Part 2: Data-Level Interventions (Pre-Processing)
Context
Data-level interventions tackle bias at its source—the data itself—preventing unfairness before it becomes encoded in models.
This Part equips you with techniques to transform biased datasets into fairer representations. You'll learn to reshape distributions, reweight samples, and regenerate data points rather than accepting biased inputs as immutable facts. Too often, data scientists treat datasets as fixed constraints rather than malleable materials.
Reweighting methods adjust sample influence based on protected attributes. For instance, a loan approval algorithm might give greater importance to historically underrepresented applicants during training, counteracting representation imbalances that would otherwise skew predictions.
Transformation approaches modify features to break problematic correlations while preserving predictive power. This matters because variables like zip code often serve as proxies for race in US housing contexts, perpetuating redlining effects when left untreated. Transformations can preserve a feature's predictive utility while removing its correlation with protected attributes.
These interventions integrate throughout your ML workflow—from exploratory analysis that reveals representation gaps to validation practices that verify fairness improvements. Techniques range from simple instance weighting to complex generative methods that synthesize balanced datasets.
The Pre-Processing Fairness Toolkit you'll develop in Unit 5 represents the second component of the Fairness Intervention Playbook. This tool will help you select and configure appropriate data transformations for specific bias patterns, ensuring that your models train on fair representations from the start.
Learning Objectives
By the end of this Part, you will be able to:
- Analyze data representation disparities across protected groups. You will detect and quantify imbalances, missing values, and quality differences, enabling targeted interventions that address specific fairness gaps rather than applying generic fixes.
- Implement reweighting techniques that adjust sample importance. You will apply methods from simple frequency-based weights to sophisticated distribution matching, transforming unbalanced datasets into effectively balanced representations without discarding valuable samples.
- Design feature transformations that mitigate proxy discrimination. You will create methods that reduce problematic correlations between features and protected attributes, preserving legitimate predictive signal while removing discriminatory pathways.
- Develop fairness-aware data augmentation strategies. You will generate synthetic samples for underrepresented groups, moving from limited or imbalanced data to robust representations that support fair model training.
- Evaluate data-level interventions for fairness impact and information preservation. You will create metrics and validation approaches that balance fairness improvements against predictive power, enabling informed decisions about intervention trade-offs in specific contexts.
Units
Unit 1
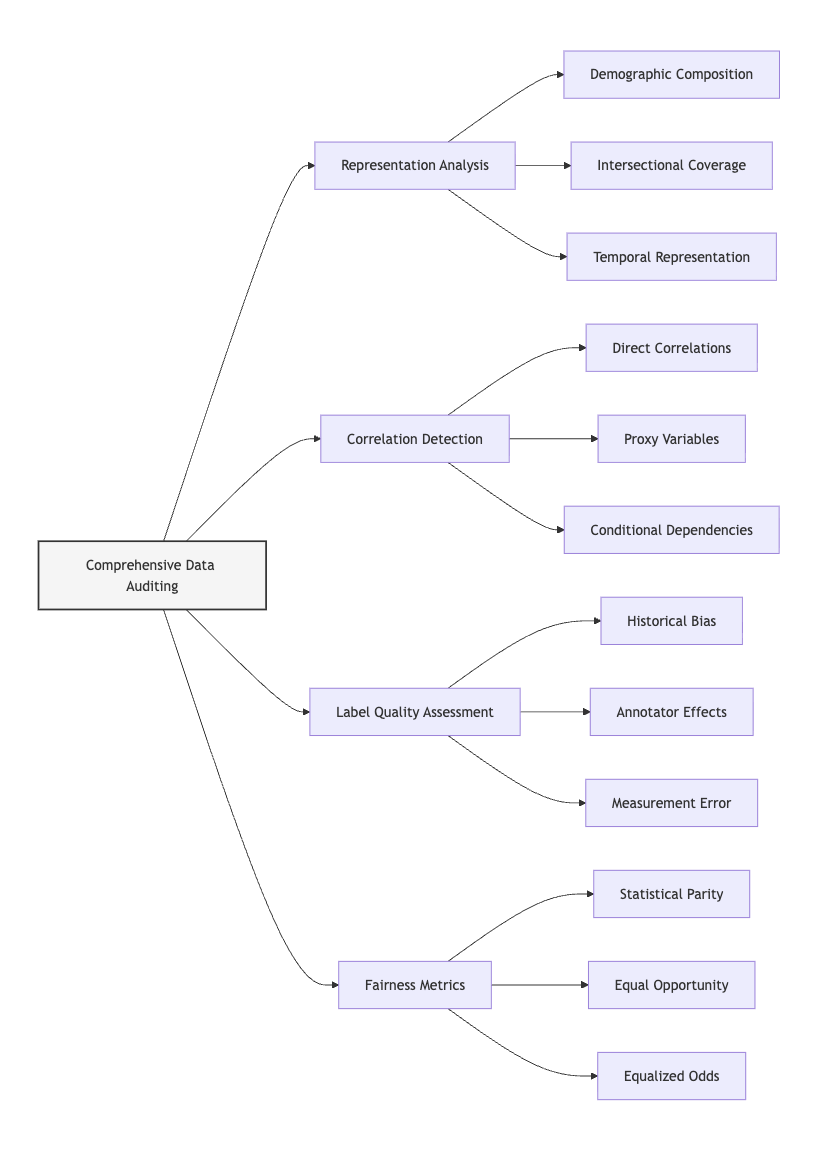
Unit 1: Comprehensive Data Auditing
1. Conceptual Foundation and Relevance
Guiding Questions
- Question 1: How do we systematically uncover and quantify bias patterns in training data before they propagate to machine learning models?
- Question 2: What analytical frameworks enable us to distinguish between different types of data biases, and how can these insights guide appropriate pre-processing interventions?
Conceptual Context
Before applying any fairness intervention, you must first establish a clear understanding of how bias manifests in your training data. Comprehensive data auditing provides the diagnostic foundation for all subsequent fairness work—without it, interventions may target symptoms rather than causes or, worse, introduce new forms of unfairness through misguided corrections.
Data auditing for fairness goes beyond conventional data quality analysis to systematically examine representation disparities, problematic correlations, label quality issues, and other bias patterns that can lead to discriminatory model behavior. As Gebru et al. (2021) note, "Understanding dataset composition is fundamental to understanding how a machine learning model will perform in deployment, particularly when there are fairness concerns" (Gebru et al., 2021).
This Unit builds upon the causal understanding from Part 1, translating causal insights into specific data auditing approaches that identify bias mechanisms. It establishes the analytical foundation for the pre-processing techniques you'll explore in Units 2-4 by determining which types of interventions are most appropriate for specific bias patterns. The comprehensive auditing methodologies you learn here will directly inform the Pre-processing Strategy Selector you'll develop in Unit 5, providing the diagnostic inputs that guide intervention selection.
2. Key Concepts
Multidimensional Representation Analysis
Representation analysis examines whether different demographic groups are adequately and accurately represented in training data. This concept is fundamental to AI fairness because models trained on data with demographic imbalances often perform worse for underrepresented groups, perpetuating and sometimes amplifying existing disparities.
This concept connects to other fairness concepts by establishing the baseline demographic composition that informs subsequent analysis. It intersects with sampling bias detection by quantifying representation gaps, and with label quality assessment by examining whether representation varies across outcome categories.
Conventional data analysis often examines univariate distributions of protected attributes, but multidimensional representation analysis goes further to examine intersectional representation—how well the data represents individuals across combinations of protected attributes. Buolamwini and Gebru's (2018) Gender Shades research demonstrated the critical importance of this approach, revealing that facial recognition datasets had severe representation gaps at the intersection of gender and skin tone that weren't apparent when examining either attribute in isolation.
For example, in a hiring algorithm training dataset, you might find adequate overall representation of women (48%) and adequate representation of people of color (30%), but severe underrepresentation of women of color (only 9% instead of the expected 14.4% if distributions were independent). This intersectional gap creates particular vulnerability to discrimination for this demographic group.
Comprehensive representation analysis includes:
- Comparison of dataset demographics to reference populations (e.g., census data or application-specific benchmarks)
- Identification of representation gaps across protected attributes and their intersections
- Analysis of representation across outcome categories (e.g., positive vs. negative labels)
- Temporal analysis to detect shifts in representation over time
For the Pre-processing Strategy Selector you'll develop in Unit 5, multidimensional representation analysis will serve as a key diagnostic input, helping determine whether reweighting, resampling, or generative approaches are most appropriate for addressing representation disparities.
Correlation and Association Pattern Detection
Beyond representation, data auditing must systematically examine how protected attributes correlate with other features and outcomes. This concept is crucial for AI fairness because these correlations create pathways for both direct and proxy discrimination, even when protected attributes are explicitly excluded from models.
This correlation analysis builds on representation assessment by examining relationships rather than just frequencies. It interacts with fairness interventions by identifying which specific correlations should be targeted for modification through transformation techniques.
Correlation patterns between protected attributes and other features can reveal proxy discrimination pathways. For instance, Angwin et al. (2016) found that in criminal risk assessment data, variables like "prior police contacts" correlated strongly with race due to historical patterns of over-policing in certain neighborhoods, creating an indirect path for racial discrimination.
When auditing data for fairness, you need to examine:
- Direct correlations between protected attributes and outcomes or labels
- Correlations between protected attributes and ostensibly neutral features
- Higher-order associations (e.g., interactions, conditional dependencies)
- Correlation stability across different data subsets and time periods
Modern data auditing goes beyond simple correlation coefficients to employ techniques like mutual information analysis, permutation-based feature importance, and sensitivity analysis to identify subtle association patterns that may lead to discrimination.
