Sprint 2: Technical Approaches to Fairness
Introduction
How do you translate fairness principles into concrete interventions within machine learning systems? This Sprint tackles this critical challenge. Without systematic bias mitigation approaches, fairness remains conceptual rather than operational.
This Sprint builds directly on Sprint 1's Fairness Audit Playbook. You now move from identifying bias to eliminating it. Think of Sprint 1 as diagnosis and Sprint 2 as treatment. First you located the problem; now you'll fix it. The Sprint Project adopts a domain-driven approach, working backwards from our desired outcome—a practical framework for selecting and implementing fairness interventions.
By the end of this Sprint, you will:
- Analyze causal mechanisms of bias by mapping relationships between protected attributes, features, and outcomes.
- Design pre-processing interventions by transforming, reweighting, and resampling your data.
- Implement fairness-aware modeling by incorporating constraints, adversarial techniques, and regularization.
- Apply post-processing techniques by optimizing thresholds and calibrating outputs.
- Create integrated intervention strategies by combining techniques across the ML pipeline.
Sprint Project Overview
Project Description
In this Sprint, you will develop a Fairness Intervention Playbook—a decision-making methodology for selecting, configuring, and evaluating technical fairness interventions. This playbook transforms diagnosis into treatment, connecting issues identified in your Fairness Audit Playbook to specific technical solutions.
The Fairness Intervention Playbook helps you select optimal intervention points, match techniques to specific bias patterns, and integrate multiple approaches. Rather than prescribing universal solutions, it guides you through systematic selection based on your fairness definitions, bias sources, and technical constraints. Consider it your fairness treatment plan—a customized approach to addressing the specific issues you've diagnosed.
Project Structure
The project builds across five Parts, with each Part's Unit 5 developing a critical component:
- Part 1: Causal Fairness Toolkit—identifies intervention points through causal analysis.
- Part 2: Pre-Processing Fairness Toolkit—provides data-level interventions targeting representation issues.
- Part 3: In-Processing Fairness Toolkit—integrates fairness directly into model training.
- Part 4: Post-Processing Fairness Toolkit—adjusts model outputs after training.
- Part 5: Fairness Intervention Playbook—synthesizes these components into a cohesive methodology.
Each component builds on the previous ones. Causal analysis reveals where intervention will be most effective. This guides your selection of data, model, or output interventions. All components combine through a pipeline integration strategy in Part 5 that creates coordinated, multi-stage fairness solutions.
Key Questions and Topics
How do we translate conceptual fairness definitions into effective technical interventions?
Fairness definitions must transform into implementable techniques to create real impact. Different definitions require distinct approaches—demographic parity demands different interventions than equal opportunity. The Causal Fairness Toolkit connects abstract definitions to specific causal pathways requiring intervention. The Fairness Intervention Playbook then maps these pathways to appropriate technical solutions. Your choice of intervention shapes who receives loans, housing, or employment opportunities.
Where in the machine learning pipeline should we intervene for maximum impact?
Intervention points span from data preparation through model training to prediction adjustment. Some biases demand data transformation while others require model constraints. The optimal intervention depends on causal understanding—addressing symptoms without targeting causes often fails or creates new problems. The Causal Fairness Toolkit helps you identify whether unfairness stems from data representation, learning algorithms, or decision rules, directing your efforts to the root cause rather than surface manifestations.
What technical approaches best address different types of bias?
Technical interventions fall into three categories: pre-processing (reweighting, transformation), in-processing (constraint optimization, adversarial debiasing), and post-processing (threshold optimization, calibration). Each approach suits different bias patterns and constraints. The Pre-Processing, In-Processing, and Post-Processing Toolkits match techniques to contexts based on empirical effectiveness and theoretical guarantees. This targeted approach replaces the common one-size-fits-all implementations that often fail in practice.
How do we balance fairness improvements against performance trade-offs?
Fairness improvements often require compromises. The interventions frequently decrease accuracy or hurt calibration. The Intervention Playbook's evaluation framework helps you assess trade-offs across fairness metrics, predictive performance, and business objectives. This explicit assessment replaces the common implicit assumption that fairness automatically hurts performance, helping you find the optimal balance for your specific context.
Part Overviews
Part 1: Causal Approaches to Fairness examines how causal understanding transforms fairness work. You will analyze unfairness mechanisms, distinguish legitimate predictive relationships from problematic patterns, and develop counterfactual frameworks. This Part culminates in the Causal Fairness Toolkit—a methodology for mapping causal paths between protected attributes and outcomes, identifying optimal intervention points based on causal structure rather than correlations.
Part 2: Data-Level Interventions (Pre-processing) explores addressing bias before model training. You will examine reweighting techniques that adjust sample importance, transformation methods that reduce problematic correlations, and generative approaches that augment underrepresented groups. The Pre-Processing Fairness Toolkit provides decision frameworks for selecting and configuring data-level interventions based on specific bias patterns, helping you fix issues at their source.
Part 3: Model-Level Interventions (In-processing) investigates embedding fairness directly into model training. You will develop constraint optimization techniques, adversarial approaches, and regularization methods. The In-Processing Fairness Toolkit guides selection and implementation of algorithm-level fairness, adapting approaches to different model architectures and training paradigms to create fair learning processes.
Part 4: Prediction-Level Interventions (Post-processing) focuses on adjusting model outputs. You will learn threshold optimization for different fairness criteria, calibration for consistent prediction interpretation, and rejection learning for uncertain predictions. The Post-Processing Fairness Toolkit provides strategies for adjusting predictions without retraining, offering solutions for deployed models where retraining proves impractical or costly.
Part 5: Fairness Intervention Playbook synthesizes previous components into a cohesive methodology. You will integrate pipeline intervention strategies, develop evaluation frameworks, create case studies, and address practical deployment considerations. The complete Fairness Intervention Playbook enables systematic selection and implementation of technical fairness solutions across the ML lifecycle, connecting diagnosis to effective treatment through a principled decision-making process.
Part 1: Causal Approaches to Fairness
Context
Causality transforms fairness work by revealing bias mechanisms that correlational approaches miss.
This Part establishes the foundation for effective bias mitigation. You'll learn to identify root causes of unfairness rather than treating surface symptoms that mislead interventions.
Protected attributes connect to outcomes through multiple causal pathways. Gender might affect loan approvals directly (explicit bias) or indirectly through income differences (structural bias). A credit algorithm showing gender disparities demands causal analysis: Does gender directly influence decisions? Do proxy variables encode discrimination? Or do legitimate risk factors happen to correlate with gender? Causality distinguishes these cases.
Historical patterns embed in data, propagating past discrimination. A hiring algorithm trained on past decisions might penalize career gaps that disproportionately affect women. Causal analysis reveals these patterns, mapping how seemingly neutral variables transmit bias across generations of decisions.
Causal approaches reshape ML systems from data collection through deployment. They guide which variables to collect, how to transform features, which model architectures preserve wanted pathways while blocking unwanted ones, and how to evaluate whether interventions actually improved fairness.
The Causal Fairness Toolkit you'll develop in Unit 5 represents the first component of the Fairness Intervention Playbook. This tool will help you map bias mechanisms to optimal intervention points, ensuring you target causes rather than symptoms.
Learning Objectives
By the end of this Part, you will be able to:
- Analyze causal mechanisms of unfairness in ML systems. You will distinguish direct discrimination from proxy discrimination and spurious correlations, enabling precise diagnosis of how bias enters algorithms.
- Build causal models for algorithmic fairness scenarios. You will construct graphical models depicting relationships between protected attributes and outcomes, moving from vague fairness concerns to testable hypotheses.
- Apply counterfactual fairness principles to ML systems. You will evaluate whether predictions remain consistent in worlds where protected attributes differ, addressing individual fairness beyond group-level metrics.
- Implement practical causal inference techniques despite data limitations. You will extract causal insights from observational data without randomized experiments, addressing the reality that perfect causal knowledge rarely exists.
- Translate causal insights into targeted interventions. You will map causal structures to appropriate technical solutions, selecting interventions that address root causes rather than statistical patterns.
Units
Unit 1
Unit 1: From Correlation to Causation in Fairness
1. Conceptual Foundation and Relevance
Guiding Questions
- Question 1: Why do traditional statistical fairness metrics often fail to capture genuine discrimination, and how does causality provide a more principled foundation for fairness?
- Question 2: How can causal reasoning help us distinguish between legitimate predictive relationships and problematic patterns that perpetuate historical biases?
Conceptual Context
When working with fairness in AI systems, a fundamental limitation quickly emerges: standard statistical fairness approaches primarily focus on correlations between variables without addressing the underlying causal mechanisms that generate unfair outcomes. This distinction between correlation and causation is not merely a theoretical concern but a critical factor that determines whether your fairness interventions will effectively address the root causes of discrimination or merely treat superficial symptoms.
Consider a hiring algorithm that shows a statistical disparity against female applicants. A correlation-based approach might simply enforce equal selection rates across genders. However, without understanding the causal structure—whether gender directly influences decisions, acts through proxy variables, or shares common causes with qualifications—such interventions may be ineffective or even harmful. As Pearl (2019) notes, "behind every serious attempt to achieve fairness lies a causal model, even if it is not articulated explicitly."
This Unit establishes the foundational understanding of why causality matters for fairness, setting the stage for the more technical causal modeling approaches you'll explore in Units 2-4. By contrasting correlation-based and causal approaches to fairness, you'll develop the conceptual framework necessary to move beyond statistical parity metrics toward interventions that address the genuine causal mechanisms of unfairness. This causal perspective will directly inform the Causal Analysis Methodology you'll develop in Unit 5, enabling you to identify appropriate intervention points based on causal understanding rather than statistical associations.
2. Key Concepts
The Limitations of Correlation-Based Fairness
Traditional fairness metrics in machine learning predominantly focus on statistical correlations between protected attributes and outcomes. This approach, while computationally straightforward, fundamentally limits our ability to identify and address the true sources of discrimination in AI systems. Understanding these limitations is crucial for developing more effective fairness interventions.
Correlation-based fairness metrics like demographic parity, equal opportunity, and equalized odds implicitly treat all statistical associations between protected attributes and outcomes as problematic, without distinguishing between legitimate relationships and discriminatory patterns. This lack of nuance can lead to interventions that "break the thermometer" rather than addressing the underlying "fever" of discrimination.
This concept directly connects to causal fairness approaches by highlighting why we need to move beyond purely statistical associations to understand the generative mechanisms of unfairness. It interacts with other fairness concepts by demonstrating why enforcing statistical constraints without causal understanding can lead to suboptimal or even harmful interventions.
Several researchers have demonstrated the limitations of correlation-based approaches. Hardt et al. (2016) note that enforcing statistical parity without considering causality can harm the very groups we aim to protect by ignoring legitimate predictive differences. Kusner et al. (2017) provide concrete examples where models with identical statistical properties have fundamentally different fairness implications when analyzed through a causal lens.
For example, consider two lending scenarios with identical statistical disparities in approval rates across racial groups:
- In Scenario A, race affects educational opportunities, which legitimately influences credit risk.
- In Scenario B, race directly influences lending decisions independent of credit risk.
These scenarios have identical statistical properties but vastly different fairness implications. Correlation-based metrics cannot distinguish between them, while causal approaches can identify the specific pathways through which discrimination occurs.
For the Causal Analysis Methodology we'll develop in Unit 5, understanding these limitations is essential because it establishes why causal reasoning is necessary for meaningful fairness assessment and intervention. This understanding will guide the development of analysis approaches that look beyond statistical associations to the underlying causal mechanisms.
Causal Models of Discrimination
Causal models provide explicit representations of how discrimination operates through specific mechanisms or pathways in AI systems. This framework is essential for AI fairness because it enables us to distinguish between different types of discrimination that appear statistically identical but require different interventions.
This concept builds on the limitations of correlation-based approaches by providing an alternative framework that explicitly represents how protected attributes influence outcomes through various causal pathways. It interacts with fairness interventions by helping determine where in the ML pipeline to intervene and what type of intervention would most effectively address the specific causal mechanisms present.
Drawing on Pearl's (2009) causal framework, researchers have identified several distinct causal mechanisms of discrimination:
- Direct discrimination occurs when protected attributes directly influence decisions, represented as a direct path from the protected attribute to the outcome in a causal graph.
- Indirect discrimination happens when protected attributes influence decisions through legitimate intermediate variables (e.g., qualification measures that are causally affected by historical discrimination).
- Proxy discrimination arises when decisions depend on variables that are not causally affected by protected attributes but are statistically associated with them due to unmeasured common causes.
Kilbertus et al. (2017) formalized these concepts in their landmark paper, demonstrating how different causal structures necessitate different fairness interventions. For example, proxy discrimination might require removing problematic features, while indirect discrimination could demand more complex interventions that preserve legitimate causal pathways while removing problematic ones.
For our Causal Analysis Methodology, these causal discrimination models provide the foundational framework for identifying what type of discrimination is present in a specific application and selecting appropriate interventions based on these causal structures.
Counterfactual Reasoning for Fairness
Counterfactual reasoning provides a formal framework for asking "what if" questions that capture our intuitive understanding of fairness: would this individual have received the same decision if they belonged to a different demographic group, with all causally unrelated characteristics remaining the same? This approach is central to AI fairness because it directly addresses the core question of whether a system treats people differently based on protected attributes in a causally meaningful way.
This counterfactual perspective builds directly on causal models of discrimination by using them to define precise fairness criteria. It interacts with fairness interventions by providing a clear objective—making model predictions invariant to counterfactual changes in protected attributes along problematic pathways.
Kusner et al. (2017) formalized this approach as "counterfactual fairness," defining a prediction as counterfactually fair if it remains unchanged in counterfactual worlds where an individual's protected attribute is different but all non-descendant variables remain the same. This definition captures the intuition that individuals should not be treated differently based on protected attributes in ways that constitute discrimination.
To illustrate, consider a college admissions example where a qualified female applicant is rejected from a computer science program. Counterfactual fairness asks: would this same applicant have been rejected if they were male, holding constant all characteristics not causally dependent on gender? If the answer is no, the decision exhibits counterfactual unfairness.
The key insight from counterfactual fairness is that not all influences of protected attributes constitute discrimination. As Kusner et al. (2017) argue, only some causal pathways from protected attributes to outcomes represent unfair influence, while others may represent legitimate relationships that should be preserved.
For our Causal Analysis Methodology, counterfactual reasoning provides both a formal fairness criterion that can guide intervention selection and a framework for evaluating whether existing systems exhibit causal forms of discrimination.
Intervention Points From a Causal Perspective
Causal reasoning enables the identification of optimal intervention points throughout the ML pipeline based on understanding the specific mechanisms that generate unfairness. This concept is crucial for AI fairness because different causal structures demand different intervention strategies—interventions that work for one type of discrimination may be ineffective or harmful for others.
This intervention perspective builds on causal models and counterfactual reasoning by translating causal understanding into concrete decisions about where and how to intervene in the ML pipeline. It connects directly to the pre-processing, in-processing, and post-processing techniques you'll explore in subsequent Parts by providing a principled basis for choosing between them.
Research by Zhang and Bareinboim (2018) demonstrates how different causal structures necessitate different intervention approaches. For direct discrimination, removing protected attributes or applying constraints during model training might be appropriate. For proxy discrimination, transforming features that serve as proxies might be needed. For selection bias, addressing data collection processes could be essential.
For example, in a hiring scenario where gender affects career gaps which affect hiring decisions:
- If we determine career gaps are legitimate predictors of job performance, we might focus on addressing underlying societal factors while preserving the feature.
- If career gaps are not causally related to performance but merely associated with gender, we might remove or transform this feature.
- If career gaps sometimes matter for performance (in some jobs but not others), we might need more nuanced interventions that preserve some pathways while blocking others.
These intervention decisions cannot be made based on statistical associations alone—they require causal understanding of how different variables relate to each other and to the outcome of interest.
For our Causal Analysis Methodology, this intervention perspective will provide the bridge between causal analysis and specific intervention techniques, helping practitioners select appropriate fairness approaches based on the causal structures identified in their specific applications.
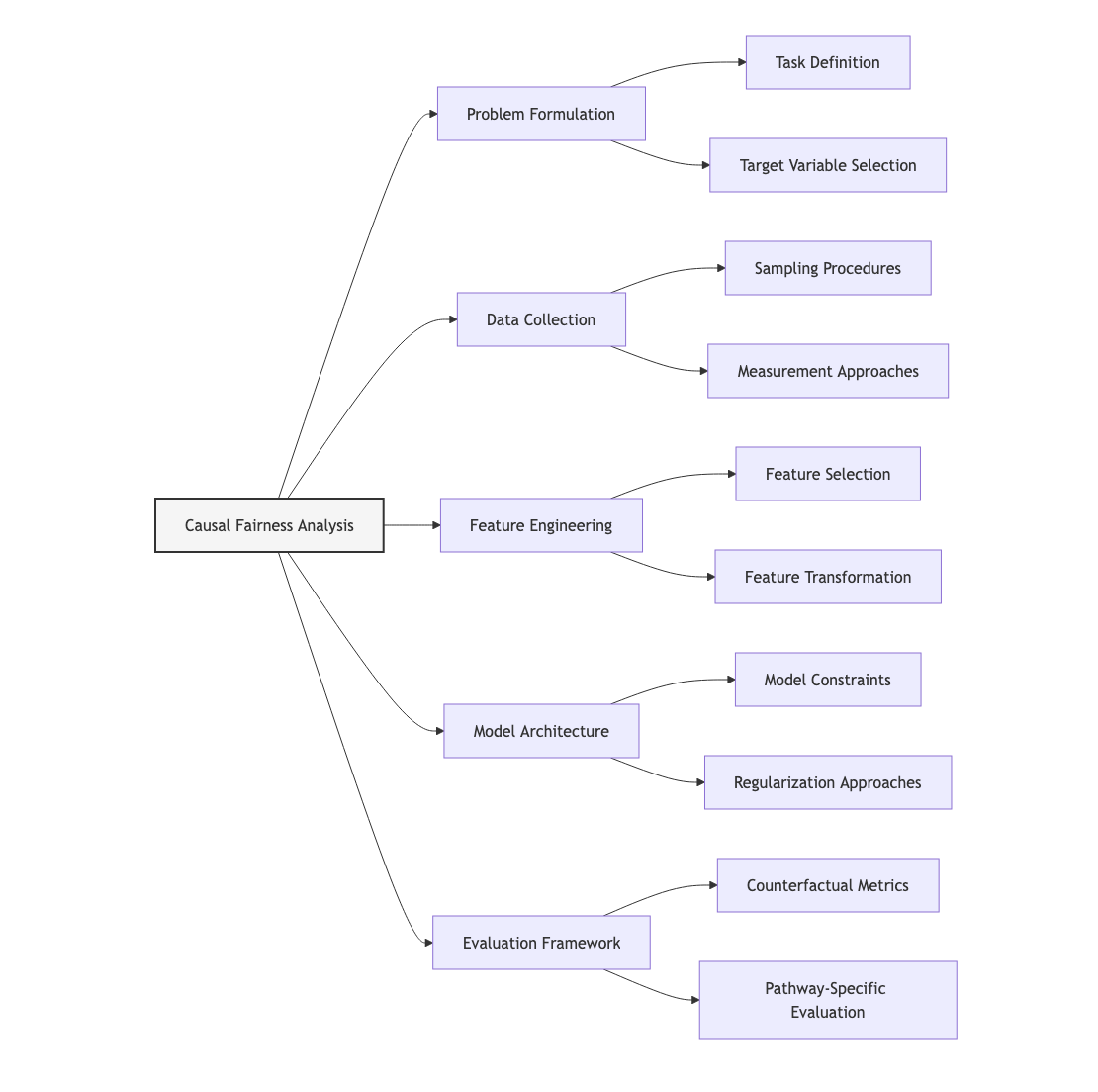
Domain Modeling Perspective
From a domain modeling perspective, causal approaches to fairness map to specific components of ML systems:
- Problem Formulation: Causal analysis reveals how the very definition of the prediction task may embed discriminatory assumptions, potentially suggesting reformulation of the problem itself.
