technical audiences.
- Balancing analytical depth with practical usability in business environments.
4. Requirements
Your Historical Context Assessment Tool must include:
- A structured questionnaire for identifying relevant historical discrimination patterns.
- A risk classification matrix that categorizes the uncovered historical patterns by severity, likelihood, and relevance to guide prioritization during development.
- User documentation that guides users on how to use the Historical Context Assessment Tool in practice.
- A case study demonstrating the tool's application to an internal loan application system.
5. Sample Solution
The following solution was developed by a former colleague who was working on a related problem and can serve as an example for your own work. Note that this solution wasn't specifically designed for AI applications and lacks some key components that your assessment tool should include.
5.1 Historical Context Assessment Questionnaire
Section 1: Domain and Application Context
- Application Domain Identification. What specific domain will this system operate in (e.g., lending, hiring, healthcare, criminal justice)? What function will it serve within this domain?
- Historical Discrimination Patterns. What documented patterns of discrimination exist in this domain? Consider both explicit policies (e.g., redlining in housing) and implicit practices.
Section 2: Data and Representation Analysis
- Historical Data Sources. What historical data sources will inform this system? How were these datasets collected, and what historical contexts shaped their collection?
- Categorical Formation. How have relevant categories (e.g., race, gender, creditworthiness) been defined historically in this domain? How have these definitions changed over time?
- Measurement Approaches. How have key variables historically been measured in this domain? Might these measurements encode historical biases?
Section 3: Technology Transition Patterns
- Previous Technological Systems. What previous technological systems have served similar functions in this domain? How did these systems perpetuate or challenge existing inequities?
- Technological Amplification. How might an automated system potentially amplify existing historical biases compared to previous systems? What new capabilities introduce additional risks?
5.2 Historical Context Risk Classification Matrix
Matrix Components
- Historical Pattern: Specific documented pattern of discrimination with historical evidence.
-
Severity: Impact of this bias if perpetuated (High/Medium/Low):
-
High: Directly impacts fundamental rights or life outcomes.
- Medium: Creates significant disparities in opportunities or resources.
-
Low: Creates differential experiences but with limited material impact.
-
Likelihood: Probability of this pattern manifesting in AI systems:
-
High: Pattern frequently appears in similar systems.
- Medium: Pattern occasionally appears in similar systems.
-
Low: Pattern rarely appears in similar systems.
-
Relevance: Applicability to the specific AI system being developed:
-
High: Direct applicability to system's domain/purpose.
- Medium: Partial applicability to certain system components.
-
Low: Limited applicability but potential for manifestation.
-
Priority Score: Calculated as Severity × Likelihood × Relevance:
-
7-9: Critical priority - Requires immediate mitigation.
- 5-6: High priority - Requires mitigation if the launch is successful.
- 3-4: Medium priority - Requires monitoring after successful launch.
- 1-2: Low priority - No action needed.
Historical Pattern Risk Classification Matrix Example
| Historical Pattern | Severity | Likelihood | Relevance | Priority Score |
|---|---|---|---|---|
| Redlining practices in financial services | High (3) | High (3) | High (3) - Housing/lending algorithms | 9 - Critical |
| Gender bias in professional evaluations | High (3) | Medium (2) | Medium (2) - HR/recruitment systems | 7 - High |
| Racial disparities in medical diagnosis | High (3) | Medium (2) | Low (1) - General recommendation systems | 6 - Medium |
| Age discrimination in advertising | Medium (2) | High (3) | Low (1) - Content recommendation | 6 - Medium |
| Linguistic bias against non-native speakers | Medium (2) | Medium (2) | Low (1) - General NLP systems | 5 - Medium |
| Religious discrimination in social services | Medium (2) | Low (1) | Low (1) - General recommendation systems | 4 - Low |
5.3 Usage Guide
Implementation Process
Step 1: Domain Research (1-2 hours)
- Gather historical information specific to your application domain.
- Focus on documented patterns of discrimination and their mechanisms.
- Review relevant academic literature, legal cases, and domain-specific resources.
Step 2: Questionnaire Completion (1-2 hours)
- Assemble a diverse team including domain experts and stakeholders.
- Work through the questionnaire sections sequentially.
- Document answers with specific examples and sources where possible.
- For questions without clear answers, note information gaps for further research.
Step 3: Risk Classification (30-60 minutes)
- Use the risk classification matrix to categorize identified historical patterns.
- For each risk, document:
- Specific historical pattern
- System components affected
- Potential impact severity
- Likelihood based on system design
- Priority level for intervention
Step 4: Documentation and Integration (1-2 hours)
- Compile findings into a structured historical context assessment document.
- Highlight critical and high-priority risks that require immediate attention.
- Create actionable recommendations for subsequent design and development phases.
- Feed results into fairness definition selection process.