For the Pre-processing Strategy Selector, these correlation analyses will help determine when distribution transformation techniques are necessary to address proxy discrimination rather than just adjusting representation through reweighting or resampling.
Label Quality and Annotation Bias Assessment
Training labels themselves can embed historical discrimination or reflect annotator biases, making label quality assessment a critical component of comprehensive data auditing. This concept is essential for AI fairness because biased labels will lead to discriminatory models regardless of how balanced the underlying feature representation may be.
This concept connects to representation analysis by examining not just who is represented but how they are labeled. It intersects with correlation analysis by focusing specifically on the relationship between protected attributes and outcomes, which is often the most direct manifestation of discrimination.
Jacobs and Wallach (2021) demonstrate how measurement errors in labels can have disparate impacts across demographic groups. Their research shows that when annotations are created through subjective human judgments, systematic biases can enter the data through unconscious annotator preferences or stereotypes. For example, studies have found that human annotators consistently rate identical resumes as less qualified when associated with stereotypically female or non-white names (Bertrand & Mullainathan, 2004).
Comprehensive label quality assessment involves:
- Analysis of potential historical biases in outcome definitions
- Examination of inter-annotator agreement across demographic categories
- Validation of labels against external benchmarks when possible
- Counterfactual analysis that tests whether labels would differ if protected attributes were changed
For the Pre-processing Strategy Selector, label quality assessment will inform whether interventions should focus primarily on features, labels, or both, and may suggest specific approaches like relabeling or label smoothing to address annotation biases.
Fairness Metric Baseline Calculation
Establishing baseline fairness metrics on the raw training data provides essential context for subsequent interventions. This concept is fundamental to AI fairness because it quantifies the initial fairness gaps that interventions must address and establishes the benchmarks against which intervention effectiveness will be measured.
This concept builds on all previous analysis components by translating descriptive findings into specific fairness metrics aligned with normative fairness definitions. It connects directly to intervention selection by establishing which fairness criteria are most violated in the raw data.
Different fairness definitions lead to different metrics (Barocas et al., 2019). Statistical parity examines whether outcomes are independent of protected attributes; equal opportunity focuses on true positive rates across groups; equalized odds considers both true positive and false positive rates. By calculating these metrics on raw training data, you establish a comprehensive fairness baseline that guides intervention priorities.
For a loan approval dataset, baseline calculations might reveal a 12 percentage point disparity in approval rates between demographic groups (violating demographic parity), but similar true positive rates across groups (satisfying equal opportunity). This pattern suggests that interventions should prioritize addressing representation disparities rather than classification errors if demographic parity is the chosen fairness definition.
Comprehensive baseline calculation includes:
- Computing multiple fairness metrics aligned with different fairness definitions
- Calculating confidence intervals to assess statistical significance of disparities
- Examining metrics across demographic intersections
- Identifying which fairness violations are most severe and would most benefit from intervention
For the Pre-processing Strategy Selector, these baseline metrics will serve as quantitative criteria for prioritizing which bias patterns to address first and will establish the evaluation framework for assessing intervention effectiveness.
Domain Modeling Perspective
From a domain modeling perspective, comprehensive data auditing maps to specific components of ML systems:
- Data Collection Documentation: How was data gathered, and what sampling approaches might have introduced biases?
- Feature Distribution Analysis: How do feature distributions vary across protected groups, and which features correlate with protected attributes?
- Label Quality Examination: Do labeling processes or historical decisions embedded in labels create disparities across groups?
- Representation Verification: Are all relevant demographic groups adequately represented in the data, including at intersections?
- Potential Proxy Identification: Which features might serve as proxies for protected attributes, enabling indirect discrimination?
This domain mapping helps you systematically examine potential bias sources throughout the data pipeline rather than focusing on isolated metrics. The auditing methodologies you develop will leverage this mapping to create structured approaches for identifying specific bias patterns that require intervention.
Conceptual Clarification
To clarify these abstract auditing concepts, consider the following analogies:
- Comprehensive data auditing is similar to a thorough medical examination that includes not just basic vitals but also blood tests, imaging, and family history. Just as a doctor needs this complete picture to make an accurate diagnosis before prescribing treatment, data scientists need comprehensive auditing to identify specific bias mechanisms before implementing fairness interventions. A superficial analysis would be like prescribing medication based only on a patient's temperature, potentially addressing symptoms without treating the underlying condition.
- Representation analysis functions like demographic surveys for voting districts. Voter representation analyses examine not just overall population counts but also geographic distribution, age breakdowns, and access barriers. Similarly, data representation analysis examines not just the presence of different groups but their distribution across feature space, outcome categories, and time periods. Just as voter underrepresentation can lead to policies that neglect certain communities, data underrepresentation leads to models that perform poorly for marginalized groups.
- Correlation pattern detection resembles forensic accounting that looks for suspicious patterns in financial transactions. Forensic accountants don't just check if the books balance but look for unusual relationships between accounts, unexpected timing patterns, and indirect connections that might indicate fraud. Similarly, correlation detection examines not just obvious relationships but subtle patterns and indirect associations that might enable discriminatory outcomes through proxy variables.
Intersectionality Consideration
Data auditing must explicitly address intersectionality—how multiple protected attributes interact to create unique patterns of advantage or disadvantage. Traditional auditing approaches often examine protected attributes independently, potentially missing critical disparities at demographic intersections.
As Crenshaw's (1989) foundational work demonstrated, discrimination often operates differently at the intersections of multiple marginalized identities. For instance, discrimination patterns affecting Black women may differ substantively from those affecting either Black men or white women, creating unique vulnerabilities that single-attribute analysis would miss.
In data auditing, this requires explicit examination of:
- Representation across demographic intersections, not just individual protected attributes
- Correlation patterns that may affect specific intersectional groups differently
- Label quality issues that may disproportionately impact certain intersectional categories
- Fairness metrics calculated for specific intersections rather than just aggregated groups
Buolamwini and Gebru's (2018) Gender Shades research provides a powerful example of intersectional auditing. Their analysis revealed that facial recognition systems had error rates of less than 1% for light-skinned males but nearly 35% for dark-skinned females—a disparity that would have been masked by examining either gender or skin tone independently.
For the Pre-processing Strategy Selector, intersectional auditing will ensure that interventions address bias patterns affecting all demographic groups, including those at intersections of multiple marginalized identities, rather than just improving aggregate metrics that might still mask significant disparities.
3. Practical Considerations
Implementation Framework
To conduct comprehensive data auditing for fairness, follow this structured methodology:
-
Initial Data Profiling and Documentation:
-
Document data sources, collection methodologies, and potential selection biases.
- Establish reference populations for demographic comparison (e.g., census data, domain-specific benchmarks).
- Identify protected attributes and potential proxy variables based on domain knowledge.
-
Create comprehensive data dictionaries documenting feature meanings, sources, and known limitations.
-
Multidimensional Representation Analysis:
-
Calculate demographic distributions across protected attributes and their intersections.
- Compare dataset demographics to reference populations to identify representation gaps.
- Analyze representation within outcome categories (e.g., positive vs. negative labels).
-
Visualize demographic distributions using appropriate techniques (e.g., mosaic plots for intersectionality).
-
Correlation and Association Pattern Analysis:
-
Calculate correlation matrices between protected attributes and other features.
- Implement mutual information analysis to capture non-linear relationships.
- Perform conditional independence testing to identify subtle association patterns.
-
Visualize correlation networks highlighting strongest associations with protected attributes.
-
Label Quality Assessment:
-
Analyze historical sources of labels and potential embedded biases.
- Compare label distributions across demographic groups and intersections.
- When possible, validate labels against external benchmarks or human experts.
-
Document any known issues or limitations in label quality.
-
Fairness Metric Baseline Calculation:
-
Implement multiple fairness metrics aligned with relevant fairness definitions.
- Calculate metrics across different demographic groups and intersections.
- Apply statistical significance testing to determine which disparities are meaningful.
- Create visualization dashboards highlighting key fairness gaps.
This methodological framework integrates with standard data science workflows by extending exploratory data analysis to explicitly consider fairness dimensions. While adding analytical complexity, these steps provide the foundation for targeted interventions rather than generic fixes.
Implementation Challenges
When implementing comprehensive data auditing, practitioners commonly face these challenges:
-
Missing or Incomplete Protected Attributes: Many datasets lack explicit protected attributes due to privacy regulations or collection limitations. Address this by:
-
Implementing privacy-preserving techniques that enable auditing without exposing individual identities.
- Using validated proxy methods when necessary, with clear documentation of their limitations.
- Conducting sensitivity analyses to understand how different assumptions about missing attributes affect conclusions.
-
Leveraging external data sources when appropriate to augment demographic information.
-
Balancing Comprehensiveness with Practicality: Thorough auditing can require significant resources, particularly for large datasets. Address this by:
-
Implementing staged approaches that begin with higher-level analysis and progressively add detail where needed.
- Prioritizing analysis based on domain-specific risks and historical patterns of discrimination.
- Automating routine aspects of auditing through reusable code libraries and workflows.
- Developing standardized templates that ensure key dimensions are examined without unnecessary duplication.
Successfully implementing comprehensive data auditing requires resources including statistical expertise to implement appropriate tests, domain knowledge to interpret findings in context, and computational tools capable of analyzing large, high-dimensional datasets efficiently.