- Data Collection: Causal understanding highlights how sampling procedures and measurement approaches may introduce biases through selection or collider effects.
- Feature Engineering: Causal models distinguish between features that serve as legitimate predictors versus problematic proxies for protected attributes.
- Model Architecture: Causal structures inform which model constraints or regularization approaches might effectively address the specific discrimination mechanisms present.
- Evaluation Framework: Counterfactual fairness provides evaluation criteria that align with causal understanding rather than purely statistical associations.
This domain mapping helps you understand how causal considerations influence different stages of the ML lifecycle rather than viewing them as abstract theoretical frameworks. The Causal Analysis Methodology you'll develop in Unit 5 will leverage this mapping to create structured approaches for identifying causal discrimination and determining appropriate interventions throughout the ML pipeline.
Conceptual Clarification
To clarify these abstract causal concepts, consider the following analogies:
- Correlation vs. causation in fairness is similar to the difference between treating symptoms versus curing a disease in medicine. A physician who only addresses symptoms (fever, pain) without understanding the underlying disease mechanism might provide temporary relief but fail to cure the patient. Similarly, fairness interventions that only address statistical disparities without understanding causal mechanisms might temporarily improve metrics but fail to address the root causes of discrimination.
- Causal models of discrimination function like architectural blueprints that reveal the internal structure of a building. Just as blueprints show which walls are load-bearing (critical) versus decorative (non-essential), causal models reveal which connections between variables represent fundamental mechanisms of discrimination versus mere correlations. This distinction matters because modifying load-bearing walls without proper support could collapse the structure, while interventions that ignore causal structure might compromise model performance or fail to address fundamental sources of bias.
- Counterfactual reasoning resembles a controlled scientific experiment where researchers change exactly one variable while keeping others constant. When scientists test a new drug, they create identical test groups and change only the treatment variable—this allows them to conclude that differences in outcomes are caused by the treatment rather than other factors. Similarly, counterfactual fairness examines what would happen if only a person's protected attribute changed while everything causally independent remained constant, isolating whether protected attributes unfairly influence decisions.
- Intervention points from a causal perspective can be compared to water quality management for a city. Water quality issues can arise at different points—contamination at the source, problems in the treatment plant, or issues in the distribution network. Each requires different interventions: watershed protection at the source, chemical treatment at the plant, or pipe replacement in the distribution system. Similarly, fairness issues can originate at different points in the ML pipeline—data collection, feature engineering, or model training—each requiring different intervention strategies.
Intersectionality Consideration
Causal approaches to fairness must explicitly address how multiple protected attributes interact to create unique causal mechanisms that affect individuals with overlapping marginalized identities. Traditional causal models often examine protected attributes in isolation, potentially missing critical intersectional effects where multiple attributes combine to create distinct causal pathways.
As Crenshaw (1989) established in her foundational work on intersectionality, discrimination often operates differently at the intersections of multiple marginalized identities, creating unique challenges that single-attribute analyses miss. For AI systems, this means causal fairness approaches must examine how multiple protected attributes jointly influence outcomes through various causal pathways.
Recent work by Yang et al. (2020) demonstrates how causal modeling can be extended to capture intersectional effects by explicitly representing interaction terms in structural equations and examining path-specific effects across demographic intersections. Their approach enables more nuanced analysis of how multiple attributes jointly influence outcomes through various causal pathways.
For instance, a recommendation algorithm for academic opportunities might exhibit a unique causal pattern of discrimination against Black women that differs from patterns affecting either Black men or white women. Standard causal models examining race and gender separately would miss this intersectional effect, while an intersectional causal approach would reveal the specific pathways through which this discrimination operates.
For our Causal Analysis Methodology, addressing intersectionality requires:
- Explicitly modeling interactions between protected attributes in causal graphs.
- Examining counterfactual fairness across demographic intersections rather than for single attributes in isolation.
- Identifying causal pathways that specifically affect intersectional groups.
- Designing intervention strategies that address the unique causal mechanisms operating at demographic intersections.
By incorporating these intersectional considerations, our methodology will enable more comprehensive causal analysis that captures the complex ways in which multiple forms of discrimination interact rather than treating protected attributes as independent factors.
3. Practical Considerations
Implementation Framework
To effectively apply causal reasoning to fairness in practice, follow this structured methodology:
-
Discrimination Mechanism Identification:
-
Examine potential direct discrimination paths: Does the protected attribute directly influence decisions?
- Analyze indirect discrimination through mediators: Do protected attributes affect legitimate intermediate factors?
- Investigate proxy discrimination: Do decisions depend on variables that correlate with protected attributes due to unmeasured common causes?
-
Document potential discrimination mechanisms with accompanying evidence and reasoning.
-
Causal Fairness Criteria Selection:
-
Determine whether the application calls for group-level or individual-level causal fairness.
- Select appropriate counterfactual fairness definitions based on application context and stakeholder requirements.
- Identify which causal pathways should be considered fair versus unfair based on domain knowledge and ethical principles.
-
Document fairness criteria selection and justification, including ethical reasoning.
-
Preliminary Causal Analysis:
-
Draw on domain expertise to sketch initial causal graphs representing relationships between protected attributes, features, and outcomes.
- Identify potential confounders and mediators in these relationships.
- Formulate testable implications of these causal structures.
- Document assumptions and uncertainties in the causal model.
These methodologies integrate with standard ML workflows by informing initial problem formulation, data collection strategies, feature engineering decisions, and modeling approaches before technical implementation begins. While they add complexity to the development process, they establish a more solid foundation for effective fairness interventions.
Implementation Challenges
When applying causal reasoning to fairness, practitioners commonly face these challenges:
-
Limited Causal Knowledge: Most applications lack perfect understanding of the true causal structures. Address this by:
-
Starting with multiple plausible causal models based on domain expertise.
- Performing sensitivity analysis to determine how conclusions change under different causal assumptions.
- Adopting an iterative approach that refines causal understanding over time based on observed outcomes.
-
Being transparent about causal assumptions and their limitations.
-
Tension Between Causal Fairness and Model Performance: Eliminating problematic causal pathways may reduce predictive accuracy. Address this by:
-
Making explicit the trade-offs between different objectives.
- Exploring interventions that specifically target problematic pathways while preserving legitimate predictive relationships.
- Communicating performance implications to stakeholders and establishing acceptable trade-off thresholds.
- Considering whether the prediction task itself needs reframing if fairness and performance seem fundamentally at odds.
Successfully implementing causal fairness approaches requires resources including domain expertise to inform causal models, stakeholder engagement to establish which causal pathways are considered fair versus unfair, and organizational willingness to potentially sacrifice some predictive performance for improved fairness properties.
Evaluation Approach
To assess whether your causal fairness analysis is effective, implement these evaluation strategies:
-
Causal Assumption Validation:
-
Test implied conditional independencies in your causal model against observed data.
- Perform sensitivity analysis to determine how robust your conclusions are to variations in causal assumptions.
- Seek expert review of causal models to validate their plausibility from domain perspectives.
-
Document the evidence supporting key causal relationships in your model.
-
Counterfactual Fairness Assessment:
-
Evaluate whether predictions remain consistent under counterfactual changes to protected attributes.
- Measure the magnitude of counterfactual unfairness when present.
- Assess counterfactual fairness across different demographic subgroups and intersections.
- Compare counterfactual fairness with traditional statistical fairness metrics to identify discrepancies.
These evaluation approaches should be integrated with your organization's broader fairness assessment framework, providing deeper insights than purely statistical metrics while acknowledging the limitations of causal knowledge in practical applications.
4. Case Study: College Admissions Algorithm
Scenario Context
A university is developing a machine learning algorithm to help predict which applicants are likely to succeed in its computer science program, hoping to streamline the admissions process. The algorithm analyzes high school performance, standardized test scores, extracurricular activities, recommendation letters, and demographic information to predict first-year GPA and graduation likelihood.
Initial evaluation revealed concerning disparities: the algorithm recommends male applicants at significantly higher rates than female applicants with seemingly similar qualifications. The university's data science team must determine whether this disparity represents genuine discrimination and, if so, how to address it effectively.
This scenario involves multiple stakeholders with different priorities: admissions officers seeking to identify successful students, faculty concerned about maintaining academic standards, university leadership focused on diversity goals, and prospective students hoping for fair evaluation. The fairness implications are significant given the potential impact on educational opportunities and career trajectories.
Problem Analysis
Applying a causal perspective reveals several potential mechanisms behind the observed gender disparity:
- Direct Discrimination: The model might be directly using gender as a feature, creating a direct causal path from gender to admissions decisions. However, the team verified that gender was explicitly excluded from the model's features, making this explanation unlikely.
- Proxy Discrimination: Several features might serve as proxies for gender, creating indirect paths from gender to admissions decisions. For example, the model heavily weights participation in competitive programming contests, which historically have much higher male participation due to societal factors unrelated to CS aptitude. Similarly, it values certain technical hobbies that have been culturally associated with males, creating statistical associations between these activities and gender through unmeasured common causes like social expectations.
- Indirect Discrimination through Legitimate Pathways: Gender might influence certain legitimate predictors of CS success. For example, research suggests that due to stereotype threat, female students might underperform on standardized technical tests despite having equivalent underlying abilities. This creates a causal path from gender to test scores to admissions decisions that represents a form of indirect discrimination.
- Selection Bias in Training Data: The historical admissions data used to train the model reflects past discriminatory practices, creating a biased sample that doesn't represent the true relationship between qualifications and academic success across genders.
A correlation-based approach might simply enforce equal selection rates across genders, potentially admitting less-qualified applicants or rejecting qualified ones. In contrast, a causal approach would identify the specific mechanisms creating discrimination and target interventions accordingly.
From an intersectional perspective, the analysis becomes more complex. The team discovered that the disparity was particularly pronounced for women from underrepresented racial backgrounds and lower socioeconomic status, suggesting unique causal mechanisms affecting these intersections that would not be captured by examining gender alone.
Solution Implementation
To address these issues through a causal approach, the university implemented a structured analysis:
- Causal Modeling: The team collaborated with domain experts to develop a causal graph representing relationships between applicant characteristics, connecting variables like gender, socioeconomic background, educational opportunities, extracurricular activities, test performance, and predicted academic success. This model explicitly represented both legitimate predictive relationships and potentially problematic pathways.
- Counterfactual Analysis: Using this causal model, they performed counterfactual analysis asking: "Would this applicant receive the same prediction if they were a different gender, with all causally unrelated characteristics held constant?" This analysis revealed significant counterfactual unfairness, confirming that the model treated otherwise identical applicants differently based on gender.
-
Pathway Identification: Further analysis identified specific problematic pathways in the model:
-
Heavy reliance on participation in specific extracurricular activities that are culturally associated with gender
- Emphasis on recommendation letter language that differs systematically across genders due to writer biases
-
Overweighting of standardized test components where stereotype threat affects performance
-
Intervention Planning: Based on this causal understanding, the team planned targeted interventions:
-
Rather than simply enforcing demographic parity or removing gender from the dataset, they identified specific features serving as problematic proxies
- For legitimate predictors affected by gender through unfair mechanisms, they developed adjustments based on causal understanding
- They redesigned the prediction task itself to focus on variables less susceptible to discriminatory influences
This causal approach allowed the university to maintain predictive accuracy for academic success while addressing the specific mechanisms creating gender discrimination, rather than implementing crude statistical adjustments that might have undermined the algorithm's effectiveness.
Outcomes and Lessons
The causal approach yielded several key benefits compared to a purely statistical intervention:
- It preserved legitimate predictive relationships while addressing specific discriminatory pathways, maintaining model performance while improving fairness.
- It revealed unique challenges at intersections of gender, race, and socioeconomic status that would have been missed by single-attribute analysis.
- It provided an explainable foundation for fairness interventions that stakeholders could understand and accept based on causal reasoning rather than abstract statistical properties.
Key challenges included the difficulty of validating causal assumptions with limited experimental data and navigating disagreements about which causal pathways represented legitimate versus problematic influences.
The most generalizable lessons included:
- The importance of distinguishing between different causal mechanisms of discrimination rather than treating all statistical disparities as equally problematic.
- The value of counterfactual reasoning in providing an intuitive and principled definition of fairness that stakeholders could understand and support.
- The necessity of pathway-specific interventions that target problematic causal mechanisms while preserving legitimate predictive relationships.
These insights directly inform the development of the Causal Analysis Methodology in Unit 5, demonstrating how causal understanding enables more targeted and effective fairness interventions compared to purely statistical approaches.
5. Frequently Asked Questions
FAQ 1: Correlation Vs. Causation in Practice
Q: How does the distinction between correlation and causation practically impact my fairness interventions?
A: The correlation-causation distinction fundamentally changes which interventions will effectively address unfairness. Consider a lending algorithm showing racial disparities in approval rates. A correlation-based approach might enforce demographic parity by adjusting approval thresholds across races, potentially approving underqualified applicants or rejecting qualified ones. In contrast, a causal approach first identifies why the disparity exists: Is it direct discrimination? Proxy discrimination through seemingly neutral variables like zip codes? Indirect discrimination through legitimately predictive variables affected by historical inequities? Or selection bias in training data? Each causal mechanism requires different interventions: removing problematic features for proxy discrimination, collecting more representative data for selection bias, or developing more nuanced approaches for indirect discrimination. Without causal understanding, your interventions might inadvertently harm the groups you're trying to protect or create new fairness problems while addressing surface symptoms. Simply put, treating fairness as a purely statistical property is like prescribing medication without diagnosing the disease—you might temporarily relieve symptoms while failing to address the underlying condition.
FAQ 2: Causal Knowledge Requirements
Q: Do I need perfect causal knowledge to apply these approaches, and if not, how can I handle uncertainty about the true causal structure?
A: Perfect causal knowledge is rarely available in practice, but this doesn't prevent you from applying causal reasoning to fairness. Instead, adopt a systematic approach to handling causal uncertainty: First, develop multiple plausible causal models based on domain expertise, existing research, and stakeholder input rather than assuming a single "true" model. Second, perform sensitivity analysis to understand how your conclusions change under different causal assumptions—if several plausible models lead to similar intervention recommendations, you can proceed with greater confidence. Third, implement conservative interventions that address fairness issues under multiple causal scenarios rather than optimizing for a single assumed structure. Fourth, design your system for continuous learning, incorporating new evidence to refine causal understanding over time. Finally, maintain transparency about causal assumptions and their limitations in documentation and communications. This approach acknowledges uncertainty while still leveraging the considerable benefits of causal reasoning compared to purely associational approaches. Remember that even imperfect causal models often provide better guidance for fairness interventions than no causal reasoning at all.
6. Project Component Development
Component Description
In Unit 5, you will develop the preliminary causal analysis section of the Causal Analysis Methodology. This component will provide a structured approach for identifying potential causal mechanisms of discrimination and performing initial counterfactual analysis before developing formal causal models in subsequent Units.
The deliverable will take the form of an analysis template with guided questions, documentation formats, and initial causal assessment frameworks that will be expanded through the modeling techniques you'll learn in Units 2-4.
Development Steps
- Create a Discrimination Mechanism Identification Framework: Develop a structured questionnaire that guides users through identifying potential direct, indirect, and proxy discrimination mechanisms in their specific application domain. Include prompts about how protected attributes might influence decisions through various causal pathways.
- Build a Counterfactual Formulation Template: Design a template for formulating relevant counterfactual questions that assess whether prediction outcomes would change under different protected attribute values. Include guidance on documenting counterfactual scenarios and their fairness implications.
- Develop an Initial Causal Diagram Approach: Create guidelines for sketching preliminary causal diagrams representing relationships between protected attributes, features, and outcomes based on domain knowledge. Include annotation conventions for documenting assumptions, uncertainties, and potential discrimination pathways.
Integration Approach
This preliminary component will interface with other parts of the Causal Analysis Methodology by:
- Providing the initial discrimination mechanism identification that will be formalized through the causal modeling in Unit 2.
- Establishing the counterfactual questions that will be analyzed using the formal framework from Unit 3.
- Creating preliminary causal diagrams that will be refined through the inference techniques from Unit 4.
To enable successful integration, document assumptions explicitly, use consistent terminology across components, and create clear connections between the preliminary analysis and the more formal techniques that will be applied in subsequent Units.
7. Summary and Next Steps
Key Takeaways
This Unit has established the fundamental distinction between correlation-based and causal approaches to fairness. Key insights include:
- Statistical fairness metrics have inherent limitations because they operate purely on correlations without distinguishing between different mechanisms of discrimination. This limitation often leads to interventions that address symptoms rather than root causes of unfairness.
- Causal models of discrimination provide a more principled framework by explicitly representing how protected attributes influence outcomes through various pathways. This causal perspective enables us to distinguish between direct, indirect, and proxy discrimination—distinctions that are invisible to purely statistical approaches.
- Counterfactual reasoning offers an intuitive and powerful approach to fairness by asking whether predictions would change if protected attributes were different while holding causally unrelated characteristics constant. This approach captures our ethical intuitions about discrimination more effectively than statistical parity metrics.
- Intervention selection should be guided by causal understanding, with different discrimination mechanisms requiring different mitigation strategies. This targeted approach enables more effective interventions with fewer negative side effects compared to blanket statistical constraints.
These concepts directly address our guiding questions by explaining why causal reasoning provides a more principled foundation for fairness and how it helps distinguish between legitimate predictive relationships and problematic patterns that perpetuate bias.
Application Guidance
To apply these concepts in your practical work:
- Begin by questioning whether observed disparities represent genuine discrimination or legitimate predictive relationships, rather than automatically treating all statistical associations as problematic.
- Draw on domain knowledge to identify potential causal pathways through which protected attributes might influence outcomes, distinguishing between direct, indirect, and proxy discrimination.
- Formulate relevant counterfactual questions to assess whether your system would treat individuals differently based on protected attributes with all else causally equal.
- Use causal understanding to guide intervention selection, targeting the specific mechanisms creating unfairness rather than applying generic statistical constraints.
If you're new to causal reasoning, start with simple causal diagrams representing your domain knowledge about how variables relate to each other. Even basic causal sketches can provide valuable insights beyond purely correlational approaches. As your causal understanding develops, you can incorporate more sophisticated techniques.
Looking Ahead
In the next Unit, we will build on this conceptual foundation by exploring formal techniques for constructing causal models to represent discrimination mechanisms. You will learn to translate domain knowledge into explicit causal graphs and structural equations that systematically represent how bias enters and propagates through AI systems.
The conceptual understanding you've developed in this Unit will provide the foundation for these more technical modeling approaches. By understanding why causality matters for fairness, you're now prepared to learn how to construct and analyze formal causal models that can guide concrete fairness interventions.
References
Crenshaw, K. (1989). Demarginalizing the intersection of race and sex: A black feminist critique of antidiscrimination doctrine, feminist theory, and antiracist politics. University of Chicago Legal Forum, 1989(1), 139–167.
Hardt, M., Price, E., & Srebro, N. (2016). Equality of opportunity in supervised learning. In Advances in Neural Information Processing Systems (pp. 3315-3323).
Kilbertus, N., Carulla, M. R., Parascandolo, G., Hardt, M., Janzing, D., & Schölkopf, B. (2017). Avoiding discrimination through causal reasoning. In Advances in Neural Information Processing Systems (pp. 656-666).
Kusner, M. J., Loftus, J., Russell, C., & Silva, R. (2017). Counterfactual fairness. In Advances in Neural Information Processing Systems (pp. 4066-4076).
Pearl, J. (2009). Causality: Models, reasoning and inference (2nd ed.). Cambridge University Press.
Pearl, J. (2019). The seven tools of causal inference, with reflections on machine learning. Communications of the ACM, 62(3), 54-60.
Yang, K., Loftus, J. R., & Stoyanovich, J. (2020). Causal intersectionality for fair ranking. arXiv preprint arXiv:2006.08688.
Zhang, J., & Bareinboim, E. (2018). Fairness in decision-making – the causal explanation formula. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 32, No. 1).
Unit 2
Unit 2: Building Causal Models for Bias Detection
1. Conceptual Foundation and Relevance
Guiding Questions
- Question 1: How can we systematically translate domain knowledge into formal causal models that accurately represent the mechanisms through which bias enters and propagates in AI systems?
- Question 2: What practical approaches enable us to identify and validate critical causal pathways between protected attributes and outcomes that may generate unfairness in machine learning models?
Conceptual Context
Understanding the causal mechanisms that generate bias in AI systems is essential for effective intervention. While Unit 1 established why causal reasoning matters for fairness, this Unit focuses on how to construct explicit causal models that represent these mechanisms. Without formal causal representations, fairness efforts may target symptoms rather than root causes, leading to interventions that fail to address fundamental sources of bias or inadvertently create new fairness problems.
Causal models provide the structural foundation for fairness analysis by explicitly representing how protected attributes influence outcomes through various pathways. As Pearl (2009) notes, "behind every serious claim of discrimination lies a causal model, and behind every successful policy to correct discrimination lies a causal understanding that recognizes which pathways need to be altered and which are best left unaltered." When you build explicit causal models for bias detection, you transform implicit assumptions about discrimination into testable structures that can guide targeted interventions.
This Unit builds directly on the conceptual understanding of causality from Unit 1, providing you with concrete techniques for constructing causal graphs and structural equation models that represent bias mechanisms. These modeling approaches will enable you to distinguish between different types of discrimination, identify appropriate intervention points, and evaluate counterfactual scenarios in Units 3 and 4. The formal causal models you learn to build here will directly inform the Causal Analysis Methodology you'll develop in Unit 5, providing the structural foundation for detecting and addressing bias throughout the ML lifecycle.
2. Key Concepts
Causal Graph Construction
Causal graphs provide a formal representation of how variables in an AI system influence one another, enabling systematic analysis of the mechanisms through which bias enters and propagates. This concept is crucial for AI fairness because graphs make explicit the pathways through which protected attributes affect outcomes, allowing you to distinguish between legitimate predictive relationships and problematic discrimination patterns.
A causal graph is a directed acyclic graph (DAG) where nodes represent variables and edges represent direct causal relationships between them. In the fairness context, these graphs typically include protected attributes (e.g., race, gender), features used by the model, outcome variables, and potential confounders or mediators. By depicting the causal structure explicitly, these graphs enable you to identify direct discrimination (paths directly from protected attributes to outcomes), indirect discrimination (paths through mediators), and proxy discrimination (relationships through shared ancestors).
Causal graph construction interacts with the fairness definitions explored in previous Units by providing the structural foundation for counterfactual fairness analysis. These graphs directly inform which intervention approaches might be most effective by revealing where in the causal structure bias enters the system.
Pearl's causal framework provides a formal basis for constructing these graphs (Pearl, 2009), while recent work by Plečko and Bareinboim (2022) has extended this approach specifically for fairness analysis. Their research demonstrates how different graph structures correspond to different types of fairness violations and appropriate intervention strategies, providing a comprehensive framework for causal fairness analysis based on graph properties.
For example, consider a hiring algorithm where gender might influence hiring decisions. A causal graph would explicitly represent whether gender directly affects decisions (direct discrimination), influences intermediate variables like employment gaps that affect decisions (indirect discrimination), or is merely correlated with decisions through common causes like field of study (proxy discrimination). Each of these structures has different implications for what constitutes an appropriate fairness intervention.
For the Causal Analysis Methodology we'll develop in Unit 5, causal graphs provide the essential structural representation that enables systematic identification of bias sources and appropriate intervention points. By learning to construct these graphs, you'll gain the fundamental skill needed for all subsequent causal fairness analysis.
Identifying Causal Variables and Relationships
Constructing effective causal models requires systematic approaches for identifying relevant variables and determining the causal relationships between them. This concept is essential for AI fairness because the variables you include in your model and the relationships you specify directly determine which bias mechanisms the model can represent and which remain invisible.
This variable and relationship identification builds on causal graph construction by providing concrete methodologies for populating those graphs with appropriate nodes and edges. It interacts with the fairness definitions from previous Units by determining which pathways of influence can be represented and analyzed in your causal model.
The process involves several key steps: identifying protected attributes relevant to your fairness concerns; determining outcome variables that represent decision points where fairness matters; specifying mediators through which protected attributes might influence outcomes; and including confounders that affect both protected attributes and outcomes, potentially creating spurious correlations.
Loftus et al. (2018) provide a framework for this process in their work on causal reasoning for algorithmic fairness. They demonstrate techniques for variable identification based on domain knowledge, data analysis, and fairness requirements. Their approach emphasizes the importance of including variables that might reveal indirect discrimination or proxy effects, not just those directly used in the model.
For example, in a lending algorithm, relevant variables might include protected attributes (race, gender), outcomes (loan approval), mediators (credit score, income), and confounders (neighborhood characteristics, economic conditions). Relationships between these variables would be determined through domain expertise, existing research, and potentially causal discovery techniques applied to data.
For our Causal Analysis Methodology, systematic variable and relationship identification is essential because it determines the scope and accuracy of the resulting causal model. A model missing critical variables or relationships might fail to detect important bias mechanisms, while one including irrelevant elements might become unnecessarily complex or misleading.
Structural Equation Models for Bias Representation
Structural equation models (SEMs) provide a mathematical formalization of causal relationships that enable precise specification and analysis of bias mechanisms. This concept is vital for AI fairness because SEMs go beyond graphical representations to quantify how variables influence each other, allowing for more detailed analysis and precise intervention design.
SEMs build on causal graphs by adding mathematical equations that specify the functional relationships between variables, transforming qualitative causal structures into quantitative models. They interact with counterfactual fairness by providing the mathematical foundation for generating and evaluating counterfactual scenarios.
A structural equation model consists of equations defining how each variable is determined by its direct causes (parents in the causal graph) plus an error term representing unmeasured factors. In the fairness context, these equations allow you to model how protected attributes influence other variables through various pathways and with different strengths.
Kusner et al. (2017) employ SEMs as the foundation for counterfactual fairness in their landmark paper. They demonstrate how these models enable precise definition of counterfactual scenarios by showing how interventions on protected attributes would propagate through the system according to the specified causal structure.
For example, a SEM for a college admissions scenario might include equations specifying how gender influences standardized test scores through stereotype threat, how socioeconomic background affects educational opportunities, and how these factors collectively determine admission outcomes. These equations would quantify the strength of each relationship, enabling precise analysis of how bias propagates through the system.
For our Causal Analysis Methodology, SEMs provide the mathematical precision needed to move beyond qualitative causal reasoning to quantitative analysis and intervention design. By learning to develop these models, you'll gain the ability to specify exactly how bias operates in your system and design precisely targeted interventions.
Validating Causal Models in Fairness Contexts
Validating causal models is essential to ensure they accurately represent the actual mechanisms generating bias in AI systems. This concept is critical for AI fairness because interventions based on incorrect causal models may fail to address the real sources of bias or might inadvertently introduce new fairness problems.
Validation builds on causal graph construction and SEM development by providing approaches to assess whether these models accurately represent reality. It interacts with intervention design by determining how much confidence we can place in the causal understanding guiding our fairness strategies.
Validation approaches include testing implied conditional independencies (relationships that should be statistically independent according to the causal structure), comparing model predictions against experimental or observational data, sensitivity analysis to assess how robust conclusions are to violations of causal assumptions, and leveraging domain expertise to evaluate model plausibility.
Kilbertus et al. (2020) demonstrate the importance of causal model validation in their work on causal fairness analysis. They show how incorrect causal assumptions can lead to interventions that fail to address discrimination or inadvertently create new fairness problems, emphasizing the need for rigorous validation practices.
For example, if your causal model implies that education level and zip code should be conditionally independent given income, you can test this implication against your data. Significant deviation from this expected independence might suggest your causal structure needs revision. Similarly, if your model predicts certain effects from interventions, you might validate these predictions against historical outcomes from similar interventions.
For our Causal Analysis Methodology, validation techniques provide essential quality control, ensuring that the causal understanding guiding fairness interventions is well-founded. By incorporating these approaches, you'll be able to develop more reliable causal models and have greater confidence in the resulting fairness strategies.
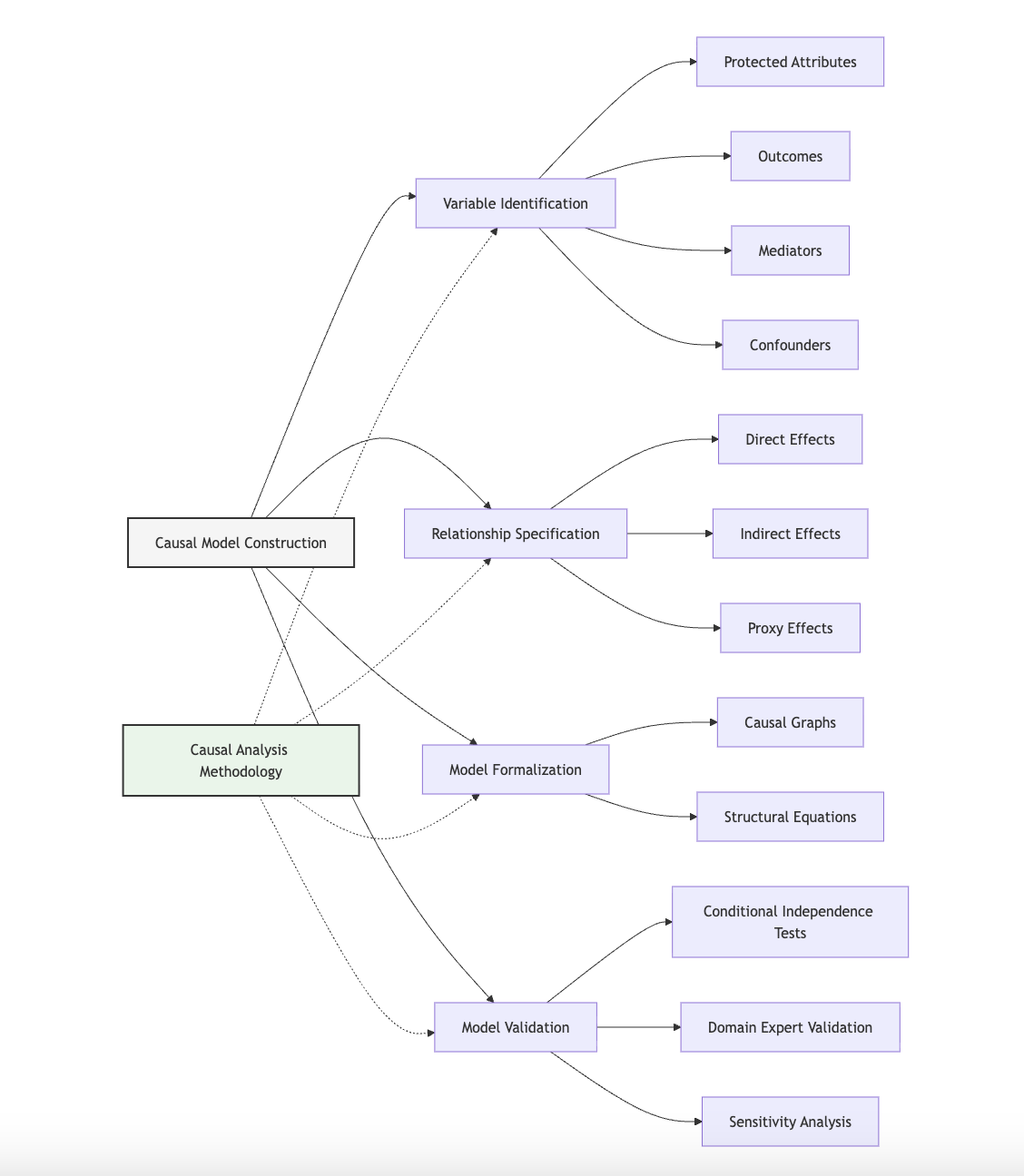
Domain Modeling Perspective
From a domain modeling perspective, causal model construction maps to specific components of ML systems:
- Data Collection and Selection: Causal models reveal which variables are necessary to measure for comprehensive bias analysis, identifying potential selection biases or missing confounders.
- Feature Engineering: Causal structures distinguish between features that serve as legitimate predictors versus proxies for protected attributes, informing feature selection and transformation.
- Model Architecture: Causal understanding guides which relationships should be learned versus which should be constrained, informing model design decisions.
- Evaluation Framework: Causal models provide the foundation for counterfactual evaluation approaches that assess fairness based on causal understanding.
- Intervention Design: Causal structures identify where in the ML pipeline interventions should be targeted to effectively address bias mechanisms.
This domain mapping helps you connect abstract causal modeling concepts to concrete ML system components. The Causal Analysis Methodology you'll develop in Unit 5 will leverage this mapping to guide where and how to implement fairness interventions based on causal understanding.
Conceptual Clarification
To clarify these abstract causal modeling concepts, consider the following analogies:
- Causal graph construction is similar to creating architectural blueprints before building a house. Just as blueprints specify how rooms connect and where utilities flow, causal graphs specify how variables influence each other and where bias might propagate. Without proper blueprints, construction proceeds haphazardly, potentially creating structural problems that are expensive to fix later. Similarly, without proper causal graphs, fairness interventions proceed without clear understanding of bias mechanisms, potentially creating new problems or failing to address root causes. Just as blueprints evolve through multiple drafts based on function, constraints, and expert feedback, causal graphs evolve through iterative refinement based on data, domain knowledge, and fairness requirements.
- Variable and relationship identification resembles diagnosing a complex medical condition, where physicians must determine which symptoms, risk factors, and test results are relevant and how they relate to each other. A doctor who overlooks key symptoms or misunderstands their relationships might miss the correct diagnosis or prescribe ineffective treatments. Similarly, causal modeling that omits critical variables or misspecifies their relationships might fail to identify important bias mechanisms or lead to misguided interventions. Just as medical diagnosis integrates patient history, current symptoms, test results, and medical knowledge, causal modeling integrates historical patterns, current data, statistical analysis, and domain expertise.
- Structural equation models function like recipe instructions that specify not just what ingredients are needed (variables) but exactly how they combine and in what proportions (functional relationships). A recipe that lists ingredients without specific measurements or mixing instructions leaves too much ambiguity for reliable results. Similarly, causal graphs without structural equations show which variables influence each other but not how strongly or in what functional form, limiting their utility for precise analysis or intervention design. Just as detailed recipes enable you to predict how changes to ingredients will affect the final dish, SEMs enable you to predict how interventions on certain variables will affect outcomes throughout the system.
- Causal model validation resembles stress-testing a bridge design before construction begins. Engineers don't simply trust that their blueprints will produce a safe bridge; they subject the design to various tests and scenarios to verify its structural integrity. Similarly, causal models shouldn't be accepted based solely on their theoretical plausibility; they should be validated against data, tested for robustness to assumption violations, and evaluated by domain experts. Just as bridge stress-testing identifies potential failure points before they become dangerous, causal model validation identifies potential inaccuracies before they lead to misguided fairness interventions.