Evaluation Approach
To assess whether your data auditing implementation is effective, apply these evaluation strategies:
-
Comprehensiveness Assessment:
-
Verify coverage of all relevant protected attributes and their intersections.
- Confirm examination of multiple potential bias sources (representation, correlation, labels).
- Check for both direct and indirect (proxy) discrimination pathway analysis.
-
Validate that temporal aspects of data have been considered when relevant.
-
Actionability Verification:
-
Ensure findings directly connect to specific pre-processing interventions.
- Verify that quantitative metrics establish clear priorities for intervention.
- Confirm that insights are documented in forms usable by team members with varied backgrounds.
- Check that conclusions would enable informed decisions about which intervention techniques to apply.
These evaluation approaches should be integrated into your organization's data documentation and model development protocols, creating clear connections between auditing findings and subsequent intervention decisions.
4. Case Study: Employment Algorithm Bias Audit
Scenario Context
A large technology company is developing a machine learning algorithm to screen job applications, predicting which candidates are likely to succeed based on resume data, previous employment history, and educational background. Early testing revealed concerning disparities in recommendation rates across demographic groups, prompting a comprehensive data audit before further development.
The dataset contains 50,000 past job applications with features including education level, years of experience, previous roles, skills, and historical hiring decisions. The company has explicitly included gender and race information for audit purposes. Key stakeholders include HR leaders concerned about fair hiring, data scientists developing the algorithm, and compliance officers ensuring regulatory requirements are met.
This scenario presents significant fairness challenges due to the historical underrepresentation of certain groups in tech roles and the potential for perpetuating existing patterns through automated screening. The application domain (employment) also faces specific legal requirements around non-discrimination that make fairness particularly critical.
Problem Analysis
Applying the comprehensive auditing methodology revealed several concerning bias patterns:
- Representation Analysis Issues: Initial demographic analysis showed reasonable overall representation of women (42%) and people of color (35%) in the dataset. However, intersectional analysis revealed severe underrepresentation of women of color in technical roles—they constituted only 4% of the dataset despite forming approximately 18% of the relevant labor market. This underrepresentation was masked when examining either gender or race independently.
-
Correlation Pattern Findings: Correlation analysis identified several problematic associations:
-
Strong correlation (r=0.62) between gender and certain skills (e.g., programming languages typically taught in computer science programs with low female enrollment)
- Significant correlation (r=0.47) between race and prestigious university attendance, potentially reflecting historical educational access disparities
-
Subtle but consistent association between demographic attributes and resume language patterns (more vibrant action words correlated with male candidates)
-
Label Quality Issues: When analyzing the historical hiring decisions used as labels:
-
Male candidates were 37% more likely to be hired than equally qualified female candidates for technical roles
- Candidates from prestigious universities were 45% more likely to be hired than candidates with equivalent qualifications from less well-known institutions
-
Subjective assessments like "cultural fit" showed significant disparities across demographic groups
-
Fairness Metric Baseline Results: Calculating fairness metrics on the raw data revealed:
-
A demographic parity difference of 18 percentage points between male and female candidates
- Equal opportunity disparities of 12 percentage points between white and non-white candidates
- Particularly severe disparities at intersections, with qualified women of color 28 percentage points less likely to be recommended than qualified white men
These findings demonstrated that multiple bias mechanisms were present in the data, requiring a combination of pre-processing interventions rather than a single approach.
Solution Implementation
Based on the audit findings, the team implemented a comprehensive approach:
-
For Representation Analysis Issues, they:
-
Documented specific demographic gaps, particularly at intersections of gender and race
- Created visualizations showing representation across job categories and qualifications
- Developed reference demographic profiles showing what balanced representation would look like
-
Identified high-risk demographic groups that would require special attention during intervention
-
For Correlation Pattern Findings, they:
-
Generated correlation maps showing how protected attributes related to other features
- Calculated mutual information scores to identify non-linear relationships
- Created feature groups based on their association with protected attributes
-
Developed a ranking of features by their potential for proxy discrimination
-
For Label Quality Issues, they:
-
Documented patterns of historical discrimination in hiring decisions
- Analyzed how subjective assessments differed across demographic groups
- Identified which hiring managers showed the most consistent bias patterns
-
Created adjusted labels that attempted to correct for historical discrimination
-
For Fairness Metric Baselines, they:
-
Implemented dashboards showing different fairness metrics across demographic groups
- Calculated confidence intervals to determine statistical significance of disparities
- Ranked fairness violations by severity to prioritize intervention efforts
- Established specific fairness goals based on legal requirements and company values
Throughout implementation, they maintained explicit focus on intersectionality, ensuring that groups at the intersection of multiple marginalizedidentities received particular attention.
Outcomes and Lessons
The comprehensive audit revealed several insights that would have been missed with less thorough analysis:
- The intersectional representation gaps were masked when examining either gender or race independently, demonstrating the importance of multidimensional analysis.
- Subtle linguistic patterns in resume descriptions functioned as unexpected proxies for gender, highlighting the need for association analysis beyond obvious correlations.
- The most severe fairness violations occurred at demographic intersections, confirming the critical importance of intersectional analysis.
- Different bias mechanisms required different interventions—representation gaps suggested reweighting approaches while proxy discrimination indicated a need for distribution transformation techniques.
Key challenges included communicating technical findings to non-technical stakeholders and balancing comprehensive analysis with practical time constraints.
The most generalizable lessons included:
- The importance of examining multiple bias mechanisms rather than assuming a single source of unfairness
- The value of quantifying bias to establish clear intervention priorities
- The necessity of intersectional analysis to prevent masking serious disparities affecting specific subgroups
These insights directly inform the development of the Pre-processing Strategy Selector, demonstrating how different audit findings point toward different intervention strategies.
5. Frequently Asked Questions
FAQ 1: Protected Attribute Limitations
Q: How can I conduct meaningful bias audits when my dataset lacks protected attributes like race or gender due to privacy regulations or collection limitations?
A: Privacy constraints require creative approaches, but meaningful auditing remains possible through several strategies. First, consider aggregate analysis using anonymized, consented demographic data that preserves individual privacy while enabling group-level analysis. Second, implement privacy-preserving computation techniques like differential privacy or secure multi-party computation that enable protected attribute analysis without exposing individual data. Third, when appropriate, use validated proxy methods—geographic analysis using census data or validated name-based inference—with explicit documentation of their limitations and uncertainty quantification. Fourth, conduct sensitivity analysis that explores how different assumptions about missing demographic distributions might affect your conclusions. Finally, consider collecting supplementary demographic data through anonymous, voluntary surveys specifically for audit purposes. The goal isn't perfect demographic knowledge but rather sufficient understanding to identify potential disparities and inform intervention strategies. Document all methods, limitations, and uncertainty to maintain transparency about what your audit can and cannot conclude with confidence.
FAQ 2: Balancing Depth With Practicality
Q: Given limited time and resources, how do I determine which aspects of data auditing to prioritize without missing critical bias patterns?
A: Effective prioritization requires a risk-based approach focused on your specific context. Start by leveraging historical knowledge—research documented discrimination patterns in your domain, as these suggest where to look first. For instance, prioritize gender analysis in hiring data or race analysis in lending data based on well-established historical biases. Next, conduct rapid preliminary scans of key fairness metrics across multiple dimensions, using the results to guide deeper investigation where disparities appear largest. Focus on outcome disparities first—if certain groups receive systematically different predictions, this warrants immediate investigation regardless of cause. Prioritize intersectional analysis for historically marginalized groups, as they often face unique bias patterns that simple demographic breakdowns miss. Additionally, leverage automation through reusable code libraries and templates to make comprehensive auditing more efficient. Finally, implement iterative approaches that start with critical areas and progressively expand coverage as resources permit. Remember that imperfect but systematic auditing is vastly preferable to no auditing at all, provided you clearly document which dimensions have been examined and which remain for future work.
6. Project Component Development
Component Description
In Unit 5, you will develop the data auditing component of the Pre-processing Strategy Selector. This component will provide a structured methodology for identifying specific bias patterns in training data and connecting these patterns to appropriate pre-processing interventions.
The deliverable will take the form of a comprehensive auditing framework with analytical templates, visualization approaches, metric calculations, and interpretation guidelines that systematically uncover different types of bias and guide intervention selection.
Development Steps
- Create a Multidimensional Representation Analysis Template: Develop structured approaches for examining demographic distributions across protected attributes and their intersections, comparing these to reference populations, and identifying representation gaps that might require reweighting or resampling interventions.
- Build a Correlation Pattern Detection Framework: Design analytical techniques for identifying problematic associations between protected attributes and other features, with special attention to potential proxy variables that might enable indirect discrimination and require transformation interventions.
- Develop a Label Quality Assessment Approach: Create methodologies for evaluating potential biases in training labels, including historical discrimination embedded in decision processes and annotator biases that might necessitate relabeling or label smoothing techniques.
Integration Approach
This auditing component will interface with other parts of the Pre-processing Strategy Selector by:
- Providing the diagnostic inputs that guide intervention selection, connecting specific bias patterns to appropriate techniques.
- Establishing evaluation metrics that can be used to assess intervention effectiveness.
- Creating visualization approaches that help communicate findings to both technical and non-technical stakeholders.
To enable successful integration, develop standardized documentation formats for auditing findings, use consistent terminology across components, and create explicit connections between identified bias patterns and specific intervention techniques covered in subsequent Units.
7. Summary and Next Steps
Key Takeaways
This Unit has established the fundamental importance of comprehensive data auditing as the diagnostic foundation for all fairness interventions. Key insights include:
- Multidimensional representation analysis must go beyond simple demographic breakdowns to examine intersectionality and representation within outcome categories, revealing disparities that might be masked by aggregate statistics.
- Correlation pattern detection systematically identifies both direct associations and subtle relationships that might enable proxy discrimination, even when protected attributes are explicitly excluded from models.
- Label quality assessment examines how historical discrimination or annotator biases might be embedded in training labels, necessitating intervention at the label level rather than just in features.
- Fairness metric baseline calculation establishes quantitative measures of bias that guide intervention priorities and provide benchmarks for assessing improvement.
These concepts directly address our guiding questions by providing systematic frameworks for uncovering bias patterns in training data and distinguishing between different bias mechanisms that require different intervention approaches.
Application Guidance
To apply these concepts in your practical work:
- Start by thoroughly documenting your data sources, collection methodologies, and potential selection biases before beginning quantitative analysis.
- Implement staged auditing that progressively adds detail—begin with basic demographic breakdowns, then add intersectional analysis, correlation detection, and label quality assessment.
- Use multiple visualization techniques to communicate findings effectively, particularly for complex intersectional patterns that may be difficult to capture in tables or summary statistics.
- Establish clear connections between audit findings and potential interventions, beginning to formulate hypotheses about which techniques might be most effective.
For organizations new to fairness auditing, start by implementing the most critical components (representation analysis and basic correlation detection) while building capacity for more sophisticated approaches. Even basic auditing is substantially better than none, provided its limitations are clearly documented.
Looking Ahead
In the next Unit, we will build on this auditing foundation by exploring reweighting and resampling techniques for addressing representation disparities. You will learn how these approaches can effectively counteract the representation gaps identified through comprehensive auditing without modifying feature distributions.
The auditing methodologies you've developed in this Unit will directly inform which reweighting approaches are most appropriate for specific bias patterns. By understanding exactly how representation imbalances manifest in your data, you'll be able to design targeted reweighting strategies rather than applying generic techniques that might not address the specific disparities present.
References
Angwin, J., Larson, J., Mattu, S., & Kirchner, L. (2016). Machine bias. ProPublica. Retrieved from https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
Barocas, S., Hardt, M., & Narayanan, A. (2019). Fairness and machine learning: Limitations and opportunities. Retrieved from https://fairmlbook.org/
Bertrand, M., & Mullainathan, S. (2004). Are Emily and Greg more employable than Lakisha and Jamal? A field experiment on labor market discrimination. American Economic Review, 94(4), 991-1013.
Buolamwini, J., & Gebru, T. (2018). Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the 1st Conference on Fairness, Accountability, and Transparency (pp. 77-91).
Crenshaw, K. (1989). Demarginalizing the intersection of race and sex: A black feminist critique of antidiscrimination doctrine, feminist theory, and antiracist politics. University of Chicago Legal Forum, 1989(1), 139-167.
Gebru, T., Morgenstern, J., Vecchione, B., Vaughan, J. W., Wallach, H., Daumé III, H., & Crawford, K. (2021). Datasheets for datasets. Communications of the ACM, 64(12), 86-92.
Jacobs, A. Z., & Wallach, H. (2021). Measurement and fairness. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (pp. 375-385).
Unit 2
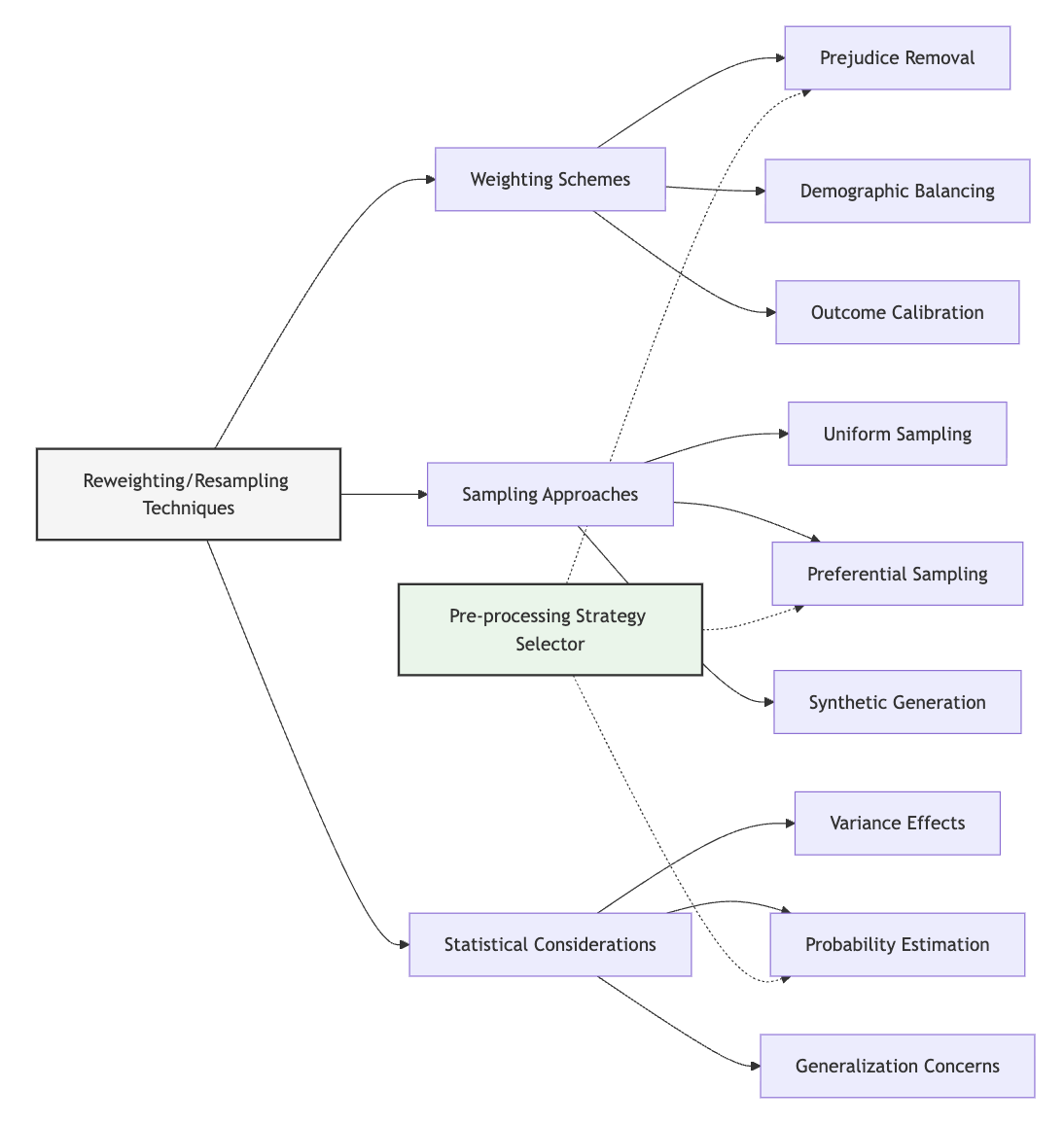
Unit 2: Reweighting and Resampling Techniques
1. Conceptual Foundation and Relevance
Guiding Questions
- Question 1: How can we systematically adjust the influence of training instances to mitigate bias without modifying feature values or model architectures?
- Question 2: When are reweighting and resampling approaches more appropriate than other fairness interventions, and how do we implement them while preserving statistical validity?
Conceptual Context
Reweighting and resampling techniques represent foundational data-level interventions that address fairness by modifying the influence of training instances rather than transforming their features. This approach is particularly valuable because it preserves the original feature distributions within groups while adjusting how different instances impact model training.
Consider a common fairness challenge: a loan approval dataset contains far fewer examples of approved loans for applicants from minority neighborhoods due to historical redlining practices. Even with protected attributes removed, this representation disparity can lead models to perpetuate discriminatory patterns. Reweighting and resampling techniques directly address this imbalance by giving appropriate influence to underrepresented groups, creating a more equitable foundation for model training.
The significance of these techniques lies in their versatility and relative simplicity. Unlike more complex interventions that modify feature distributions or algorithm internals, reweighting and resampling can often be implemented as preprocessing steps that integrate seamlessly with existing ML workflows. As Kamiran and Calders (2012) demonstrated, carefully designed instance weighting schemes can significantly reduce discrimination while maintaining predictive performance.
This Unit builds directly on the comprehensive data auditing approaches established in Unit 1, translating identified bias patterns into specific reweighting and resampling strategies. It also lays essential groundwork for the more complex distribution transformation techniques you'll explore in Unit 3, providing complementary approaches that address different types of bias. Together, these techniques will form critical options in the Pre-processing Strategy Selector you'll develop in Unit 5, enabling you to select appropriate data-level interventions based on specific fairness challenges.
2. Key Concepts
Instance Influence in Model Training
The concept of instance influence—how strongly each training example impacts model learning—is fundamental to understanding reweighting and resampling techniques. This concept is crucial for AI fairness because it provides a mechanism for addressing representation disparities without modifying the inherent characteristics of the data.
Standard training procedures typically give equal importance to each instance (in unweighted approaches) or use weights based on factors unrelated to fairness (such as importance sampling for computational efficiency). This can lead models to minimize average error, which inherently prioritizes patterns common in majority groups while potentially overlooking patterns specific to underrepresented groups.
This concept directly connects to fairness by enabling the adjustment of instance influence based on protected attributes and outcomes. By strategically modifying how strongly different examples impact model training, reweighting and resampling can counteract historical imbalances and ensure all demographic groups appropriately influence the resulting model.