Intersectionality Consideration
Causal modeling for bias detection must explicitly address intersectionality – how multiple protected attributes interact to create unique causal mechanisms affecting individuals with overlapping marginalized identities. Standard causal models that examine protected attributes in isolation may miss critical intersectional effects where multiple dimensions of identity create distinct causal pathways.
Traditional causal graphs typically represent protected attributes as separate nodes with independent causal relationships. This approach fails to capture how the intersection of multiple attributes might create unique mechanisms that differ from those affecting any single attribute in isolation. For example, bias against Black women in facial recognition systems might operate through causal pathways distinct from those affecting either Black men or white women.
Recent work by Yang et al. (2020) proposes approaches for constructing "intersectional causal graphs" that explicitly model how multiple protected attributes jointly influence outcomes. Their research demonstrates techniques for representing interaction effects between protected attributes in causal models, enabling more nuanced analysis of bias mechanisms that specifically affect intersectional groups.
For the Causal Analysis Methodology, addressing intersectionality in causal modeling requires:
- Explicitly representing intersectional categories as distinct nodes in causal graphs when appropriate
- Modeling interaction terms between protected attributes in structural equations
- Testing for path-specific effects that uniquely affect intersectional subgroups
- Validating causal models with specific attention to their performance for intersectional categories
By incorporating these intersectional considerations into causal model construction, you'll develop more comprehensive representations of bias mechanisms that capture the complex ways multiple forms of discrimination interact rather than treating protected attributes as independent factors.
3. Practical Considerations
Implementation Framework
To systematically construct causal models for bias detection, follow this structured methodology:
-
Variable Identification and Classification:
-
Identify protected attributes relevant to your fairness concerns (e.g., race, gender, age).
- Specify outcome variables representing decisions where fairness matters (e.g., loan approval, hiring recommendation).
- Identify potential mediators through which protected attributes might influence outcomes (e.g., education, test scores).
- Determine possible confounders that affect both protected attributes and outcomes (e.g., neighborhood characteristics, socioeconomic factors).
-
Categorize each variable according to its role in the causal structure and document your reasoning.
-
Causal Relationship Mapping:
-
Draw on domain knowledge to determine direct causal relationships between variables.
- Consult with subject matter experts to validate proposed relationships.
- Review relevant literature and research findings supporting causal connections.
- Consider temporal ordering to ensure causality (causes must precede effects).
-
Document evidence supporting each proposed causal relationship.
-
Formal Model Development:
-
Create a directed acyclic graph (DAG) representing the causal structure.
- Specify structural equations for each variable based on its direct causes.
- Determine functional forms for relationships based on domain knowledge.
- Implement the model using appropriate causal modeling tools.
-
Document model assumptions and limitations clearly.
-
Model Validation:
-
Test implied conditional independencies against observational data.
- Perform sensitivity analysis to assess robustness to assumption violations.
- Compare model predictions with established findings in the domain.
- Seek expert review of model structure and assumptions.
- Iteratively refine the model based on validation results.
These methodologies integrate with standard ML workflows by informing data collection, feature engineering, model selection, and evaluation approaches. While they add complexity to the development process, they establish a solid foundation for effective fairness interventions based on causal understanding.
Implementation Challenges
When constructing causal models for bias detection, practitioners commonly face these challenges:
-
Limited Domain Knowledge: Accurate causal modeling requires substantial domain expertise, which might be incomplete or evolving. Address this by:
-
Adopting an iterative approach that evolves the causal model as knowledge improves.
- Constructing multiple candidate models representing different causal hypotheses.
- Collaborating with diverse domain experts to capture different perspectives.
-
Being explicit about uncertainty in the model and conducting sensitivity analysis.
-
Unobserved Confounders: Critical confounding variables might be unmeasured in available data. Address this by:
-
Conducting sensitivity analysis to assess how unobserved confounding might affect conclusions.
- Using domain knowledge to identify potential unmeasured confounders.
- Leveraging techniques like instrumental variables or proxy variables when appropriate.
- Explicitly documenting potential unobserved confounders and their implications for model validity.
Successfully implementing causal modeling for bias detection requires resources including domain expertise to inform model construction, data to test implied relationships, technical knowledge of causal modeling techniques, and organizational commitment to addressing bias based on causal understanding.
Evaluation Approach
To assess whether your causal models effectively represent bias mechanisms, implement these evaluation strategies:
-
Structural Validation:
-
Test implied conditional independencies (d-separation properties) derived from the causal graph.
- Measure the strength of associations along different causal pathways.
- Assess whether temporal sequences in data align with the proposed causal ordering.
-
Document validation evidence for key causal relationships in the model.
-
Functional Validation:
-
Evaluate whether structural equations accurately predict relationships observed in data.
- Measure goodness-of-fit for equations representing key relationships.
- Assess sensitivity of model predictions to parameter variations.
- Test whether interventions produce expected downstream effects according to the model.
These evaluation approaches should be integrated with your organization's broader fairness assessment framework, providing deeper insights than purely statistical metrics while acknowledging the limitations of causal knowledge in practical applications.
4. Case Study: Loan Approval Algorithm
Scenario Context
A financial institution is developing a machine learning algorithm to predict default risk and automate loan approval decisions. After initial testing, the data science team discovered concerning disparities: applicants from minority racial groups were being approved at significantly lower rates than white applicants with seemingly similar financial profiles.
The institution's leadership wants to understand whether these disparities represent discrimination that should be addressed or legitimate risk assessment based on relevant predictive factors. The team must determine the causal mechanisms driving these disparities to design appropriate interventions.
This scenario involves multiple stakeholders with diverse concerns: risk managers focused on accurate default prediction, compliance officers concerned about regulatory requirements, business leaders interested in expanding customer base, and applicants seeking fair access to financial resources. The fairness implications are substantial given the impact on financial inclusion and wealth-building opportunities across demographic groups.
Problem Analysis
To understand the causal mechanisms behind the observed disparities, the team constructed a causal model of the loan approval process, drawing on domain expertise, research literature, and analysis of historical lending data.
The initial causal graph revealed several potential pathways through which race might influence loan approval decisions:
- Proxy Discrimination Pathways: The model relied heavily on zip code as a predictive feature, which serves as a proxy for race due to historical residential segregation patterns. The causal graph showed no direct causal relationship between zip code and default risk when controlling for individual financial factors, suggesting this created a problematic pathway from race to loan decisions through a proxy variable.
- Indirect Discrimination Pathways: Race influences educational opportunities and employment patterns due to historical discrimination, which legitimately affect income stability and credit history, which in turn predict default risk. This represents an indirect pathway from race to loan decisions through mediators that are causally related to default risk.
- Selection Bias in Training Data: Historical lending practices created selection bias in the training data, where minority applicants who received loans represented a non-random subset of all minority applicants (typically those with exceptionally strong applications), creating biased estimates of default risk across racial groups.
The team formalized these relationships in a structural equation model that quantified how race influenced various factors in the lending process. This SEM revealed that approximately 60% of the observed approval disparity operated through proxy variables like zip code, 25% through indirect effects on legitimate predictors like credit history, and 15% through selection bias in the training data.
A correlation-based approach might have simply enforced demographic parity or removed race from the dataset, potentially approving higher-risk loans or rejecting qualified applicants. The causal approach enabled a more nuanced understanding of different bias mechanisms requiring different interventions.
From an intersectional perspective, the analysis revealed that the causal mechanisms operated differently for specific subgroups. For example, the zip code proxy effect was particularly pronounced for Black women, while selection bias in the training data most significantly affected Hispanic men, reflecting unique historical patterns of discrimination affecting these intersections differently.
Solution Implementation
Based on their causal analysis, the team implemented a structured approach to address the identified bias mechanisms:
-
Causal Variable Identification: The team systematically identified and classified variables in their lending process:
-
Protected attributes: race, gender, age
- Outcome variables: loan approval decision, interest rate
- Mediator variables: credit score, income, debt-to-income ratio, employment history
-
Confounding variables: neighborhood economic conditions, local housing markets, generational wealth
-
Causal Graph Construction: Working with domain experts in lending and fair housing, they developed a causal graph representing relationships between these variables. This graph explicitly represented both legitimate predictive pathways (e.g., income stability → default risk) and potentially problematic ones (e.g., zip code as a proxy for race).
- Structural Equation Modeling: The team formalized their causal understanding by developing equations that quantified relationships between variables. For example, they modeled how historical discrimination affected credit history formation and how zip code related to default risk when controlling for other factors.
-
Model Validation: The team validated their causal model through several approaches:
-
Testing conditional independence relationships implied by their graph
- Comparing model predictions against historical patterns in their lending data
- Consulting with fair lending experts to assess model plausibility
- Performing sensitivity analysis to evaluate robustness to assumption violations
This causal approach enabled the team to design targeted interventions for specific bias mechanisms:
- For proxy discrimination through zip code, they implemented feature transformations that removed the problematic proxy effect while preserving legitimate predictive information.
- For indirect discrimination through credit history, they adjusted their model to account for historical disparities in credit access.
- For selection bias in training data, they implemented sampling techniques to create more representative training datasets.
The causal model provided clear guidance on which intervention approaches would address specific bias mechanisms rather than implementing generic fairness constraints that might harm prediction accuracy or fail to address root causes.
Outcomes and Lessons
The causal modeling approach yielded several significant benefits:
- It enabled more targeted interventions that addressed specific bias mechanisms rather than imposing blanket constraints.
- It preserved model accuracy while improving fairness by focusing only on problematic causal pathways.
- It provided an explainable foundation for fairness interventions that stakeholders could understand and support.
- It revealed intersectional effects that would have been missed by analyzing protected attributes in isolation.
The team did face challenges in constructing their causal model:
- Limited data availability for validating some causal relationships
- Uncertainty about historical factors affecting credit history formation
- Evolving understanding of how neighborhood characteristics influence default risk
The most generalizable lessons from this case study include:
- The importance of distinguishing between different causal mechanisms of bias (proxy, indirect, selection) that require different intervention approaches.
- The value of formalizing causal understanding in explicit models that can be validated and refined.
- The necessity of incorporating domain expertise when constructing causal models for fairness analysis.
- The benefits of considering intersectional effects in causal models to capture unique discrimination patterns affecting specific subgroups.
These insights directly inform the development of the Causal Analysis Methodology in Unit 5, demonstrating how explicit causal modeling enables more nuanced understanding of bias mechanisms and more effective fairness interventions.
5. Frequently Asked Questions
FAQ 1: Causal Models Vs. Statistical Models
Q: How do causal models for bias detection differ from traditional statistical models in machine learning, and what unique insights do they provide?
A: Causal models fundamentally differ from traditional statistical models by representing the data-generating process rather than just statistical associations. While statistical models might reveal that zip code correlates with loan defaults and race correlates with zip code, they can't distinguish whether zip code is a legitimate predictor or merely a proxy for race. Causal models explicitly represent these relationships and their directions, enabling you to distinguish between legitimate predictive pathways and problematic proxy discrimination. This distinction matters critically for intervention—statistical models might suggest removing all correlated features, potentially sacrificing prediction accuracy unnecessarily, while causal models can identify precisely which pathways represent discrimination requiring intervention versus which represent legitimate prediction patterns that should be preserved. Additionally, causal models enable counterfactual analysis ("how would this prediction change if only the applicant's race were different?") that statistical models can't support. Most importantly, causal models align with how we conceptualize fairness and discrimination in ethical and legal frameworks—not as statistical properties but as causal processes where protected attributes unfairly influence outcomes through specific mechanisms that can and should be addressed.
FAQ 2: Building Causal Models With Limited Data
Q: How can I develop useful causal models for bias detection when I have limited data or cannot perform controlled experiments?
A: Building causal models with limited data is challenging but still valuable with the right approach. First, leverage domain expertise as your primary guidance—consult with subject matter experts, review relevant literature, and draw on historical understanding to establish plausible causal relationships. Second, use qualitative data including interviews, focus groups, or case studies to inform your causal understanding when quantitative data is limited. Third, implement structural constraints in your models based on logical or temporal considerations—for instance, birth characteristics must precede education outcomes. Fourth, apply causal discovery algorithms that can identify potential causal structures from observational data, while remaining cautious about their limitations. Fifth, develop multiple candidate models representing different plausible causal hypotheses, then assess their relative plausibility through validation against available data. Finally, perform extensive sensitivity analysis to understand how your conclusions might change under different causal assumptions, establishing bounds on potential bias rather than point estimates. Remember that even with limited data, an explicit causal model with acknowledged uncertainties provides more guidance for fairness interventions than proceeding without any causal understanding at all. The key is transparency about limitations and assumptions, allowing stakeholders to assess the confidence they should place in conclusions drawn from your model.
6. Project Component Development
Component Description
In Unit 5, you will develop the causal modeling section of the Causal Analysis Methodology. This component will provide a structured approach for constructing causal graphs and structural equation models that represent the mechanisms through which bias enters and propagates in AI systems.
Your deliverable will include templates for variable identification, graph construction, structural equation specification, and model validation, along with guidelines for applying these approaches to different application domains. This component will build on the conceptual understanding from Unit 1 and provide the structural foundation for the counterfactual analysis in Unit 3 and practical inference approaches in Unit 4.
Development Steps
- Create a Variable Identification Framework: Develop a structured approach for identifying and classifying relevant variables in causal models for fairness analysis. Create templates for documenting protected attributes, outcomes, mediators, and confounders, along with their roles in the causal structure.
- Design a Causal Graph Construction Methodology: Create guidelines for developing causal graphs that represent bias mechanisms, including protocols for determining causal relationships based on domain knowledge, existing research, and data analysis. Include visual templates for graph representation and annotation conventions.
- Develop a Structural Equation Specification Approach: Build templates for formalizing causal relationships through structural equations, including guidance for determining functional forms and parameter estimation approaches. Create documentation formats for recording model assumptions and limitations.
- Build a Model Validation Framework: Design protocols for validating causal models through conditional independence testing, sensitivity analysis, expert review, and comparative evaluation. Create templates for documenting validation evidence and model refinement processes.
Integration Approach
This causal modeling component will interface with other parts of the Causal Analysis Methodology by:
- Building on the conceptual understanding of causality established in Unit 1's component.
- Providing the structural foundation for the counterfactual analysis techniques developed in Unit 3's component.
- Informing the practical inference approaches addressed in Unit 4's component.
- Supporting the integration of all these elements in the comprehensive methodology in Unit 5.
To enable successful integration, use consistent terminology across components, establish clear connections between causal model structures and counterfactual definitions, and develop documentation formats that support the complete methodology workflow from initial bias detection through intervention selection.
7. Summary and Next Steps
Key Takeaways
This Unit has equipped you with the essential techniques for constructing formal causal models that represent bias mechanisms in AI systems. Key insights include:
- Causal graphs provide explicit representations of how protected attributes influence outcomes through various pathways, enabling systematic identification of direct discrimination, indirect discrimination, and proxy discrimination mechanisms that cannot be distinguished through purely statistical approaches.
- Systematic variable identification and classification form the foundation of effective causal modeling, determining which bias mechanisms can be represented and which remain invisible in your analysis.
- Structural equation models formalize causal relationships mathematically, enabling precise specification of how bias propagates through systems and providing the foundation for counterfactual analysis.
- Model validation techniques ensure that causal models accurately represent reality, preventing interventions based on incorrect causal understanding that might fail to address bias or create new fairness problems.
These concepts directly address our guiding questions by providing concrete techniques for translating domain knowledge into formal causal models and identifying critical pathways between protected attributes and outcomes.
Application Guidance
To apply these causal modeling techniques in practice:
- Start by systematically identifying and classifying variables relevant to your fairness analysis, ensuring you include protected attributes, outcomes, potential mediators, and confounders.
- Draw on domain expertise, existing research, and data analysis to construct causal graphs representing how these variables relate to each other, paying particular attention to pathways from protected attributes to outcomes.
- Formalize your causal understanding through structural equations that specify the functional relationships between variables, enabling more precise analysis and intervention design.
- Validate your causal models through conditional independence testing, sensitivity analysis, expert review, and comparison with established domain knowledge, iteratively refining them based on validation results.
If you're new to causal modeling, begin with simple graphs focusing on the most critical relationships and expand them iteratively as your understanding develops. Remember that even imperfect causal models often provide better guidance for fairness interventions than no causal modeling at all.
Looking Ahead
In the next Unit, we will build on these causal modeling techniques to explore counterfactual fairness – a powerful framework for evaluating whether models exhibit discrimination through formal counterfactual analysis. You will learn how to use the causal models you've constructed to generate counterfactual scenarios, evaluate fairness across these scenarios, and identify specific pathways that require intervention.
The causal modeling techniques you've mastered in this Unit provide the essential foundation for this counterfactual analysis. By constructing explicit causal representations of bias mechanisms, you've created the structural framework necessary for meaningful counterfactual reasoning about fairness in AI systems.
References
Crenshaw, K. (1989). Demarginalizing the intersection of race and sex: A black feminist critique of antidiscrimination doctrine, feminist theory, and antiracist politics. University of Chicago Legal Forum, 1989(1), 139–167.
Kilbertus, N., Ball, P. J., Kusner, M. J., Weller, A., & Silva, R. (2020). The sensitivity of counterfactual fairness to unmeasured confounding. In Proceedings of the 35th Conference on Uncertainty in Artificial Intelligence.
Kusner, M. J., Loftus, J., Russell, C., & Silva, R. (2017). Counterfactual fairness. In Advances in Neural Information Processing Systems (pp. 4066-4076).
Loftus, J. R., Russell, C., Kusner, M. J., & Silva, R. (2018). Causal reasoning for algorithmic fairness. arXiv preprint arXiv:1805.05859.
Pearl, J. (2009). Causality: Models, reasoning and inference (2nd ed.). Cambridge University Press.
Plečko, D., & Bareinboim, E. (2022). Causal fairness analysis. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 36, No. 9, pp. 10093-10101).
Yang, K., Loftus, J. R., & Stoyanovich, J. (2020). Causal intersectionality for fair ranking. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency (pp. 481-491).
Zhang, J., & Bareinboim, E. (2018). Fairness in decision-making – the causal explanation formula. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 32, No. 1).