Kamiran and Calders (2012) formalized this approach in their seminal work on preprocessing techniques for fairness. They demonstrated that by assigning weights inversely proportional to the representation of specific attribute-outcome combinations, models could achieve significantly improved fairness metrics while maintaining reasonable predictive performance (Kamiran & Calders, 2012).
For example, in a hiring algorithm trained on historical data, qualified applicants from underrepresented groups might receive higher weights to counteract their historical underrepresentation, ensuring these patterns receive appropriate consideration during model training.
For the Pre-processing Strategy Selector we'll develop in Unit 5, understanding instance influence is essential because it establishes the fundamental mechanism through which reweighting and resampling techniques operate. This understanding will guide the development of selection criteria that determine when these approaches are most appropriate based on specific bias patterns and fairness objectives.
Reweighting Approaches for Fairness
Reweighting approaches explicitly assign different importance weights to training instances based on their characteristics, directly modifying how strongly each example influences model learning without changing the dataset size or composition. This technique is essential for AI fairness because it enables fine-grained control over the influence of different demographic groups and outcome combinations.
Reweighting builds on the concept of instance influence by providing specific methodologies for determining appropriate weight values. Rather than treating all instances equally, reweighting incorporates fairness considerations into the weight assignment process, ensuring traditionally underrepresented groups have appropriate impact on model training.
Several reweighting schemes have been developed specifically for fairness. Kamiran and Calders (2012) introduced a prejudice remover approach that assigns weights based on the combination of protected attributes and outcomes, giving higher weights to combinations that contradict discriminatory patterns. Building on this work, Calders and Verwer (2010) proposed techniques that assign weights to create conditional independence between protected attributes and outcomes.
A practical example comes from loan approval: in historical data, minority applicants might have disproportionately high rejection rates due to discriminatory practices rather than creditworthiness. Reweighting can assign higher importance to minority approvals and majority rejections that contradict these biased patterns, enabling the model to learn more fair decision boundaries.
For the Pre-processing Strategy Selector, understanding different reweighting approaches is crucial for matching specific techniques to appropriate bias patterns. The selector will need to incorporate guidance on which reweighting methods are most suitable for different fairness definitions, data distributions, and implementation constraints.
Resampling Strategies for Balanced Learning
Resampling strategies modify the training data by selectively including or duplicating instances to create a more balanced dataset for model training. This concept is vital for AI fairness because it addresses representation disparities through direct modification of the training set composition rather than through mathematical weighting during optimization.
While reweighting adjusts instance influence through mathematical weights, resampling physically alters which examples the model sees during training and how often. This difference makes resampling particularly valuable when working with algorithms or frameworks that don't support instance weights or when the implementation must occur entirely in the data preparation pipeline.
Chawla et al. (2002) developed the Synthetic Minority Over-sampling Technique (SMOTE) to address class imbalance by generating synthetic examples for minority classes. While not originally designed for fairness, this technique has been adapted to address demographic representation disparities. Feldman et al. (2015) extended these concepts with fairness-specific sampling approaches that selectively include examples to reduce disparate impact.
For example, in a medical diagnosis algorithm where data from certain demographic groups is limited, selective oversampling of these groups can ensure the model doesn't simply optimize for majority populations while underserving minorities. Various approaches include:
- Uniform sampling that selects the same number of examples from each group
- Preferential sampling that selectively includes examples that reduce bias
- Synthetic techniques that generate new examples for underrepresented groups
For our Pre-processing Strategy Selector, understanding resampling strategies will be essential for determining when they should be preferred over reweighting approaches. The selector will need to incorporate decision criteria based on algorithm compatibility, implementation constraints, and specific bias patterns identified through auditing.
Statistical Considerations and Validity
Modifying instance influence through reweighting or resampling introduces important statistical considerations that must be addressed to ensure interventions improve fairness without compromising model validity. This concept is critical for AI fairness because naive application of these techniques can lead to problems like overfitting, increased variance, or distorted probability estimates.
This concept interacts with reweighting and resampling approaches by highlighting the potential trade-offs and complications they introduce. While these techniques can effectively reduce bias, they alter the statistical properties of the training process in ways that require careful consideration and potential compensation.
Key statistical challenges include:
- Sample variance effects: Reweighting effectively reduces the sample size, potentially increasing model variance
- Estimation bias: Modified sampling distributions can distort probability estimates
- Generalization concerns: Extreme weights or sampling rates may lead to overfitting specific patterns
Zadrozny et al. (2003) studied how reweighting affects model calibration and proposed techniques to preserve proper probability estimation when using weighted samples. More recently, Iosifidis and Ntoutsi (2018) examined the interaction between fairness-oriented resampling and model generalization, proposing approaches that balance fairness improvements with statistical validity.
For example, in a credit scoring model, aggressive oversampling of minority approvals might improve demographic parity but could also lead to poor calibration where predicted probabilities no longer accurately reflect true risks. Mitigation approaches include regularization, cross-validation procedures specifically designed for weighted data, and combining reweighting with other techniques.
For our Pre-processing Strategy Selector, these statistical considerations will be crucial for guiding appropriate intervention configuration. The selector will need to incorporate guidelines for balancing fairness improvements against statistical concerns, potentially suggesting complementary techniques that address both simultaneously.
Domain Modeling Perspective
From a domain modeling perspective, reweighting and resampling techniques map to specific components of ML systems:
- Data Preparation Pipeline: Resampling physically modifies the dataset composition through selective inclusion and duplication
- Training Process: Reweighting modifies the optimization objective by adjusting the influence of different instances
- Model Evaluation: Weighted validation ensures fairness improvements don't come at the cost of essential performance characteristics
- Deployment Monitoring: Weight drift detection prevents gradual deviation from the intended balance
This domain mapping helps you understand how reweighting and resampling integrate with the ML workflow rather than viewing them as isolated techniques. The Pre-processing Strategy Selector will leverage this mapping to guide appropriate intervention selection based on where in the pipeline modifications can most effectively be implemented.
Conceptual Clarification
To clarify these abstract concepts, consider the following analogies:
- Reweighting for fairness functions like weighted voting in a diverse committee. In traditional voting, each person gets one equal vote, which means the largest group always determines the outcome. Weighted voting gives stronger representation to minority perspectives by assigning different voting powers based on representation—not because individual minority votes are inherently more valuable, but to ensure all perspectives appropriately influence the final decision. Similarly, reweighting in machine learning doesn't change what examples the model sees but adjusts how strongly different examples influence the final model, ensuring underrepresented groups maintain appropriate impact on model decisions.
- Resampling for fairness is similar to curating a reading list for a comprehensive education. Rather than randomly selecting books in proportion to what's available (which would overwhelmingly represent majority perspectives), an educator might intentionally include more works from underrepresented authors to ensure diverse viewpoints. The goal isn't to misrepresent the overall publishing landscape but to create a more balanced educational experience. Similarly, fairness-aware resampling doesn't pretend the world lacks imbalances but creates a more balanced learning environment for the model that prevents it from overlooking important patterns in underrepresented groups.
- Statistical validity considerations in reweighting resemble adjusting for uneven jury selection. When assessing whether jury selection was fair, statisticians must account for both the demographic composition and the appropriate statistical uncertainty—weighted analyses require larger margins of error. Similarly, when using reweighting for fairness, we must adapt our statistical approaches to account for the modified influence distribution, ensuring our fairness improvements come with appropriate statistical guarantees rather than introducing new forms of uncertainty.
Intersectionality Consideration
Reweighting and resampling approaches must explicitly address how multiple protected attributes interact to create unique representation challenges at demographic intersections. Traditional approaches often address protected attributes independently, potentially missing critical disparities at intersections of multiple attributes.
For example, gender bias and racial bias in hiring data might each appear modest when examined separately, but their intersection could reveal severe underrepresentation of women of color. Standard reweighting approaches addressing gender and race independently might fail to give appropriate influence to this specific intersection.
Ghosh et al. (2021) demonstrated that intersectional fairness requires specialized weighting schemes that explicitly account for multiple attribute combinations rather than addressing each attribute in isolation. Their research showed that addressing attributes separately can sometimes improve fairness along individual dimensions while exacerbating disparities at specific intersections.
Implementing intersectional reweighting and resampling requires:
- Explicitly considering all relevant attribute combinations during weight assignment
- Ensuring sufficient representation of intersectional groups through stratified sampling
- Recognizing statistical challenges when working with smaller intersectional subgroups
- Developing appropriate evaluation metrics that assess fairness across intersections
The Pre-processing Strategy Selector must incorporate these intersectional considerations explicitly, guiding users toward reweighting and resampling configurations that address potential fairness issues across multiple, overlapping demographic dimensions rather than treating each protected attribute in isolation.
3. Practical Considerations
Implementation Framework
To implement effective reweighting and resampling for fairness, follow this structured methodology:
-
Weight Determination Strategy:
-
For addressing representation disparities: Calculate weights inversely proportional to demographic group representation to ensure balanced influence.
- For countering outcome disparities: Assign weights based on the protected attribute-outcome combinations, giving higher weight to combinations that contradict biased patterns (e.g., minority approvals in a system with historical bias toward rejection).
- For addressing conditional outcome disparities: Implement weights that equalize outcomes across groups within similar feature value ranges.
-
Document weight calculation formulas and justifications for specific approaches.
-
Implementation Approaches:
-
For models supporting instance weights: Directly incorporate calculated weights in the training process through the model's built-in weighting parameters.
- For frameworks without native weight support: Convert weights to sampling probabilities and implement weighted sampling during mini-batch creation.
- For preprocessing-only pipelines: Transform weights into discrete resampling by sampling instances with probability proportional to their weights.
-
Document implementation details and code patterns for replication.
-
Statistical Validity Preservation:
-
Implement cross-validation procedures designed for weighted data to ensure robust evaluation.
- Consider regularization adjustments to compensate for effective sample size reduction from weighting.
- Monitor calibration metrics to ensure probability estimates remain accurate despite modified training distribution.
- Document statistical adjustments and their effects on both fairness and performance metrics.
These methodologies integrate with standard ML workflows by providing specific implementation patterns for different stages of the pipeline. Most modern ML frameworks support instance weights during training, making reweighting relatively straightforward to implement. Resampling can be implemented during data preparation, making it compatible with any modeling approach.
Implementation Challenges
When implementing reweighting and resampling for fairness, practitioners commonly face these challenges:
-
Balancing Fairness and Performance: Aggressive reweighting to address severe disparities can sometimes degrade overall model performance. Address this by:
-
Implementing progressive weighting approaches that start with moderate adjustments and increase gradually while monitoring performance impacts.
- Exploring hybrid approaches that combine reweighting with complementary fairness techniques.
- Developing explicit trade-off frameworks that quantify fairness improvements against performance impacts.
-
Using regularization techniques specifically designed for weighted training to mitigate overfitting to heavily weighted samples.
-
Handling Multiple Protected Attributes: Addressing intersectional fairness through reweighting becomes complicated with multiple protected attributes creating numerous intersectional groups. Address this by:
-
Implementing hierarchical weighting schemes that first balance major groups, then address intersectional disparities.
- Using smoothing techniques for small intersectional groups to avoid extreme weights.
- Employing dimensionality reduction approaches that identify the most critical intersections requiring attention.
- Documenting intersectional performance explicitly to ensure improvements in aggregate metrics don't mask issues at specific intersections.
Successfully implementing reweighting and resampling requires resources including statistical expertise to verify validity, computational resources for experimenting with different weighting schemes, and organizational willingness to accept potential trade-offs between different performance dimensions.
Evaluation Approach
To assess whether your reweighting or resampling intervention is effective, implement these evaluation strategies:
-
Fairness Impact Assessment:
-
Compare fairness metrics before and after intervention across multiple definitions (demographic parity, equal opportunity, etc.).
- Measure improvements in the specific fairness criteria targeted by the intervention.
- Evaluate fairness across intersectional categories, not just in aggregate.
-
Document both relative and absolute improvements in fairness metrics.
-
Performance Impact Analysis:
-
Assess changes in overall predictive performance (accuracy, F1, AUC) using appropriate cross-validation for weighted data.
- Measure performance specifically for previously disadvantaged groups to ensure improvements.
- Evaluate model calibration to ensure probability estimates remain reliable.
-
Document performance changes across different subgroups and intersections.
-
Stability and Robustness Testing:
-
Verify fairness improvements persist across different random splits of the data.
- Test sensitivity to variations in the weighting scheme parameters.
- Assess how the intervention performs with new data or shifting distributions.
- Document robustness findings and potential limitations.
These evaluation approaches should be integrated with your organization's broader model assessment framework, providing a comprehensive view of how reweighting or resampling affects both fairness and other essential performance characteristics.
4. Case Study: Medical Diagnosis Algorithm
Scenario Context
A healthcare organization is developing a diagnostic algorithm to detect early signs of cardiovascular disease from patient data. The algorithm analyzes lab results, vital signs, medical history, demographic information, and lifestyle factors to predict disease risk, helping physicians prioritize preventive care for high-risk patients.
Initial analysis revealed concerning performance disparities: the algorithm showed significantly lower sensitivity (true positive rate) for female patients compared to male patients, potentially leading to delayed diagnosis and treatment for women. Further investigation indicated this disparity stemmed from historical underdiagnosis of cardiovascular disease in women in the training data, as heart disease has traditionally been considered primarily a "male disease" despite being the leading cause of death for both men and women.
This scenario involves multiple stakeholders with different priorities: clinicians seeking accurate diagnostic support, hospital administrators concerned about efficiency and liability, patients requiring equitable care, and regulatory bodies monitoring healthcare AI for fairness. The fairness implications are significant given the life-or-death nature of medical decisions and the healthcare system's ethical obligation to provide equitable care.
Problem Analysis
Applying reweighting and resampling concepts to this scenario reveals several key insights:
- Representation Analysis: The training data reflects historical patterns where female cardiovascular disease was frequently underdiagnosed. This isn't merely a representation disparity in quantity (there may be sufficient female patients in the dataset) but rather a quality issue—female patients with early disease signs were more likely to be labeled as healthy in the historical data.
- Instance Influence Assessment: The standard equal-weight training approach would naturally optimize for patterns most common in the data, essentially learning to replicate the historical underdiagnosis of female patients rather than identifying true risk patterns across genders.
- Statistical Considerations: Simply removing gender from the feature set wouldn't solve the problem because the bias appears in the outcome labels themselves. Furthermore, many symptoms and risk factors present differently across genders, making gender-specific patterns genuinely important for accurate diagnosis.
The core challenge is creating a model that learns appropriate risk patterns for both male and female patients despite the historical labeling bias in the training data. This requires modifying instance influence to ensure female patients with disease appropriately impact model training.
From an intersectional perspective, the analysis becomes even more nuanced. The audit revealed that the sensitivity disparity was particularly pronounced for women of color and older women, suggesting unique challenges at these intersections that wouldn't be addressed by a gender-only intervention.
Solution Implementation
To address these fairness concerns through reweighting and resampling, the team implemented a multi-faceted approach:
-
Outcome-Aware Reweighting: The team implemented a reweighting scheme that assigned higher weights to:
-
Female patients with confirmed cardiovascular disease (to increase their influence on the model)
- Male patients without cardiovascular disease (to balance the distribution)
This approach directly addressed the historical underdiagnosis bias by giving appropriate influence to female cardiovascular cases during model training. The weighting formula used:
w(gender, outcome) = baseline_weight * (target_ratio / observed_ratio)
Where target_ratio represented a more balanced distribution based on epidemiological data rather than historical diagnosis rates.
- Intersectional Stratification: Recognizing the intersectional nature of the bias, the team implemented stratified resampling that explicitly addressed representations at intersections of gender, age, and race. This ensured sufficient representation of previously underrepresented intersectional groups.
-
Statistical Validity Preservation: To maintain statistical rigor while implementing these adjustments, the team:
-
Used modified cross-validation procedures appropriate for weighted data
- Implemented regularization techniques to prevent overfitting to heavily weighted samples
-
Monitored calibration metrics to ensure predicted probabilities remained accurate
-
Evaluation Framework: The intervention was evaluated through:
-
Gender-specific sensitivity and specificity metrics
- Intersectional performance analysis across age, gender, and race groups
- Clinical validation by cardiologists reviewing model predictions
This implementation balanced fairness improvements with clinical validity, ensuring the model would provide more equitable risk assessment while maintaining high overall diagnostic accuracy.
Outcomes and Lessons
The reweighting and resampling intervention produced several important outcomes:
- The gender disparity in sensitivity decreased by 68% while maintaining overall predictive performance.
- Intersectional analysis showed improvements across most demographic intersections, though some disparities persisted for specific subgroups.
- Clinical review confirmed the adjusted model made more appropriate risk assessments for female patients presenting with symptoms that had historically been underdiagnosed.
Key challenges included:
- Finding the optimal weighting balance that improved fairness without compromising overall performance
- Addressing sparse data at some demographic intersections
- Ensuring model calibration remained accurate despite the modified training distribution
The most generalizable lessons included:
- The importance of outcome-aware reweighting when bias exists in historical labels rather than merely in representation quantity.
- The value of combining reweighting with domain expertise to establish appropriate target distributions rather than simply enforcing statistical parity.
- The need for comprehensive evaluation across multiple fairness criteria and performance metrics to understand intervention effects fully.
These insights directly inform the Pre-processing Strategy Selector, demonstrating when reweighting approaches are particularly valuable (label bias cases) and how they should be configured (based on epidemiologically sound target distributions rather than simple statistical parity).
5. Frequently Asked Questions
FAQ 1: Reweighting Vs. Resampling Selection
Q: When should I choose reweighting over resampling or vice versa for addressing fairness issues?
A: The choice between reweighting and resampling depends on several practical factors. Choose reweighting when: (1) your modeling framework directly supports instance weights during training, enabling precise influence adjustments without physically altering the dataset; (2) you need fine-grained, continuous control over instance influence rather than discrete inclusion/exclusion; or (3) memory and storage constraints make duplicating data points impractical. Prefer resampling when: (1) working with frameworks or algorithms that don't natively support instance weights; (2) implementing fairness as a preprocessing step separate from model training; or (3) other team members need to work with a concrete, balanced dataset rather than understanding weighting schemes. In practice, reweighting offers more precise control but requires model compatibility, while resampling offers broader compatibility but with less granular control. For high-stakes applications, consider implementing both approaches in parallel during development to determine which provides better fairness improvements in your specific context.
FAQ 2: Weighting Scheme Design
Q: How do I determine the optimal weighting scheme for my specific fairness objectives without compromising model performance?