Unit 3
Unit 3: Counterfactual Fairness Framework
1. Conceptual Foundation and Relevance
Guiding Questions
- Question 1: How can we formalize fairness judgments through causal "what if" scenarios to determine whether a model treats individuals differently based on protected attributes?
- Question 2: When is a prediction system counterfactually fair, and how do we implement this principle in practical machine learning applications?
Conceptual Context
Counterfactual fairness represents a significant advancement in our approach to algorithmic fairness by directly addressing the core ethical question: Would this individual receive the same prediction if their protected attributes were different but all other causally independent factors remained the same? This question captures our intuitive understanding of fairness better than most statistical definitions, which often fail to distinguish between discriminatory correlations and legitimate predictive relationships.
Traditional fairness metrics like demographic parity or equal opportunity operate purely on statistical outcomes without considering the underlying causal mechanisms. This limitation can lead to interventions that "break the thermometer" rather than addressing the underlying "fever" of discrimination. As Kusner et al. (2017) demonstrated in their seminal work, models that appear fair according to statistical criteria may still perpetuate discrimination when analyzed through a causal lens.
Counterfactual fairness provides a more principled approach by explicitly modeling how protected attributes influence outcomes through various causal pathways. This allows us to distinguish between legitimate predictive relationships and problematic patterns that perpetuate historical biases—a distinction that purely statistical approaches cannot make.
This Unit builds upon the foundation of causal reasoning established in Unit 1 and the causal modeling techniques introduced in Unit 2. While those Units focused on understanding why causality matters for fairness and how to construct causal models, this Unit applies these concepts to develop a formal framework for counterfactual fairness. This framework will directly inform the Causal Analysis Methodology you'll develop in Unit 5, providing a principled criterion for evaluating whether models exhibit causal discrimination and guiding intervention strategies based on counterfactual analysis.
2. Key Concepts
Counterfactual Fairness Definition
Counterfactual fairness provides a formal mathematical definition of fairness based on causal reasoning: a prediction is counterfactually fair if it remains unchanged in counterfactual worlds where an individual's protected attributes are different, but all variables not causally dependent on those attributes remain the same. This definition directly addresses whether models discriminate based on protected attributes in causally meaningful ways.
This concept builds on the causal models from Unit 2 by using them to define precise fairness criteria. It interacts with other fairness concepts by providing a more nuanced alternative to statistical definitions that cannot distinguish between legitimate and problematic associations between protected attributes and outcomes.
Formally, Kusner et al. (2017) define counterfactual fairness as follows: A prediction Ŷ is counterfactually fair if:
P(Ŷ₍A←a₎(U) = y | X = x, A = a) = P(Ŷ₍A←a′₎(U) = y | X = x, A = a)
Where A represents protected attributes, X represents observed features, U represents unobserved background variables, and the notation Ŷ₍A←a′₎(U) represents the counterfactual prediction if the protected attribute had been a' instead of a.
This formal definition captures the intuition that predictions should not change under counterfactual scenarios where only the protected attributes differ. For instance, in a loan approval system, a counterfactually fair model would give the same prediction to an individual regardless of their race or gender, assuming all causally independent characteristics remain identical.
For the Causal Analysis Methodology we'll develop in Unit 5, this counterfactual fairness definition provides both an evaluation criterion for determining whether existing systems exhibit causal discrimination and an objective for designing fairness interventions.
Structural Causal Models for Counterfactuals
Structural causal models (SCMs) provide the mathematical foundation for generating and evaluating counterfactual scenarios. These models enable us to simulate "what if" scenarios by intervening on protected attributes while preserving the appropriate relationships between other variables.
This concept extends the causal graphical models from Unit 2 by adding the mathematical formalism needed for counterfactual reasoning. It interacts with the counterfactual fairness definition by providing the computational framework for determining whether a model satisfies this criterion.
An SCM consists of:
- A set of exogenous (background) variables U
- A set of endogenous (observed) variables V
- A set of structural equations F that determine how each endogenous variable depends on other variables
- A probability distribution P(U) over the exogenous variables
Following Pearl's framework (2009), counterfactuals are computed in three steps:
- Abduction: Update the probability distribution of exogenous variables based on observed evidence
- Action: Modify the structural equations to implement the intervention (e.g., setting the protected attribute to a different value)
- Prediction: Compute the resulting distribution of the target variable
Chiappa (2019) extended this framework to develop efficient methods for computing counterfactual fairness in complex models, demonstrating how SCMs can be practically implemented for fairness evaluation.
For our Causal Analysis Methodology, understanding SCMs is essential because they provide the technical foundation for implementing counterfactual fairness evaluations and designing interventions that satisfy counterfactual fairness criteria.
Path-Specific Counterfactual Fairness
Path-specific counterfactual fairness refines the basic counterfactual framework by distinguishing between fair and unfair causal pathways from protected attributes to outcomes. This nuanced approach recognizes that not all influences of protected attributes constitute discrimination—some causal pathways may represent legitimate relationships that should be preserved.
This concept builds on basic counterfactual fairness by introducing more flexibility in defining which causal influences are problematic. It interacts with fairness interventions by enabling more targeted approaches that block specific discriminatory pathways while preserving legitimate predictive relationships.
Chiappa and Isaac (2019) formalized this approach by defining path-specific counterfactual fairness, which only requires blocking the effect of protected attributes along designated unfair pathways. This approach acknowledges that some causal influences of protected attributes may be considered fair (e.g., a genuine skill difference) while others represent discrimination that should be eliminated (e.g., biased evaluation of the same skill).
For example, in educational settings, gender might influence subject preference, which legitimately affects performance in certain courses. A path-specific approach could allow this influence while blocking pathways where gender affects how the same performance is evaluated.
The key insight is that fairness judgments ultimately require normative decisions about which causal pathways constitute legitimate influence versus discrimination—decisions that must be made based on ethical principles and application-specific context rather than purely technical considerations.
For our Causal Analysis Methodology, path-specific counterfactual fairness provides a more nuanced framework for identifying problematic causal pathways and designing targeted interventions that preserve model utility while eliminating discriminatory influences.
Implementing Counterfactually Fair Models
Implementing counterfactually fair models requires specific techniques for training models that satisfy counterfactual fairness criteria. These implementation approaches translate the theoretical framework of counterfactual fairness into practical machine learning solutions.
This concept builds on structural causal models by applying them to the development of fair prediction systems. It interacts with fairness interventions by providing concrete methods for developing models that satisfy counterfactual fairness criteria.
Kusner et al. (2017) proposed several approaches for implementing counterfactually fair models:
- Fair representation learning: Transform the data to remove the influence of protected attributes along unfair pathways while preserving other information.
- Causal inference-based approaches: Estimate the true causal effects in the data and use these to build models that explicitly control for unfair influences.
- Constrained optimization: Train models with explicit counterfactual fairness constraints during the optimization process.
Subsequent work by Russell et al. (2017) expanded these approaches with efficient algorithms for learning counterfactually fair representations that can be used with standard machine learning techniques.
These implementation approaches often involve trade-offs between counterfactual fairness, model complexity, and predictive performance. Research by Chiappa et al. (2020) demonstrated that in many cases, counterfactually fair models can achieve comparable accuracy to unconstrained models when properly implemented, challenging the notion that fairness necessarily comes at a significant cost to performance.
For our Causal Analysis Methodology, understanding these implementation approaches is essential for translating causal fairness analysis into practical interventions that can be deployed in real-world systems.
Evaluating Counterfactual Fairness
Evaluating counterfactual fairness requires specialized techniques for measuring whether models satisfy counterfactual fairness criteria and quantifying the degree of any violations. This evaluation process is essential for determining whether fairness interventions are effective.
This concept builds on the counterfactual fairness definition by providing practical approaches for measuring compliance. It interacts with implementation techniques by providing feedback on their effectiveness and guiding iterative improvements.
Black et al. (2020) proposed several metrics for evaluating counterfactual fairness:
- Counterfactual Effect Size: Measures the average difference in predictions between factual and counterfactual worlds.
- Counterfactual Fairness Violation Rate: The proportion of instances where counterfactual predictions differ from factual ones by more than a specified threshold.
- Path-Specific Effect Metrics: Measure the influence of protected attributes along specific causal pathways.
These evaluation approaches typically require access to the causal model used to generate counterfactuals. However, Wu et al. (2019) developed methods for approximate evaluation when the true causal model is unknown, using sensitivity analysis to bound the potential counterfactual unfairness under different causal assumptions.
A key challenge in evaluation is that counterfactual fairness cannot be directly measured from observed data alone, as counterfactuals by definition involve unobserved scenarios. This limitation highlights the importance of causal modeling assumptions in counterfactual fairness assessments.
For our Causal Analysis Methodology, these evaluation techniques will be essential for determining whether existing systems exhibit counterfactual unfairness and measuring the effectiveness of interventions designed to address these issues.
Domain Modeling Perspective
From a domain modeling perspective, counterfactual fairness connects to specific components of ML systems:
- Problem Formulation: Counterfactual analysis may reveal that the prediction task itself needs to be reformulated to avoid inherent fairness issues in the original framing.
- Data Processing: Counterfactually fair data representations can be developed by transforming features to remove unfair causal influences.
- Model Architecture: Some model architectures more naturally support counterfactual fairness constraints or path-specific control.
- Training Procedure: Counterfactual fairness can be incorporated through modified loss functions or regularization terms.
- Evaluation Framework: Specialized testing procedures are needed to evaluate counterfactual fairness beyond standard performance metrics.
This domain mapping helps you understand how counterfactual fairness considerations influence different stages of the ML lifecycle. The Causal Analysis Methodology will leverage this mapping to provide targeted recommendations for ensuring counterfactual fairness throughout the ML pipeline.

Conceptual Clarification
To clarify these abstract counterfactual concepts, consider the following analogies:
- Counterfactual fairness is similar to a controlled scientific experiment where researchers change exactly one factor while keeping everything else constant. Just as scientists might test a drug by creating identical test groups where only the treatment differs, counterfactual fairness examines what would happen if only a person's protected attribute changed while everything causally independent remained the same. This controlled comparison isolates whether the protected attribute itself unfairly influences decisions, just as an experiment isolates the effect of a treatment.
- Structural causal models for counterfactuals function like sophisticated flight simulators that can accurately predict aircraft behavior under different conditions based on physical laws. These simulators can answer "what if" questions like "What would happen if the aircraft encountered turbulence at 30,000 feet?" Similarly, structural causal models answer "what if" questions about prediction outcomes under different scenarios by modeling the underlying causal mechanisms rather than just statistical correlations.
- Path-specific counterfactual fairness resembles traffic management in a city with both legitimate and problematic routes. City planners might block specific problematic streets (unfair pathways) while keeping legitimate routes open to maintain overall traffic flow (prediction utility). Just as selective road closures target specific traffic problems without shutting down the entire city, path-specific approaches block only discriminatory causal pathways while preserving legitimate predictive relationships.
- Implementing counterfactually fair models is like designing water filtration systems that remove specific contaminants (unfair influences) while preserving beneficial minerals (legitimate predictive information). Different filtration technologies (implementation approaches) may target different contaminants with varying effectiveness and costs, just as different fairness implementation techniques have different strengths, limitations, and trade-offs.
Intersectionality Consideration
Counterfactual fairness approaches must be extended to address intersectional concerns, where multiple protected attributes interact to create unique patterns of discrimination. Traditional counterfactual approaches often examine protected attributes in isolation, potentially missing critical intersectional effects where combinations of attributes lead to distinct forms of discrimination.
As Crenshaw (1989) established in her foundational work, discrimination often operates differently at the intersections of multiple marginalized identities, creating unique challenges that cannot be understood by examining each identity dimension separately. For AI systems, this means counterfactual fairness must consider how multiple protected attributes jointly influence outcomes through various causal pathways.
Recent work by Yang et al. (2020) has extended counterfactual fairness to address intersectionality by developing techniques for:
- Intersectional Counterfactual Queries: Formulating counterfactual questions that change multiple protected attributes simultaneously to evaluate their joint effects.
- Compound Pathway Analysis: Identifying causal pathways that specifically affect individuals at certain intersections, such as pathways that uniquely impact women of color.
- Intersectional Fair Representations: Learning data representations that remove unfair influences along pathways affecting intersectional groups.
These extensions are particularly important because naive applications of counterfactual fairness might address discrimination along single attributes while leaving intersectional discrimination unaddressed. For example, a hiring algorithm might appear counterfactually fair with respect to gender and race separately, while still discriminating against specific intersectional groups like Black women.
For our Causal Analysis Methodology, addressing intersectionality requires:
- Explicitly modeling interactions between protected attributes in causal graphs
- Formulating counterfactual queries that examine combinations of protected attributes
- Identifying causal pathways that specifically affect intersectional groups
- Developing evaluation measures that capture intersectional counterfactual fairness
By incorporating these intersectional considerations, our methodology will enable more comprehensive counterfactual fairness analysis that captures the complex ways multiple forms of discrimination interact.
3. Practical Considerations
Implementation Framework
To effectively apply counterfactual fairness in practice, follow this structured methodology:
-
Counterfactual Fairness Analysis:
-
Formulate specific counterfactual queries relevant to your application: "Would this prediction change if the individual's protected attributes were different?"
- Identify which causal pathways should be considered fair versus unfair based on domain knowledge and ethical principles.
- Compute counterfactual predictions using the causal model for different protected attribute values.
- Measure disparities between factual and counterfactual predictions to quantify counterfactual unfairness.
-
Document fairness violations with specific examples and patterns discovered.
-
Path-Specific Analysis:
-
Decompose the total effect of protected attributes into path-specific components.
- Classify these pathways as fair or unfair based on domain expertise and ethical considerations.
- Quantify the contribution of each pathway to observed disparities.
- Identify the most problematic pathways that require intervention.
-
Document the rationale for pathway classifications with stakeholder input.
-
Intervention Design:
-
Select appropriate intervention approaches based on the specific counterfactual fairness violations identified:
- For data-level issues: Transform features to remove unfair influences while preserving legitimate information.
- For model-level issues: Modify the learning objective to incorporate counterfactual fairness constraints.
- For post-processing: Adjust predictions to satisfy counterfactual fairness criteria.
- Implement the selected interventions while monitoring their effect on both fairness and performance metrics.
- Iterate on intervention design based on evaluation results.
These methodologies integrate with standard ML workflows by extending traditional model development processes to incorporate counterfactual fairness considerations. While they add complexity to the development process, they ensure that fairness interventions address the causal mechanisms of discrimination rather than just surface-level symptoms.
Implementation Challenges
When implementing counterfactual fairness approaches, practitioners commonly face these challenges:
-
Uncertainty in Causal Models: Counterfactual fairness relies on accurate causal models, but perfect causal knowledge is rarely available. Address this by:
-
Conducting sensitivity analysis to determine how robust your counterfactual conclusions are to variations in causal assumptions.
- Developing multiple plausible causal models based on different domain expertise and testing counterfactual fairness under each.
- Being transparent about causal assumptions and their limitations in documentation.
-
Using data-driven approaches to validate causal structures where possible.
-
Balancing Counterfactual Fairness and Model Performance: Strictly enforcing counterfactual fairness constraints may significantly impact predictive performance. Address this by:
-
Implementing path-specific approaches that only block unfair pathways, preserving legitimate predictive relationships.
- Developing relaxed notions of counterfactual fairness that allow for small violations when justified.
- Making explicit the trade-offs between different objectives and establishing acceptable thresholds.
- Exploring whether the prediction task itself needs reformulation if fairness and performance seem fundamentally at odds.
Successfully implementing counterfactual fairness approaches requires resources including domain expertise to develop accurate causal models, stakeholder engagement to establish which causal pathways are considered fair versus unfair, and computational resources for counterfactual generation and evaluation.
Evaluation Approach
To assess whether your counterfactual fairness implementation is effective, apply these evaluation strategies:
-
Counterfactual Disparity Measurement:
-
Calculate the average difference between factual and counterfactual predictions across the dataset.
- Measure the proportion of instances where predictions change under counterfactual scenarios.
- Compute confidence intervals for these measures to account for statistical uncertainty.
-
Compare these measures across different demographic subgroups to identify patterns in counterfactual unfairness.
-
Path-Specific Effect Evaluation:
-
Decompose total counterfactual effects into contributions from different causal pathways.
- Measure the magnitude of effects along pathways classified as unfair.
- Compare these effects before and after interventions to assess improvement.
- Validate that legitimate predictive pathways are preserved while unfair ones are mitigated.
These evaluation approaches should be integrated with your organization's broader fairness assessment framework, providing deeper insights than purely statistical metrics while acknowledging the limitations of causal knowledge in practical applications.
4. Case Study: Lending Algorithm
Scenario Context
A financial institution is developing a machine learning algorithm to predict default risk for personal loan applications. The algorithm analyzes credit history, income, employment stability, debt-to-income ratio, and other financial indicators to generate risk scores that determine loan approval and interest rates.
Initial analysis revealed concerning patterns: applicants from certain racial groups receive significantly higher risk scores on average, leading to higher rejection rates and less favorable terms. However, traditional statistical fairness metrics provide limited insight into whether these disparities represent genuine discrimination or legitimate risk assessment based on relevant financial factors.
The lending context involves multiple stakeholders with different priorities: risk managers concerned with accurate default prediction, regulatory compliance officers monitoring fair lending requirements, and customers from diverse backgrounds seeking equitable access to credit. The fairness implications are significant given both ethical concerns and legal requirements prohibiting discrimination in lending.
Problem Analysis
Applying counterfactual fairness analysis to this lending scenario reveals several important insights:
-
Causal Model Development: The data science team collaborated with domain experts to develop a causal model of the lending context, identifying key relationships between variables:
-
Race influences residential neighborhood through historical segregation patterns
- Neighborhood influences property values and available educational opportunities
- Educational opportunities influence income potential and employment stability
-
Income and employment directly influence ability to repay loans
-
Counterfactual Analysis: Using this causal model, the team generated counterfactual scenarios asking: "Would this applicant receive the same risk score if they belonged to a different racial group, holding constant all factors not causally dependent on race?" The analysis revealed significant counterfactual unfairness—many applicants would receive lower risk scores if they belonged to a different racial group, even with all causally independent factors held constant.