A: Designing effective weighting schemes requires balancing fairness goals with statistical considerations. Start by clearly defining your primary fairness objective—whether demographic parity, equal opportunity, or another metric—as this will guide your weighting approach. For representation disparities, weights inversely proportional to group size provide a starting point. For outcome disparities, weights should be based on protected attribute-outcome combinations, giving higher influence to combinations that contradict bias patterns. However, avoid extreme weights that might lead to overfitting or instability. Implement progressive weighting: begin with moderate adjustments (e.g., square root of the theoretical optimal weights) and increase gradually while monitoring both fairness improvements and performance metrics on a validation set. Use cross-validation specifically designed for weighted data to ensure reliable evaluation. Consider combining weighting with regularization techniques that mitigate potential overfitting to heavily weighted samples. Document multiple weighting schemes and their effects on both fairness and performance metrics, enabling explicit trade-off decisions based on your application's specific requirements and constraints.
6. Project Component Development
Component Description
In Unit 5, you will develop the reweighting and resampling section of the Pre-processing Strategy Selector. This component will provide systematic guidance for selecting and configuring appropriate reweighting and resampling techniques based on specific bias patterns, data characteristics, and fairness objectives.
The deliverable will include a decision framework for determining when reweighting and resampling are appropriate, comparisons of different techniques with their strengths and limitations, configuration guidelines for implementation, and evaluation approaches for assessing effectiveness. These elements will form a critical part of the overall Pre-processing Strategy Selector, enabling practitioners to make informed decisions about when and how to implement these techniques.
Development Steps
- Create a Technique Comparison Matrix: Develop a comprehensive comparison of different reweighting and resampling approaches, including their methodological foundations, implementation requirements, appropriate use cases, and limitations. This matrix will serve as a reference for matching specific techniques to appropriate contexts.
- Design Selection Decision Trees: Create structured decision flows that guide practitioners from identified bias patterns toward appropriate reweighting or resampling techniques. These decision trees should incorporate factors like bias type, data characteristics, model compatibility, and implementation constraints.
- Develop Configuration Guidelines: Build detailed guidelines for implementing and tuning selected techniques, including formulas for weight calculation, sampling approaches, parameter selection guidance, and code patterns for common frameworks. These guidelines should enable effective implementation once a technique has been selected.
Integration Approach
This reweighting and resampling component will interface with other parts of the Pre-processing Strategy Selector by:
- Building on the bias patterns identified through the auditing approaches from Unit 1.
- Establishing clear boundaries with the transformation techniques from Unit 3, indicating when reweighting/resampling should be preferred over or combined with feature transformations.
- Providing integration patterns for the data generation approaches from Unit 4, showing how synthetic data can complement reweighting/resampling.
To enable successful integration, use consistent terminology across selector components, establish clear decision criteria that distinguish when each approach is most appropriate, and create explicit guidance for combining techniques when necessary.
7. Summary and Next Steps
Key Takeaways
Throughout this Unit, you've explored how reweighting and resampling techniques provide powerful tools for addressing fairness through data-level interventions. Key insights include:
- Instance influence is a fundamental lever for fairness that enables addressing representation disparities without modifying feature distributions. By adjusting how strongly different examples impact model training, these techniques can counteract historical imbalances that would otherwise be perpetuated by standard learning approaches.
- Different reweighting schemes target different bias patterns, from simple demographic balancing to more sophisticated approaches that consider protected attribute-outcome combinations. Understanding these distinctions helps match specific techniques to appropriate fairness challenges.
- Implementation approaches span the ML pipeline, from preprocessing through resampling to direct weight incorporation during training. This flexibility enables integration with diverse frameworks and workflows while addressing fairness at the data level.
- Statistical validity requires careful consideration to ensure fairness improvements don't come at the cost of model robustness. Techniques like specialized cross-validation, regularization adjustments, and calibration monitoring help maintain statistical rigor while implementing fairness interventions.
These concepts address our guiding questions by showing how instance influence can be systematically adjusted to improve fairness without modifying features or model architectures, and by establishing when reweighting and resampling are most appropriate compared to other fairness interventions.
Application Guidance
To apply these concepts in your practical work:
- Start with comprehensive data auditing to identify specific bias patterns, as described in Unit 1. Understanding the exact nature of representation and outcome disparities is essential for selecting appropriate reweighting or resampling approaches.
- When representation disparities are the primary concern, implement group-based weighting inversely proportional to group size or sample according to target distributions that better represent the population of interest.
- When outcome disparities are the key issue, implement more sophisticated schemes that consider protected attribute-outcome combinations, giving higher weight to combinations that contradict biased patterns.
- Always evaluate interventions across multiple metrics—both fairness and performance—to understand the full impact of your adjustments and potential trade-offs.
For organizations new to fairness interventions, reweighting and resampling often represent accessible starting points that can integrate with existing workflows without requiring fundamental architectural changes. Begin with moderate adjustments and increase intervention strength incrementally while monitoring both fairness improvements and potential performance impacts.
Looking Ahead
In the next Unit, we will build on these foundations by exploring distribution transformation approaches that directly modify feature representations to reduce problematic correlations. While reweighting and resampling adjust instance influence without changing features, transformation techniques provide complementary approaches that address bias at the feature level.
The understanding you've developed about reweighting and resampling will provide important context for these transformation techniques, as both approaches represent different strategies for data-level fairness interventions. Your knowledge of when and how to implement reweighting and resampling will help you understand where transformation approaches might provide better alternatives or valuable complements in your fairness toolkit.
References
Calders, T., & Verwer, S. (2010). Three naive Bayes approaches for discrimination-free classification. Data Mining and Knowledge Discovery, 21(2), 277-292.
Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: Synthetic minority over-sampling technique. Journal of Artificial Intelligence Research, 16, 321-357.
Feldman, M., Friedler, S. A., Moeller, J., Scheidegger, C., & Venkatasubramanian, S. (2015). Certifying and removing disparate impact. In Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 259-268).
Ghosh, A., Chhabra, A., Ling, S. Y., Narayanan, P., & Koyejo, S. (2021). An intersectional framework for fair and accurate AI. arXiv preprint arXiv:2105.01280.
Iosifidis, V., & Ntoutsi, E. (2018). Dealing with bias via data augmentation in supervised learning scenarios. In IoT Stream for Data-Driven Predictive Maintenance and IoT, Edge, and Mobile for Embedded Machine Learning (pp. 24-34).
Kamiran, F., & Calders, T. (2012). Data preprocessing techniques for classification without discrimination. Knowledge and Information Systems, 33(1), 1-33.
Zadrozny, B., Langford, J., & Abe, N. (2003). Cost-sensitive learning by cost-proportionate example weighting. In Proceedings of the Third IEEE International Conference on Data Mining (pp. 435-442).
Unit 3
Unit 3: Distribution Transformation Approaches
1. Conceptual Foundation and Relevance
Guiding Questions
- Question 1: How can we transform feature distributions to mitigate bias while preserving the predictive utility of our data?
- Question 2: What are the mathematical foundations and practical implementations of distribution transformation techniques that enable fair prediction without requiring changes to modeling algorithms?
Conceptual Context
While reweighting and resampling techniques (covered in Unit 2) adjust the influence of specific instances in your training data, they maintain the original feature values and distributions. However, many fairness issues arise from problematic correlations between protected attributes and other features—correlations that persist regardless of how you weight or sample instances. Distribution transformation approaches directly address this challenge by modifying the feature space itself.
This approach is particularly powerful when the causal analysis you conducted in Part 1 reveals proxy discrimination—where features that are statistically associated with protected attributes become vehicles for bias. For example, zip codes might serve as proxies for race in lending models, or communication style might correlate with gender in hiring algorithms. Simply removing these features is often suboptimal, as they may contain legitimate predictive information alongside problematic correlations.
Distribution transformation techniques offer a more nuanced solution by modifying feature representations to reduce their correlation with protected attributes while preserving their predictive power for the target variable. As Zemel et al. (2013) demonstrated in their seminal work on fair representations, these transformations can effectively prevent algorithms from exploiting biased patterns while maintaining predictive utility for legitimate relationships.
This Unit builds directly on the data auditing approaches from Unit 1, which identified problematic correlations, and complements the instance-level interventions from Unit 2. The distribution transformation techniques you learn here will form a critical component of the Pre-processing Strategy Selector you'll develop in Unit 5, providing solutions for scenarios where reweighting alone is insufficient to address embedded biases.
2. Key Concepts
Disparate Impact Removal Through Distribution Transformation
Disparate impact removal transforms feature distributions to ensure they cannot be used to predict protected attributes while preserving their predictive power for legitimate tasks. This concept is fundamental for AI fairness because it addresses proxy discrimination—where seemingly neutral features serve as vehicles for bias due to their correlation with protected attributes.
This concept interacts with other fairness concepts by addressing a different bias mechanism than reweighting techniques. While reweighting adjusts the influence of specific instances, distribution transformation modifies the feature space itself to break problematic correlations. Both approaches might be necessary in different scenarios or even in combination for comprehensive fairness pre-processing.
Feldman et al. (2015) introduced a formal approach for disparate impact removal through distribution transformation. Their technique maps the distribution of a feature within each protected group to a common (often median) distribution, ensuring that the feature's distribution becomes independent of the protected attribute while preserving rank-ordering within groups. This "repair" of the feature distribution makes it impossible to use the transformed feature to predict protected attributes (Feldman et al., 2015).
For example, if a credit scoring model uses "distance from financial center" as a feature that unintentionally correlates with race, disparate impact removal would transform this feature so its distribution becomes identical across racial groups. After transformation, the feature can no longer serve as a proxy for race, but it maintains its legitimate predictive relationship with creditworthiness within each group.