-
Path-Specific Effects: Further analysis identified specific problematic pathways:
-
The direct path from race to risk score (explicit discrimination) was not significant, as race was excluded from the model features.
- A major source of unfairness came through the pathway: race → neighborhood → property value → collateral assessment → risk score.
- Another significant pathway was: race → neighborhood → historical lending patterns → credit score → risk score.
-
However, the pathway: race → education → income → debt-to-income ratio → risk score was deemed a legitimate predictive relationship by some stakeholders, as debt-to-income ratio directly relates to ability to repay.
-
Stakeholder Disagreement: There was significant debate about which pathways should be considered fair versus unfair. While some stakeholders argued that any influence of race on predictions should be eliminated, others maintained that certain indirect influences represent legitimate risk factors that should be preserved for accurate assessment.
From an intersectional perspective, the analysis revealed that the counterfactual unfairness was particularly pronounced for specific combinations of race and gender, with Black women experiencing unique patterns of disadvantage that weren't fully captured by examining race or gender separately.
Solution Implementation
To address the counterfactual fairness issues identified, the financial institution implemented a structured approach:
-
Pathway Classification: Through stakeholder consultation and regulatory guidance, they classified causal pathways into three categories:
-
Clearly unfair: Direct influence of race and pathways through variables with no plausible relation to repayment ability (e.g., neighborhood demographics unrelated to economic factors)
- Clearly fair: Pathways through variables directly related to repayment ability (e.g., current income relative to loan amount)
-
Contested: Pathways where stakeholders disagreed about fairness implications (e.g., education → income → repayment)
-
Implementation Strategy: Based on this classification, they developed a counterfactually fair model using a combination of approaches:
-
Fair representation learning: They transformed features to remove the influence of race along unfair pathways while preserving information flowing through legitimate pathways.
- Path-specific counterfactual fairness: For contested pathways, they implemented a relaxed fairness criterion that limited but didn't completely eliminate these influences.
-
Model constraints: They added explicit regularization terms to the training objective that penalized counterfactual unfairness.
-
Evaluation Framework: To assess the effectiveness of these interventions, they developed a comprehensive evaluation approach:
-
They measured counterfactual disparities before and after intervention, documenting substantial reductions in unfairness.
- They conducted path-specific effect analysis to verify that only problematic pathways were blocked.
- They compared model performance metrics to ensure that predictive accuracy for default risk remained strong.
- They implemented ongoing monitoring to track counterfactual fairness across demographic groups and intersections.
Throughout this process, they maintained transparent documentation of their causal assumptions, pathway classifications, and the rationale for specific interventions, creating accountability for fairness decisions.
Outcomes and Lessons
The counterfactual fairness implementation yielded several valuable outcomes:
- Targeted Improvements: By focusing on specific causal pathways rather than enforcing blanket statistical parity, they achieved significant fairness improvements while maintaining strong predictive performance.
- Regulatory Compliance: The causal approach provided a transparent and defensible framework for demonstrating compliance with fair lending requirements.
- Stakeholder Alignment: The explicit discussion of which causal pathways should be considered fair versus unfair created clearer alignment among stakeholders about fairness objectives.
- Intersectional Insights: The approach revealed and addressed unique patterns of disadvantage affecting specific intersectional groups that would have been missed by single-attribute analysis.
Key challenges included the difficulty of validating causal assumptions with limited experimental data and navigating disagreements about which causal pathways represented legitimate versus problematic influences.
The most generalizable lessons included:
- The importance of explicitly modeling and discussing which causal pathways should be considered fair versus unfair, rather than treating this as a purely technical question.
- The value of path-specific approaches that target problematic causal mechanisms while preserving legitimate predictive relationships.
- The necessity of involving diverse stakeholders in fairness decisions, particularly when classifying causal pathways.
These insights directly inform the development of the Causal Analysis Methodology in Unit 5, demonstrating how counterfactual fairness provides a more principled approach to addressing discrimination compared to purely statistical methods.
5. Frequently Asked Questions
FAQ 1: Counterfactual Fairness Vs. Statistical Fairness
Q: How does counterfactual fairness differ from traditional statistical fairness metrics, and when should I use each approach?
A: Counterfactual fairness differs from statistical fairness in three fundamental ways: First, counterfactual fairness examines individual-level "what if" scenarios rather than group-level statistics—asking whether specific individuals would receive different predictions if their protected attributes changed, while statistical metrics like demographic parity only compare aggregate outcomes across groups. Second, counterfactual fairness explicitly accounts for causal relationships by holding constant factors not causally dependent on protected attributes, while statistical metrics treat all correlations equally without distinguishing between legitimate and problematic associations. Third, counterfactual fairness can identify discrimination even when statistical metrics show no disparities (and vice versa), as the approaches measure fundamentally different properties.
You should consider counterfactual fairness when you need to distinguish between legitimate predictive relationships and problematic discrimination, particularly in domains where some influence of protected attributes may be considered acceptable while others are not. It's especially valuable when stakeholders disagree about what constitutes discrimination, as it provides a framework for explicit discussion of which causal pathways should be considered fair versus unfair. However, counterfactual fairness requires more domain knowledge to implement effectively, so statistical metrics may be more practical for initial screening or when causal relationships are highly uncertain. Ideally, use both approaches complementarily: statistical metrics to identify potential issues and counterfactual analysis to understand their causal mechanisms.
FAQ 2: Handling Uncertainty in Counterfactual Analysis
Q: How can I implement counterfactual fairness when I have limited confidence in my causal model or when stakeholders disagree about causal relationships?
A: Uncertainty in causal models is a common challenge that shouldn't prevent you from applying counterfactual fairness principles. Implement a systematic approach to handle this uncertainty: First, develop multiple plausible causal models representing different hypotheses about how variables relate, rather than assuming a single "true" model. Second, perform sensitivity analysis by evaluating counterfactual fairness across these different causal models to identify conclusions that remain consistent despite varying assumptions. Third, focus interventions on causal pathways that most stakeholders agree are problematic, while continuing to monitor and gather evidence about contested pathways. Fourth, implement relaxed or bounded notions of counterfactual fairness that acknowledge causal uncertainty by allowing for small violations when justified by limited evidence.
When stakeholders disagree about causal relationships, use this as an opportunity for productive discussion rather than an obstacle. Create explicit documentation of different causal hypotheses and their fairness implications, helping stakeholders understand how their different assumptions lead to different conclusions about what constitutes discrimination. When possible, collect additional data to test competing causal hypotheses, such as through natural experiments or targeted interventions. Remember that even imperfect causal reasoning often provides more nuanced fairness insights than purely statistical approaches, so don't let perfect be the enemy of good when implementing counterfactual fairness under uncertainty.
6. Project Component Development
Component Description
In Unit 5, you will develop the counterfactual fairness analysis section of the Causal Analysis Methodology. This component will provide a structured approach for formulating counterfactual queries, evaluating counterfactual fairness, and identifying which causal pathways require intervention based on counterfactual analysis.
The deliverable will take the form of an analysis template with counterfactual query formulation guidelines, pathway classification frameworks, and evaluation approaches that build on the causal models developed in previous Units.
Development Steps
- Create a Counterfactual Query Framework: Develop a structured approach for formulating relevant counterfactual questions based on the specific fairness concerns in your application. Include guidelines for determining which variables should remain constant in counterfactual scenarios and how to interpret the results.
- Build a Pathway Classification Template: Design a framework for categorizing causal pathways as fair or unfair based on ethical principles, domain knowledge, and stakeholder input. Include documentation templates for recording the rationale behind these classifications.
- Develop Counterfactual Evaluation Metrics: Create a set of metrics for quantifying counterfactual fairness violations, including measures of disparity between factual and counterfactual predictions and path-specific effect measures.
Integration Approach
This counterfactual fairness component will interface with other parts of the Causal Analysis Methodology by:
- Building on the causal models developed through the approaches from Unit 2.
- Providing counterfactual fairness criteria that guide intervention selection.
- Establishing evaluation metrics that assess whether interventions successfully eliminate unfair causal pathways.
- Creating outputs that inform which specific causal pathways require intervention, connecting directly to pre-processing, in-processing, or post-processing techniques.
To enable successful integration, maintain consistent notation across components, explicitly document assumptions about which causal pathways are considered fair versus unfair, and create clear connections between counterfactual analysis results and specific intervention recommendations.
7. Summary and Next Steps
Key Takeaways
This Unit has established counterfactual fairness as a powerful framework for evaluating whether AI systems exhibit causal discrimination. Key insights include:
- Counterfactual fairness provides a formal definition of fairness based on "what if" scenarios—asking whether predictions would change if an individual's protected attributes were different while all causally independent factors remained the same.
- Structural causal models enable us to generate meaningful counterfactuals by modeling the underlying data-generating process and simulating interventions on protected attributes.
- Path-specific approaches allow for nuanced fairness judgments by distinguishing between fair and unfair causal pathways from protected attributes to outcomes, preserving legitimate predictive relationships while blocking discriminatory influences.
- Implementing counterfactually fair models requires specific techniques like fair representation learning, constrained optimization, or causal inference-based approaches that address the specific causal mechanisms creating unfairness.
- Evaluating counterfactual fairness goes beyond traditional statistical metrics to measure whether models satisfy counterfactual fairness criteria and quantify the contribution of different causal pathways to observed disparities.
These concepts directly address our guiding questions by providing a formal framework for evaluating fairness through causal "what if" scenarios and establishing criteria for when predictions are counterfactually fair.
Application Guidance
To apply these concepts in your practical work:
- Start by developing a causal model of your application domain, identifying how protected attributes influence other variables and ultimately predictions.
- Formulate specific counterfactual queries relevant to your fairness concerns, focusing on whether predictions would change under different protected attribute values.
- Classify causal pathways as fair or unfair based on domain knowledge, ethical principles, and stakeholder input, explicitly documenting the rationale for these classifications.
- Select appropriate implementation approaches based on the specific counterfactual fairness violations identified, targeting the problematic causal pathways while preserving legitimate predictive relationships.
- Evaluate your interventions using both counterfactual fairness metrics and traditional performance measures to ensure you're effectively addressing discrimination without unnecessarily sacrificing utility.
If you're new to counterfactual fairness, start with simple causal models and straightforward counterfactual queries before progressing to more complex path-specific analyses. Even basic counterfactual reasoning can provide valuable insights beyond purely statistical approaches.
Looking Ahead
In the next Unit, we will address the practical challenges of causal inference with limited data and knowledge. You will learn techniques for causal discovery from observational data, approaches for handling unmeasured confounding, and methods for conducting sensitivity analysis when causal assumptions are uncertain.
The counterfactual fairness framework you've learned in this Unit provides the theoretical foundation for these practical inference approaches. By understanding what counterfactual fairness means conceptually and mathematically, you're now prepared to explore how to implement these ideas in real-world scenarios where perfect causal knowledge is rarely available.
References
Black, E., Yeom, S., & Fredrikson, M. (2020). FlipTest: Fairness testing via optimal transport. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency (pp. 111-121). https://doi.org/10.1145/3351095.3372845
Chiappa, S. (2019). Path-specific counterfactual fairness. In Proceedings of the AAAI Conference on Artificial Intelligence, 33(01), 7801-7808. https://doi.org/10.1609/aaai.v33i01.33017801
Chiappa, S., & Isaac, W. S. (2019). A causal Bayesian networks viewpoint on fairness. In Explainable and Interpretable Models in Computer Vision and Machine Learning (pp. 3-23). Springer. https://doi.org/10.1007/978-3-030-28954-6_1
Chiappa, S., Jiang, R., Stepleton, T., Pacchiano, A., Jiang, H., & Aslanides, J. (2020). General counterfactual fairness. In Proceedings of the AAAI Conference on Artificial Intelligence, 34(04), 3629-3636. https://doi.org/10.1609/aaai.v34i04.5865
Crenshaw, K. (1989). Demarginalizing the intersection of race and sex: A black feminist critique of antidiscrimination doctrine, feminist theory, and antiracist politics. University of Chicago Legal Forum, 1989(1), 139-167.
Kusner, M. J., Loftus, J., Russell, C., & Silva, R. (2017). Counterfactual fairness. In Advances in Neural Information Processing Systems (pp. 4066-4076). https://proceedings.neurips.cc/paper/2017/file/a486cd07e4ac3d270571622f4f316ec5-Paper.pdf
Pearl, J. (2009). Causality: Models, reasoning and inference (2nd ed.). Cambridge University Press. https://doi.org/10.1017/CBO9780511803161
Russell, C., Kusner, M. J., Loftus, J., & Silva, R. (2017). When worlds collide: Integrating different counterfactual assumptions in fairness. In Advances in Neural Information Processing Systems (pp. 6414-6423).
Wu, Y., Zhang, L., & Wu, X. (2019). Counterfactual fairness: Unidentification, bound and algorithm. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (pp. 1438-1444). https://doi.org/10.24963/ijcai.2019/199
Yang, K., Loftus, J. R., & Stoyanovich, J. (2020). Causal intersectionality for fair ranking. arXiv preprint arXiv:2006.08688. https://arxiv.org/abs/2006.08688
Unit 4
Unit 4: Causal Inference With Limited Data
1. Conceptual Foundation and Relevance
Guiding Questions
- Question 1: How can we apply causal reasoning to fairness problems when we have incomplete knowledge of the true causal structure or limited experimental data?
- Question 2: What practical methods allow us to estimate causal effects and implement counterfactual fairness when ideal conditions for causal inference are not met?
Conceptual Context
The previous Units have established the theoretical foundations of causal fairness, demonstrating how causal models can distinguish between different discrimination mechanisms and how counterfactual reasoning provides a principled approach to fairness assessment. However, in real-world machine learning applications, we rarely have perfect knowledge of causal structures or access to ideal experimental data that would allow straightforward causal inference.
This gap between theoretical causal frameworks and practical limitations represents one of the most significant challenges in implementing causal fairness approaches. As Pearl (2019) notes, "The fundamental problem of causal inference is that we can never observe the outcome of both treatment and non-treatment on the same individual." This missing counterfactual data problem is particularly acute in fairness applications, where we cannot observe how individuals would have been treated if their protected attributes were different.
Understanding practical approaches to causal inference with limited data is essential because without these methods, the causal frameworks explored in previous Units would remain largely theoretical. By developing techniques to estimate causal effects despite practical constraints, you will be able to translate causal fairness principles into implementable interventions rather than merely aspirational goals.
This Unit builds directly on the causal modeling approaches from Unit 2 and counterfactual framework from Unit 3, showing how to apply these concepts when dealing with real-world limitations. The practical inference techniques you'll learn here will directly inform the Causal Analysis Methodology you'll develop in Unit 5, ensuring that your methodology can be applied in realistic settings where causal knowledge and experimental data are inevitably limited.
2. Key Concepts
The Fundamental Challenge of Causal Inference
The fundamental challenge of causal inference stems from our inability to simultaneously observe contradictory states of reality—we cannot observe both what happened and what would have happened if conditions were different. This limitation is essential to understand in AI fairness because it means that true counterfactual fairness can never be directly measured but must be estimated through various inference techniques.
This concept is directly relevant to the fairness context because counterfactual fairness asks whether an individual would have received the same prediction if their protected attribute were different. Since we never observe the same individual with different protected attributes, we must develop methods to estimate these counterfactual outcomes.
Pearl's framework of the "ladder of causation" (Pearl & Mackenzie, 2018) helps contextualize this challenge by distinguishing between three levels of causal reasoning:
- Association (observing correlations)
- Intervention (predicting effects of actions)
- Counterfactuals (imagining alternative realities)
Each level represents increasing causal knowledge and more challenging inference requirements. Fairness applications often require reasoning at the counterfactual level, the most demanding form of causal inference.
For example, in a hiring algorithm, we might observe that women receive lower scores than men with similar observable qualifications. Counterfactual fairness requires determining whether a specific woman would have received the same score if she were a man, with all causally unrelated attributes remaining identical—a question that cannot be directly answered through observation alone.
For the Causal Analysis Methodology we'll develop in Unit 5, understanding this fundamental challenge is critical because it establishes realistic expectations about what can be inferred from available data and highlights the importance of combining data-driven inference with domain knowledge to address inherent limitations.
Observational Causal Inference Methods
When experimental intervention isn't possible—as is often the case in fairness applications—we must rely on observational methods to estimate causal effects from non-experimental data. These methods are crucial for AI fairness because they allow us to approximate counterfactual outcomes without the ability to manipulate protected attributes experimentally.
These observational methods build on the fundamental causal inference challenge by providing practical approaches to estimate causal effects despite the limitations of observational data. They interact with fairness applications by enabling the implementation of counterfactual fairness principles in real-world systems where experimental data about protected attributes is unavailable or unethical to collect.
Several key techniques have been developed for observational causal inference:
- Matching methods attempt to mimic experimental conditions by comparing outcomes for individuals with similar characteristics but different protected attributes. For instance, Rubin's (2006) approach to causal inference uses propensity score matching to estimate treatment effects by comparing similar individuals who received different "treatments" (in fairness contexts, having different protected attributes).
- Instrumental variable (IV) approaches leverage external variables that influence the protected attribute but affect outcomes only through that attribute. As explained by Angrist and Pischke (2008), this approach can help identify causal effects when randomized experiments aren't possible. For example, historical policy changes that affected educational access for certain demographic groups might serve as instruments for estimating the causal effect of education on employment outcomes.
- Regression discontinuity designs exploit threshold-based policies or natural boundaries to approximate experimental conditions. This approach, formalized by Imbens and Lemieux (2008), compares individuals just above and below thresholds, assuming they are otherwise similar. In fairness applications, this might involve examining outcomes for individuals near threshold scores or policy boundaries.
- Difference-in-differences methods compare outcome changes over time between groups affected and unaffected by a change, as described by Card and Krueger (1994). This approach might be used to estimate the causal effect of a policy or intervention on fairness outcomes by comparing changes before and after implementation.
For our Causal Analysis Methodology, these observational methods provide practical tools for estimating counterfactual outcomes when experimental data is unavailable, enabling the application of causal fairness principles despite real-world constraints.
Sensitivity Analysis for Unmeasured Confounding
In real-world applications, we rarely measure all relevant variables that might confound the relationship between protected attributes and outcomes. Sensitivity analysis provides a framework for assessing how robust causal conclusions are to potential unmeasured confounding. This concept is essential for AI fairness because it helps quantify uncertainty in causal estimates and prevents overconfidence in fairness assessments based on incomplete causal models.
This sensitivity analysis builds on observational causal inference methods by acknowledging their limitations and providing approaches to quantify the robustness of their conclusions. It interacts with fairness applications by enabling practitioners to communicate the degree of confidence they have in causal fairness assessments and identify when additional data or stronger assumptions might be necessary.
VanderWeele and Ding (2017) developed the E-value approach, which quantifies how strong an unmeasured confounder would need to be to nullify an observed causal effect. This method provides a simple metric for assessing the robustness of causal conclusions without specifying the exact nature of potential unmeasured confounders.
For example, when applying counterfactual fairness to a hiring algorithm, sensitivity analysis might reveal that the estimated effect of gender on hiring recommendations would be eliminated only if there existed an unmeasured confounder that was strongly associated with both gender and hiring potential. If such a strong confounder seems implausible based on domain knowledge, we gain confidence in our causal conclusions despite incomplete measurement.
For our Causal Analysis Methodology, sensitivity analysis will provide essential tools for acknowledging and quantifying the uncertainty in causal fairness assessments, enabling practitioners to make responsible claims about fairness properties despite the inevitable limitations of real-world causal knowledge.
Causal Discovery From Observational Data
While previous Units assumed that causal structures were known from domain expertise, causal discovery algorithms attempt to infer causal relationships directly from observational data. These methods are valuable for AI fairness because they can help identify potential causal pathways when domain knowledge is limited or confirm hypothesized causal structures with empirical evidence.
Causal discovery connects to sensitivity analysis by potentially reducing the reliance on unmeasured confounders, as it attempts to infer a more complete causal model from available data. It interacts with fairness applications by helping identify potential discrimination mechanisms that might not be apparent from domain knowledge alone.
Several approaches to causal discovery have been developed:
- Constraint-based methods like the PC algorithm (Spirtes et al., 2000) infer causal structures by testing conditional independence relationships in the data. These methods can identify the presence and direction of causal relationships under certain assumptions.
- Score-based methods search through possible causal structures to find those that best fit the observed data while maintaining simplicity. As explained by Chickering (2002), these approaches balance model fit against complexity to avoid overfitting.
- Hybrid methods combine elements of constraint-based and score-based approaches to leverage their respective strengths. The Fast Causal Inference (FCI) algorithm, for instance, extends constraint-based methods to handle latent confounders (Spirtes et al., 2000).
In fairness applications, Zhang et al. (2017) demonstrated how causal discovery could help identify discrimination mechanisms in hiring data, revealing causal pathways that might not have been apparent from domain knowledge alone. Their approach identified specific features that served as proxies for protected attributes, enabling targeted interventions.
For our Causal Analysis Methodology, causal discovery provides complementary tools to domain expertise for identifying potential causal structures, particularly when domain knowledge is limited or when empirical confirmation of hypothesized causal relationships is desired.
Domain Adaptation for Causal Generalization
Machine learning systems often operate in environments that differ from their training contexts, raising questions about how causal relationships generalize across domains. Domain adaptation for causal inference addresses how to transfer causal knowledge across different populations or environments. This concept is crucial for AI fairness because fairness properties based on causal understanding must remain valid when systems are deployed in new contexts with potentially different causal structures.
This domain adaptation builds on all previous causal inference concepts by addressing their external validity—whether causal conclusions drawn in one context apply in different environments. It interacts with fairness applications by ensuring that fairness guarantees based on causal understanding remain valid when systems are deployed across diverse contexts.
Bareinboim and Pearl (2016) developed a formal framework for transportability of causal effects across domains, identifying when and how causal knowledge can be transferred. Their approach uses "selection diagrams" to represent differences in causal mechanisms between source and target domains, enabling systematic reasoning about generalizability.
For instance, a hiring algorithm developed with causal fairness guarantees in one country might face different causal structures when deployed internationally due to varying educational systems, labor markets, or social norms. Domain adaptation helps identify which causal relationships might differ across contexts and adjust fairness assessments accordingly.
For our Causal Analysis Methodology, domain adaptation will provide frameworks for reasoning about how causal fairness properties generalize across different contexts, enabling more robust fairness guarantees that remain valid despite variations in deployment environments.
Domain Modeling Perspective
From a domain modeling perspective, causal inference with limited data connects to specific components of ML systems:
- Problem Formulation: Causal inference limitations influence how fairness objectives should be defined, potentially necessitating multiple complementary definitions to address inherent uncertainties.
- Data Collection: Understanding causal inference challenges should inform strategic data collection efforts, prioritizing variables that help distinguish between plausible causal structures.
- Feature Engineering: Causal inference methods can guide feature selection and transformation to improve the identifiability of causal effects relevant to fairness.
- Model Selection: Different modeling approaches may facilitate or hinder causal inference, influencing architecture choices when fairness is a primary concern.
- Evaluation Framework: Limitations in causal knowledge should be reflected in evaluation procedures, potentially through ensemble methods that combine multiple causal assumptions.
This domain mapping helps situate causal inference challenges within the ML development process, highlighting where and how these limitations influence fairness-oriented decisions throughout the pipeline.

Conceptual Clarification
To clarify these abstract causal inference concepts, consider the following analogies:
- The fundamental challenge of causal inference is like trying to determine whether taking an umbrella prevents rain. You never observe both outcomes simultaneously—when you take an umbrella, you can't observe whether it would have rained had you not taken it, and vice versa. This "missing counterfactual" problem means you can never directly measure the causal effect of umbrella-carrying on rainfall. Similarly, in fairness applications, we never simultaneously observe how an individual would be treated with different protected attributes, making direct measurement of discrimination impossible and requiring indirect inference methods.
- Observational causal inference methods function like detectives solving a crime without witnessing it. Detectives use fingerprints, witness statements, and circumstantial evidence to reconstruct what likely happened despite not directly observing the crime. Similarly, methods like matching and instrumental variables use patterns in observational data to approximate what would have been observed in an ideal experiment, allowing us to estimate causal effects despite never directly observing counterfactual outcomes.
- Sensitivity analysis for unmeasured confounding resembles stress-testing a bridge. Engineers calculate how strong a storm would need to be to compromise the bridge's stability, without knowing exactly what future storms will occur. Similarly, sensitivity analysis calculates how strong unmeasured confounders would need to be to invalidate causal conclusions, providing confidence in those conclusions when such strong confounding seems implausible without specifying exactly what unmeasured variables might exist.
- Causal discovery algorithms are like astronomers inferring the existence of planets by observing the wobble of stars. Just as astronomers can detect unseen planets through their gravitational effects on visible stars, causal discovery algorithms infer causal relationships by analyzing patterns of association in data, potentially revealing causal structures that weren't directly observed or hypothesized through domain knowledge alone.
Intersectionality Consideration
Causal inference challenges become particularly acute when addressing intersectional fairness, where multiple protected attributes interact to create unique patterns of discrimination. Traditional causal inference methods often struggle with the "curse of dimensionality" when examining intersectional effects, as the available data becomes increasingly sparse at specific demographic intersections.
Crenshaw's (1989) foundational work on intersectionality emphasized that discrimination often operates through mechanisms specific to particular intersections of identity characteristics. For causal fairness, this means that causal structures may differ not just across individual protected attributes but also at their intersections, creating complex patterns that are difficult to infer from limited data.
Recent work by Yang et al. (2020) has begun addressing these challenges through hierarchical modeling approaches that leverage similarities across related intersectional groups to improve inference despite data limitations. Their work demonstrates how Bayesian methods can be particularly valuable for intersectional causal inference, as they provide formal frameworks for incorporating prior knowledge and sharing statistical strength across related groups.
For instance, when examining hiring discrimination, we might have limited data for specific intersections like "older women from minority backgrounds." Hierarchical Bayesian approaches allow borrowing statistical strength from related groups (e.g., "women," "minority candidates," "older workers") while still capturing unique intersectional effects when sufficient evidence exists in the data.
For our Causal Analysis Methodology, addressing these intersectional challenges requires:
- Explicit consideration of how causal structures might vary across demographic intersections.
- Incorporation of hierarchical modeling approaches that balance detecting unique intersectional effects against statistical reliability.
- Careful uncertainty quantification that acknowledges the increased inferential challenges at demographic intersections.
- Transparent communication about the limitations of causal inference for specific intersectional groups with limited representation in available data.
3. Practical Considerations
Implementation Framework
To effectively apply causal inference with limited data, implement this structured methodology:
-
Causal Knowledge Assessment and Integration:
-
Conduct a systematic inventory of available causal knowledge from domain expertise, literature, and stakeholder input.
- Identify critical gaps and uncertainties in causal understanding.
- Develop a structured approach for integrating causal knowledge with available data, using domain expertise to guide model specification.
-
Document causal assumptions explicitly, including their sources and confidence levels.
-
Appropriate Method Selection:
-
Select inference methods based on data characteristics and available knowledge:
- Use matching or propensity score methods when rich covariate data is available.
- Apply instrumental variable approaches when valid instruments can be identified.
- Consider regression discontinuity when threshold-based policies create natural experiments.
- Implement difference-in-differences when longitudinal data spans policy changes.
- Combine multiple complementary methods when possible to assess consistency of conclusions.
-
Document method selection rationale, including why certain approaches were chosen over alternatives.
-
Uncertainty Quantification and Sensitivity Analysis:
-
Implement formal sensitivity analysis to quantify robustness to unmeasured confounding.
- Calculate E-values or similar metrics to assess how strong unmeasured confounders would need to be to change conclusions.
- Consider multiple plausible causal models rather than committing to a single structure.
- Develop bounded estimates that acknowledge inherent uncertainties rather than point estimates.
- Clearly communicate uncertainty in causal conclusions to stakeholders.
These methodologies integrate with standard ML workflows by informing feature selection, model specification, and evaluation procedures. While they add analytical complexity, these approaches help ensure that fairness assessments acknowledge the limitations of causal inference rather than making overconfident claims based on incomplete information.
Implementation Challenges
When implementing causal inference methods with limited data, practitioners commonly face these challenges:
-
Balancing Domain Knowledge with Data-Driven Approaches: Purely data-driven causal discovery may suggest implausible structures, while rigid adherence to prior knowledge might miss unexpected relationships. Address this by:
-
Implementing hybrid approaches that incorporate domain knowledge as "soft" constraints rather than rigid assumptions.
- Using domain expertise to guide model specification while allowing data to refine or challenge initial assumptions.
- Developing structured processes for resolving conflicts between domain knowledge and empirical findings.
-
Creating explicit documentation of where causal understanding derives from expertise versus data-driven inference.
-
Managing Stakeholder Expectations About Causal Certainty: Stakeholders may expect definitive answers about discrimination that causal inference with limited data cannot provide. Address this by:
-
Educating stakeholders about the fundamental limitations of causal inference from observational data.
- Developing visualization approaches that effectively communicate uncertainty in causal conclusions.
- Presenting ranges or bounds of potential effects rather than point estimates when appropriate.
- Framing fairness interventions as risk management strategies even when causal certainty is limited.
Successfully implementing these approaches requires resources including expertise in causal inference methods, computational tools for sensitivity analysis and uncertainty quantification, and organizational willingness to acknowledge and work with inherent limitations in causal knowledge rather than demanding unrealistic certainty.
Evaluation Approach
To assess whether your causal inference approaches with limited data are effective, implement these evaluation strategies:
-
Consistency Assessment Across Methods:
-
Apply multiple causal inference methods with different assumptions to the same problem.
- Evaluate consistency of conclusions across methodological approaches.
- Identify conditions under which different methods produce divergent results.
-
Document where causal conclusions are robust across methods versus sensitive to methodological choices.
-
Predictive Validation Where Possible:
-
Test causal models' ability to predict outcomes under interventions when validation data is available.
- Use natural experiments or policy changes as opportunities to validate causal models.
- Implement prospective validation when possible, designing data collection to test causal predictions.
- Assess whether interventions based on causal understanding produce expected fairness improvements.
These evaluation approaches should be integrated with your organization's broader fairness assessment framework, providing deeper insights into the reliability of causal conclusions while acknowledging the inherent limitations of causal inference with observational data.
4. Case Study: Criminal Risk Assessment Algorithm
Scenario Context
A criminal justice agency is developing a risk assessment algorithm to predict recidivism risk for individuals awaiting trial, with predictions informing pre-trial detention decisions. Initial analysis shows significant racial disparities in predicted risk scores, with Black defendants receiving higher average risk predictions than white defendants with similar observable case characteristics.
Agency data scientists must determine whether these disparities represent algorithmic discrimination requiring intervention, or whether they reflect legitimate risk factors that happen to correlate with race. This determination requires causal understanding, but the team faces significant causal inference challenges: they cannot conduct randomized experiments assigning race to defendants, they have limited information about potential confounders, and the historical data reflects past discriminatory practices in the criminal justice system.
Key stakeholders include judges using the risk predictions, defendants whose liberty is at stake, communities affected by both crime and mass incarceration, and public officials concerned with both system fairness and public safety. The fairness implications are significant given the fundamental rights at stake and the historical context of racial discrimination in criminal justice.
Problem Analysis
Applying causal inference concepts reveals several challenges in this scenario:
- The Fundamental Challenge: The team cannot observe the counterfactual scenario of how a Black defendant would have been assessed if they were white with identical relevant characteristics. This missing counterfactual problem is the core challenge in determining whether the algorithm exhibits racial discrimination.
- Observational Methods Application: Initial analysis attempted to use matching methods, comparing Black and white defendants with similar observed characteristics. However, this approach assumes no unmeasured confounding—that all variables affecting both race and recidivism risk are measured—an assumption likely violated in this context.
- Unmeasured Confounding Concerns: Several potential unmeasured confounders could affect both race and recidivism risk due to structural inequalities, including neighborhood characteristics, quality of prior legal representation, and economic opportunities. Without measuring these factors, causal conclusions about discrimination remain uncertain.
- Causal Discovery Limitations: Attempts to use causal discovery algorithms revealed multiple plausible causal structures consistent with the observed data, some suggesting discrimination and others suggesting legitimate risk assessment, highlighting the limits of purely data-driven approaches in this context.
- Domain Adaptation Issues: The agency discovered that risk factors predict recidivism differently across jurisdictions with varying policing practices, raising questions about how causal relationships might vary across contexts and over time as policies change.
From an intersectional perspective, the analysis becomes more complex. The team found that the algorithm's performance varied not just by race but showed unique patterns for specific combinations of race, gender, age, and socioeconomic status. For example, young Black men from lower-income neighborhoods faced particularly elevated risk predictions that couldn't be explained by observable case characteristics. These intersectional effects create additional causal inference challenges due to smaller sample sizes at specific demographic intersections.
Solution Implementation
To address these causal inference challenges, the team implemented a comprehensive approach:
-
Multiple Complementary Methods: Rather than relying on a single inference method, they applied:
-
Matching methods comparing similar defendants across racial groups.
- Instrumental variable analysis using random judge assignment as an instrument (some judges being more likely to detain defendants pre-trial than others).
- Difference-in-differences analysis examining how disparities changed after policy reforms in certain jurisdictions.
This multi-method approach helped assess the consistency of conclusions across different causal inference techniques.
-
Sensitivity Analysis: They implemented formal sensitivity analysis to quantify how strong unmeasured confounding would need to be to explain the observed racial disparities:
-
Calculated E-values showing that unmeasured confounders would need to be associated with both race and recidivism with risk ratios of at least 2.5 to explain the observed disparities.
- Developed bounds on potential discrimination effects under different assumptions about unmeasured confounding strength.
-
Created visualization tools showing how conclusions would change under different confounding scenarios.
-
Domain Knowledge Integration: They enhanced data-driven approaches with structured incorporation of domain expertise:
-
Collaborated with sociologists, criminologists, and community representatives to develop more comprehensive causal models.
- Used expert knowledge to identify critical unmeasured variables and potential proxy measures.
-
Created a structured process for updating causal understanding as new evidence emerged.
-
Hierarchical Modeling for Intersectionality: To address intersectional challenges with limited data, they implemented:
-
Bayesian hierarchical models that borrowed statistical strength across related demographic groups while allowing for unique intersectional effects.
- Explicit documentation of increased uncertainty in causal estimates for smaller intersectional groups.
- Prioritized data collection to better understand specific intersectional effects where evidence suggested unique patterns.
This multi-faceted approach allowed the team to navigate the inherent limitations of causal inference with the available data while still developing actionable insights about potential discrimination in the algorithm.
Outcomes and Lessons
The causal inference approach yielded several key insights despite data limitations:
- It revealed that approximately 30-40% of the observed racial disparity in risk scores could be attributed to direct or proxy discrimination, with bounds reflecting remaining uncertainty.
- It identified specific variables, like arrest history and neighborhood characteristics, that functioned as problematic proxies for race in the predictive model.
- It demonstrated unique intersectional effects, with particularly problematic predictions for young Black men that couldn't be explained by legitimate risk factors.
The most significant limitations included the inability to completely rule out unmeasured confounding and the challenge of distinguishing between variables that are legitimate predictors versus proxies for protected attributes.
Key generalizable lessons included:
- The importance of applying multiple complementary causal inference methods rather than relying on a single approach.
- The value of explicit uncertainty quantification through sensitivity analysis rather than presenting causal conclusions as definitive.
- The necessity of combining data-driven approaches with domain expertise, especially for interpreting which causal pathways represent legitimate prediction versus problematic discrimination.
- The critical role of intersectional analysis in identifying unique patterns of algorithmic discrimination that might be missed by aggregated analysis.
These insights directly inform the development of the Causal Analysis Methodology in Unit 5, demonstrating how causal inference methods can provide valuable insights about discrimination despite inherent limitations in available data and causal knowledge.
5. Frequently Asked Questions
FAQ 1: Required Data for Causal Inference
Q: What minimum data requirements must I meet to apply causal inference methods for fairness analysis?
A: There's no universal minimum dataset size for causal inference, as requirements depend on your specific causal questions and methods. However, several key considerations can guide your assessment: First, statistical power for detecting causal effects varies based on effect size—smaller discrimination effects require larger samples. For typical fairness applications, hundreds of observations may be sufficient for detecting large effects, while thousands or more may be needed for subtle effects. Second, representation matters more than raw size—ensure sufficient data for each demographic group of interest, particularly at intersections. Third, variable coverage is critical—the more potential confounders you measure, the more credible your causal claims. Fourth, consider temporal aspects—longitudinal data capturing policy changes or interventions enables more robust causal designs like difference-in-differences. Rather than focusing solely on sample size, assess whether your data allows distinguishing between plausible alternative causal explanations for observed disparities. When data is limited, explicitly quantify uncertainty through sensitivity analysis and bounds rather than presenting point estimates, and consider collecting additional data on key variables identified through domain expertise as potential confounders or instruments.
FAQ 2: Incorporating Uncertainty in Decision-Making
Q: How should we make fairness-related decisions when causal inference yields uncertain conclusions about discrimination?
A: Uncertainty in causal inference doesn't preclude action but should inform your decision-making approach. First, adopt a risk management framework rather than seeking absolute certainty—quantify potential discrimination under different plausible scenarios and assess the consequences of both false positives (implementing unnecessary interventions) and false negatives (failing to address real discrimination). Second, implement tiered interventions based on confidence levels—where evidence of discrimination is strongest, apply more aggressive interventions; where uncertainty is higher, implement monitoring and less disruptive interventions. Third, design robust interventions that improve fairness across multiple plausible causal scenarios rather than optimizing for a single assumed causal structure. Fourth, implement continuous monitoring and adaptive approaches that can adjust as new evidence emerges. Fifth, maintain transparency about uncertainty in your documentation, communicating both what you know and what remains uncertain. Finally, consider legal and ethical perspectives—in high-stakes domains affecting fundamental rights, you may need to act preventively even when causal certainty is limited. Remember that uncertainty about discrimination is not equivalent to evidence against discrimination—absence of conclusive evidence is not evidence of absence, particularly when data limitations constrain causal inference capabilities.
6. Project Component Development
Component Description
In Unit 5, you will develop the practical inference section of the Causal Analysis Methodology. This component will provide structured approaches for applying causal inference techniques when perfect causal knowledge and ideal experimental data are unavailable, as is typically the case in real-world fairness applications.
Your deliverable will include practical guidance for selecting appropriate inference methods based on available data and knowledge, implementing sensitivity analysis to quantify uncertainty, and interpreting results responsibly given inherent limitations in causal inference.
Development Steps
- Create a Method Selection Framework: Develop decision criteria for choosing among observational causal inference methods (matching, instrumental variables, regression discontinuity, difference-in-differences) based on data characteristics and available knowledge. Include guidance on when each method is most appropriate and what assumptions each requires.
- Build a Sensitivity Analysis Approach: Design structured procedures for quantifying the robustness of causal conclusions to potential unmeasured confounding. Include templates for calculating E-values or similar metrics and interpreting their implications for fairness assessments.
- Develop an Uncertainty Communication Framework: Create guidelines and visualization approaches for effectively communicating uncertainty in causal conclusions to both technical and non-technical stakeholders. Include templates for presenting bounded estimates rather than point estimates when appropriate.
Integration Approach
This practical inference component will interface with other parts of the Causal Analysis Methodology by:
- Building on the causal models developed through the methodology from Unit 2, showing how to estimate causal effects when perfect knowledge of these models is unavailable.
- Supporting the counterfactual analysis from Unit 3 by providing practical approaches for estimating counterfactual outcomes despite missing data.
- Connecting to the intervention selection components by acknowledging how causal uncertainty should influence intervention choices.
To enable successful integration, use consistent terminology across components, explicitly document assumptions and limitations, and create clear connections between the idealized causal frameworks and practical inference approaches.
7. Summary and Next Steps
Key Takeaways
This Unit has explored the practical challenges of causal inference with limited data and the methodologies for addressing them in fairness applications. Key insights include:
- The fundamental challenge of causal inference stems from our inability to observe counterfactual outcomes—we never see how the same individual would have been treated with different protected attributes. This missing counterfactual problem necessitates indirect approaches to estimating causal effects in fairness applications.
- Observational causal inference methods provide tools for estimating causal effects from non-experimental data. Techniques like matching, instrumental variables, regression discontinuity, and difference-in-differences help approximate experimental conditions when randomized experiments aren't possible or ethical.
- Sensitivity analysis for unmeasured confounding enables quantification of how robust causal conclusions are to potential unmeasured variables. Methods like E-values help assess whether observed disparities could be explained by confounding or likely represent genuine discrimination.
- Causal discovery algorithms can help identify potential causal structures from observational data, complementing domain expertise when causal knowledge is limited. These methods can reveal unexpected causal pathways that might contribute to unfair outcomes.
- Domain adaptation frameworks address how causal relationships generalize across different contexts, ensuring that fairness guarantees based on causal understanding remain valid when systems are deployed in new environments.
These concepts directly address our guiding questions by providing practical approaches to apply causal reasoning despite incomplete knowledge and limited data, enabling the implementation of counterfactual fairness principles in realistic settings.
Application Guidance
To apply these concepts in your practical work:
- Begin by acknowledging the inherent limitations of causal inference with observational data rather than seeking unrealistic certainty.
- Select appropriate inference methods based on your specific data characteristics and available domain knowledge, using multiple complementary approaches when possible.
- Implement formal sensitivity analysis to quantify the robustness of your conclusions to potential unmeasured confounding.
- Communicate uncertainty explicitly in your fairness assessments, presenting bounds or ranges rather than point estimates when appropriate.
- Integrate causal inference results with domain expertise, using expert knowledge to interpret causal pathways and distinguish between legitimate prediction and problematic discrimination.
If you're new to causal inference, start with simpler methods like matching or difference-in-differences before attempting more complex approaches. Focus on developing intuition about what causal questions can and cannot be answered with your available data, and be transparent about limitations rather than overstating causal certainty.
Looking Ahead
In the next Unit, we will synthesize all the causal concepts explored throughout this Part into a comprehensive Causal Analysis Methodology. You will develop a structured approach for analyzing the causal mechanisms of unfairness in AI systems and identifying appropriate intervention points based on causal understanding.
The practical inference techniques you've learned in this Unit will be crucial for ensuring that your methodology can be applied in realistic settings where causal knowledge and experimental data are inevitably limited. By incorporating these practical approaches, you'll create a methodology that acknowledges and works with real-world constraints rather than assuming idealized conditions.
References
Angrist, J. D., & Pischke, J. S. (2008). Mostly harmless econometrics: An empiricist's companion. Princeton University Press.
Bareinboim, E., & Pearl, J. (2016). Causal inference and the data-fusion problem. Proceedings of the National Academy of Sciences, 113(27), 7345-7352. https://doi.org/10.1073/pnas.1510507113
Card, D., & Krueger, A. B. (1994). Minimum wages and employment: A case study of the fast-food industry in New Jersey and Pennsylvania. The American Economic Review, 84(4), 772-793.
Chickering, D. M. (2002). Optimal structure identification with greedy search. Journal of Machine Learning Research, 3(Nov), 507-554.
Crenshaw, K. (1989). Demarginalizing the intersection of race and sex: A black feminist critique of antidiscrimination doctrine, feminist theory and antiracist politics. University of Chicago Legal Forum, 1989(1), 139-167.
Imbens, G. W., & Lemieux, T. (2008). Regression discontinuity designs: A guide to practice. Journal of Econometrics, 142(2), 615-635. https://doi.org/10.1016/j.jeconom.2007.05.001
Pearl, J. (2019). The seven tools of causal inference, with reflections on machine learning. Communications of the ACM, 62(3), 54-60. https://doi.org/10.1145/3241036
Pearl, J., & Mackenzie, D. (2018). The book of why: The new science of cause and effect. Basic Books.
Rubin, D. B. (2006). Matched sampling for causal effects. Cambridge University Press. https://doi.org/10.1017/CBO9780511810725
Spirtes, P., Glymour, C. N., Scheines, R., & Heckerman, D. (2000). Causation, prediction, and search. MIT Press.
VanderWeele, T. J., & Ding, P. (2017). Sensitivity analysis in observational research: Introducing the E-value. Annals of Internal Medicine, 167(4), 268-274. https://doi.org/10.7326/M16-2607
Yang, K., Loftus, J. R., & Stoyanovich, J. (2020). Causal intersectionality for fair ranking. arXiv preprint arXiv:2006.08688. https://arxiv.org/abs/2006.08688
Zhang, K., Schölkopf, B., Spirtes, P., & Glymour, C. (2017). Learning causality and causality-related learning: some recent progress. National Science Review, 5(1), 26-29. https://doi.org/10.1093/nsr/nwx137
Unit 5
Unit 5: Causal Fairness Toolkit
1. Introduction
In Part 1, you learned about the distinction between correlation and causation in fairness contexts, how to build causal models, the counterfactual fairness framework, and practical causal inference with limited data. Now it's time to apply these insights. You'll develop a practical tool that helps engineering teams identify causal mechanisms of unfairness and determine appropriate intervention points. The Causal Fairness Toolkit you'll create will serve as the first component of the Sprint 2 Project - Fairness Intervention Playbook, ensuring that fairness interventions address root causes rather than merely symptoms of bias.
2. Context
Imagine you are a staff engineer at a mid-sized bank implementing a machine learning system for loan approval decisions. The system will analyze applicant data including credit history, income, debt-to-income ratio, employment history, and property value to predict default risk. Based on this risk assessment, the system will either approve or deny loan applications.
A preliminary analysis revealed concerning patterns: the model approves loans for male applicants at significantly higher rates than for similarly qualified female applicants. The bank's data science team suspects this disparity stems from historical lending practices reflected in their training data. They've approached you for help.
Through initial discussions, you determine the team needs to understand whether the disparity stems from direct discrimination, proxy discrimination through seemingly neutral variables, or legitimate risk factors that happen to correlate with gender. You agree to develop a causal analysis toolkit to help them identify the underlying mechanisms creating unfairness. This will guide their selection of appropriate interventions.
You recognize that this challenge extends beyond this single project. You'll build a "Causal Fairness Toolkit" that any team can use to systematically analyze the causal mechanisms of unfairness in their AI applications.
3. Objectives
By completing this project component, you will practice:
- Translating abstract causal concepts into practical analytical procedures.
- Creating templates for causal modeling in fairness contexts.
- Developing counterfactual analysis frameworks to evaluate causal discrimination.
- Mapping causal patterns to appropriate intervention types.
- Designing approaches for causal analysis under uncertainty and limited information.
- Balancing analytical depth with practical usability in business environments.
4. Requirements
Your Causal Fairness Toolkit must include:
- A Causal Modeling Template that provides a framework for mapping relationships between protected attributes, features, and outcomes.
- A Counterfactual Analysis Framework for evaluating whether predictions would change under different values of protected attributes.
- An Intervention Point Identification Method that determines optimal intervention points based on causal structures.
- Limited Information Adaptation Guidelines for applying causal analysis with incomplete causal knowledge.
- User documentation that guides users on how to apply the toolkit in practice.
- A case study demonstrating the toolkit's application to a loan approval system.
5. Sample Solution
The following solution was developed by a former colleague and can serve as an example for your own work. Note that this solution wasn't specifically designed for AI applications and lacks some key components that your toolkit should include.
5.1 Causal Modeling Template
The Causal Modeling Template provides an approach for mapping the causal relationships that may create unfairness in AI systems. This template helps users identify key variables and their relationships through the following components:
Variable Identification Guide:
## Protected Attribute Identification
1. Primary protected attributes: [List legally protected characteristics relevant to this application]
2. Intersectional categories: [List relevant combinations of protected attributes]
## Mediator Variable Identification
1. Variables directly influenced by protected attributes: [List variables]
2. Evidence for causal relationship: [Brief justification per variable]
## Proxy Variable Identification
1. Variables correlated with protected attributes: [List variables]
2. Evidence for correlation: [Brief justification per variable]
3. Common causes explaining correlation: [Explanation per variable]
## Outcome Variable Identification
1. Decisions or predictions made by system: [List outcomes]
2. Evaluation metrics used: [List metrics]
## Legitimate Predictor Identification
1. Variables that should influence outcomes: [List variables]
2. Justification for legitimacy: [Brief justification per variable]
Causal Graph Construction Guidelines:
- Use directed arrows to represent causal relationships.
- Use bidirectional dashed arrows to represent correlations without direct causation.
- Distinguish protected attributes, mediators, proxies, and outcomes using different node shapes.
- Document causal assumptions with justifications for each arrow.
- Identify critical paths that may transmit discrimination.
5.2 Counterfactual Analysis Framework
The Counterfactual Analysis Framework enables evaluation of whether an AI system exhibits causal discrimination by examining how predictions would change under counterfactual scenarios where protected attributes take different values.
Counterfactual Query Formulation:
## Counterfactual Query Structure
1. Base case description:
- Individual characteristics: [Relevant non-protected attributes]
- Protected attribute value: [Current value]
- System prediction: [Current prediction/decision]
2. Counterfactual scenario:
- Modified protected attribute: [Counterfactual value]
- Variables that should remain constant: [List causally independent variables]
- Variables that should change: [List descendants of protected attributes]
3. Fairness evaluation:
- Expected outcome under counterfactual: [Prediction if fair]
- Actual model behavior: [What model actually does]
- Discrepancy analysis: [Compare expected vs. actual]
Path-Specific Effect Analysis:
- Identify specific causal pathways from protected attributes to outcomes.
- Classify paths as legitimate or problematic based on domain knowledge.
- Quantify the contribution of each path to observed disparities.
- Focus interventions on problematic paths while preserving legitimate paths.
5.3 Intervention Point Identification Method
The Intervention Point Identification Method helps determine where in the ML pipeline to intervene based on causal analysis results. This method maps causal patterns to appropriate intervention types through a decision tree.
Causal Pattern Decision Tree:
## Intervention Selection Decision Tree
1. If direct discrimination is present (direct path from protected attribute to outcome):
a. Is the protected attribute explicitly used as a feature?
- Yes: Apply in-processing constraints or remove the attribute
- No: Investigate implicit direct discrimination through model architecture
2. If proxy discrimination is present (path through correlated but not causally related variables):
a. Can the proxy variables be identified?
- Yes: Consider pre-processing approaches to transform these variables
- No: Apply in-processing regularization to minimize proxy use
3. If mediator discrimination is present (path through variables causally influenced by protected attributes):
a. Are the mediator variables legitimate predictors for the task?
- Yes: Consider using multi-objective optimization to balance fairness with prediction
- No: Apply pre-processing to remove the influence of protected attributes on these variables
4. If outcome discrimination is present (disparities in model outputs):
a. Are the disparities consistent across subgroups?
- Yes: Consider post-processing approaches like threshold optimization
- No: Apply more targeted interventions based on causal structure
Limited Information Adaptation Guidelines:
- When causal structure is uncertain, test multiple plausible models.
- Perform sensitivity analysis to identify robust intervention decisions.
- Prioritize resolving uncertainties that would change intervention recommendations.
- Document assumptions explicitly to enable future refinement.
6. Case Study: Loan Approval System
This case study demonstrates how to apply the Causal Fairness Toolkit to a loan approval system at a mid-sized bank.
6.1 System Context
The bank is developing a machine learning algorithm to assess default risk and make loan approval decisions. The system analyzes applicant data (credit score, income, debt-to-income ratio, employment history, loan amount, loan-to-value ratio) to predict default probability. Applications with predicted default risk below 15% receive approval.
Initial fairness assessment revealed significant approval rate disparities: 76% for male applicants versus 58% for female applicants, despite similar observed repayment rates among approved applicants from both groups. The team needs to understand the causal mechanisms creating this disparity to select appropriate interventions.
6.2 Step 1: Causal Modeling
Using the Causal Modeling Template, the team identified key variables and relationships:
Protected Attributes: Gender (primary), Age (secondary), Intersectional categories (gender × age)
Mediator Variables:
- Employment history (influenced by gender due to career breaks for family responsibilities)
- Years of continuous employment (influenced by gender for similar reasons)
- Income level (influenced by gender due to wage gaps in various sectors)
Proxy Variables:
- Loan purpose categories (correlated with gender due to differing financial priorities)
- Part-time employment status (correlated with gender due to caregiving responsibilities)
- Industry sector (correlated with gender due to occupational segregation)
Outcome Variable: Loan approval decision (binary)
Legitimate Predictors:
- Current debt-to-income ratio
- Payment-to-income ratio for the proposed loan
- Savings history
- Verification of income sources
The team constructed a causal graph showing multiple paths from gender to the approval decision:
- Gender → Employment history → Default risk → Approval decision
- Gender → Income level → Debt-to-income ratio → Default risk → Approval decision
- Gender ↔ Part-time status → Income stability → Default risk → Approval decision
- Gender ↔ Industry sector → Job security → Default risk → Approval decision
6.3 Step 2: Counterfactual Analysis
The team applied the Counterfactual Analysis Framework to evaluate whether the model exhibits causal discrimination. They formulated counterfactual queries like:
"Would this female applicant receive the same approval decision if they were male, with all causally independent characteristics (debt-to-income ratio, savings history) remaining the same?"
The analysis revealed:
- Clear score differences for counterfactual applicants differing only in gender. This gap was stark.
- Effects were strongest for applicants with employment gaps or part-time work history.
- Income stability assessments showed inconsistent patterns between genders even with similar employment patterns.
Path-specific analysis quantified the discrimination sources:
- The employment history pathway accounted for approximately 40% of the disparity
- The income level pathway accounted for approximately 25% of the disparity
- The part-time status pathway accounted for approximately 20% of the disparity
6.4 Step 3: Intervention Point Selection
Using the Intervention Point Identification Method, the team determined appropriate intervention points:
-
For the employment history pathway (mediator discrimination):
-
Pre-processing intervention: Replace "continuous employment" with "relevant experience" that doesn't penalize career breaks
-
Justification: Employment gaps unfairly penalize women who take career breaks while not accurately reflecting actual financial reliability
-
For the income level pathway (mediator discrimination):
-
In-processing intervention: Apply constraints during model training to reduce the weight of raw income figures
-
Justification: Income differences partly reflect systemic wage gaps rather than actual repayment capacity
-
For the part-time status pathway (proxy discrimination):
-
Pre-processing intervention: Transform part-time status into income stability metrics
- Justification: Part-time status serves more as a gender proxy than a genuine stability indicator
This targeted approach based on causal understanding allowed more precise interventions than simply enforcing demographic parity. The bank could implement these interventions while maintaining the model's core predictive performance for default risk.