The key insight is that we can quantifiably "repair" features by transforming their distributions while maintaining much of their predictive utility. As Feldman et al. demonstrated, this approach can effectively reduce discrimination with a minimal impact on overall model accuracy when implemented correctly (Feldman et al., 2015).
For the Pre-processing Strategy Selector you'll develop in Unit 5, this distribution transformation approach provides a powerful tool for scenarios where specific features exhibit problematic correlations with protected attributes but contain legitimate predictive information that should be preserved.
Optimal Transport for Fair Representations
Optimal transport provides a mathematical framework for transforming feature distributions in a way that minimizes information loss while ensuring fairness. This concept is crucial for AI fairness because it offers a principled approach to modifying data distributions with minimal distortion of legitimate relationships.
This approach builds on disparate impact removal by offering a more sophisticated mathematical foundation for distribution transformation. While basic approaches might independently transform each feature, optimal transport can consider multidimensional distributions and complex relationships between variables.
Jiang et al. (2020) developed FARE (Fair AutoEncoder Representation), which applies optimal transport principles to create fair representations that balance multiple competing objectives. Their approach demonstrates how optimal transport can effectively transform feature distributions to achieve independence from protected attributes while maintaining maximal information content for prediction tasks (Jiang et al., 2020).
The key insight is that distribution transformation can be formulated as an optimization problem: find the transformation that minimizes the "transportation cost" (information loss) while achieving the desired fairness properties. This framing enables more nuanced transformations that precisely target problematic correlations while preserving legitimate predictive relationships.
For example, when addressing gender bias in resume screening, an optimal transport approach might transform features like "communication style" or "leadership description" to have similar distributions across genders, while preserving their relationship with actual job performance. The transformation would be calculated to minimize distortion of legitimate information while ensuring the features cannot be used to predict gender.
For the Pre-processing Strategy Selector, optimal transport approaches provide advanced options for scenarios requiring sophisticated distribution transformations, particularly when dealing with complex, multidimensional features where simpler approaches might destroy too much legitimate information.
Learning Fair Representations
Learning fair representations involves creating new feature spaces where protected attributes are obscured while prediction-relevant information is preserved. This concept is essential for AI fairness because it offers a way to fundamentally transform how data is represented before model training, addressing bias at its root while enabling strong predictive performance.
This concept extends distribution transformation by moving beyond modifying existing features to creating entirely new representations optimized for both fairness and utility. It connects to representation learning in machine learning more broadly, applying those techniques to the specific challenge of fairness.
Zemel et al. (2013) pioneered this approach with their Learning Fair Representations (LFR) framework, which maps the original feature space to a new representation that statistically obscures protected attributes while preserving information needed for the prediction task. Their approach explicitly balances multiple objectives: fairness (independence from protected attributes), fidelity (preserving information), and classification accuracy (Zemel et al., 2013).
More recent work by Madras et al. (2018) extended this approach with LAFTR (Learning Adversarially Fair and Transferable Representations), which uses adversarial learning to create representations that are both fair and transferable across tasks. Their work demonstrates that fair representations can be learned that satisfy multiple fairness criteria simultaneously while maintaining strong predictive performance (Madras et al., 2018).
The key insight is that we can learn new data representations that fundamentally transform how AI systems "see" the data, removing pathways for bias while preserving legitimate signals. Rather than simply adjusting existing features, we create an entirely new feature space optimized for fairness from the ground up.
For the Pre-processing Strategy Selector, fair representation learning provides a powerful option for scenarios requiring comprehensive transformation of the feature space, particularly when dealing with complex data types like text, images, or highly dimensional tabular data where simpler transformations might be insufficient.
Domain Modeling Perspective
From a domain modeling perspective, distribution transformation approaches map to specific components of ML systems:
- Feature Engineering: Distribution transformations fundamentally change how raw attributes are converted into model features, creating new representations that prevent bias while preserving utility.
- Data Pipeline: Transformation components must integrate into existing data preparation workflows, applying consistent transformations across training and inference.
- Model Selection: Transformed features may enable simpler models to achieve fair outcomes, potentially eliminating the need for complex fairness constraints during training.
- Evaluation Framework: Transformations must be evaluated both for their impact on fairness metrics and their preservation of predictive utility.
- Deployment Considerations: Transformation logic must be consistently applied to new data during inference to maintain fairness properties.
This domain mapping helps you understand how distribution transformation affects different stages of the ML lifecycle rather than viewing it as an isolated pre-processing step. The Pre-processing Strategy Selector will leverage this mapping to guide when and how to implement these transformations within your broader ML development process.
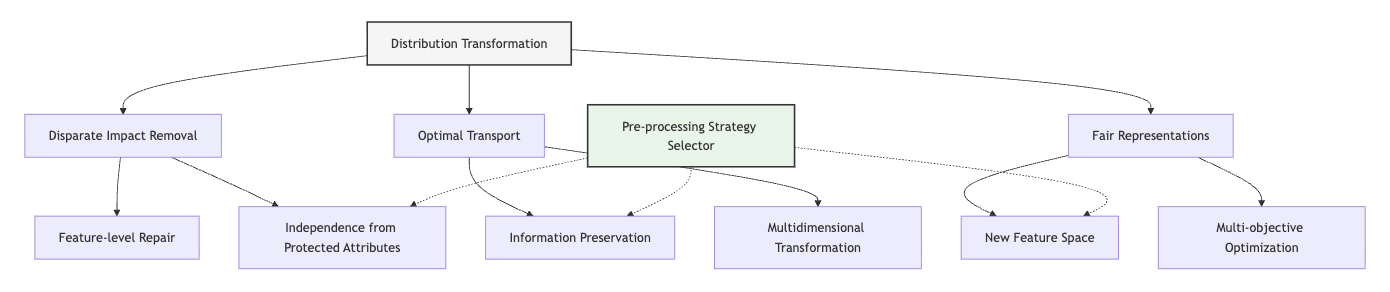
Conceptual Clarification
To clarify these abstract distribution transformation concepts, consider the following analogies:
- Disparate impact removal functions like color correction in photography. A photographer might adjust color balance to ensure accurate representation of all skin tones, compensating for camera sensors that naturally capture some tones better than others. Similarly, disparate impact removal adjusts feature distributions to compensate for historical biases, ensuring all groups are represented fairly while preserving the "composition" (legitimate relationships) in the data. The transformation doesn't eliminate the original information; it recalibrates it to ensure fair representation across protected groups.
- Optimal transport resembles an efficient logistics operation where goods (information) must be moved from multiple warehouses (original distribution) to new locations (fair distribution) at minimal cost. Just as a logistics company optimizes shipping routes to minimize transportation costs while ensuring all destinations receive their goods, optimal transport methods find the most efficient way to transform feature distributions to achieve fairness while minimizing information loss. This mathematical approach ensures that distribution transformations preserve as much legitimate predictive power as possible.
- Learning fair representations is similar to automatic translation that preserves meaning while removing gender-specific language. A good translation system might convert gendered terms from one language to gender-neutral equivalents in another, preserving the essential meaning while removing potentially biased gender associations. Similarly, fair representation learning creates a new "language" for representing features that preserves their meaningful predictive content while eliminating their ability to encode protected attributes like gender or race.
Intersectionality Consideration
Traditional distribution transformation approaches often address protected attributes independently, potentially missing how multiple forms of discrimination interact at demographic intersections. Effective transformations must explicitly consider intersectional effects, ensuring fair representations across overlapping demographic categories rather than just in aggregate.
Recent work by Foulds et al. (2020) on "Intersectional Fairness" highlights that transformations designed for single protected attributes often fail to address bias at intersections of multiple attributes. Their research demonstrates that optimizing for fairness across major demographic groups (e.g., gender or race independently) can sometimes worsen disparities for specific intersectional subgroups (e.g., Black women) (Foulds et al., 2020).
To address these challenges, distribution transformations can be extended to explicitly model and transform intersectional categories. For example, rather than transforming features to be independent of race and gender separately, transformations can target independence from specific intersectional categories (e.g., ensuring features cannot predict whether someone is a Black woman).
These intersectional approaches become particularly important when:
- Historical discrimination has uniquely affected specific intersectional groups (e.g., women of color in tech).
- Data auditing reveals distinct distribution patterns at demographic intersections.
- Fairness goals specifically include addressing disparities for intersectional groups.
For the Pre-processing Strategy Selector, addressing intersectionality requires extending transformation techniques to handle multiple protected attributes simultaneously, potentially through hierarchical or multidimensional approaches that preserve legitimate information while removing all pathways for intersectional discrimination.
3. Practical Considerations
Implementation Framework
To effectively implement distribution transformation approaches, follow this structured methodology:
-
Feature Correlation Analysis:
-
Identify features with problematic correlations to protected attributes using mutual information, correlation coefficients, or predictability measures.
- Quantify the strength of these associations to prioritize features for transformation.
- Assess each feature's legitimate predictive power for the target variable to understand transformation trade-offs.
-
Document both problematic correlations and legitimate predictive relationships to guide transformation decisions.
-
Transformation Technique Selection:
-
For individual features with simple correlations, consider univariate distribution alignment methods like those in Feldman et al. (2015).
- For complex, multidimensional features, evaluate optimal transport approaches that preserve internal structures.
- For scenarios requiring completely new feature spaces, consider fair representation learning techniques.
-
Match transformation complexity to the specific fairness challenges identified in your data auditing.
-
Transformation Implementation:
-
Develop transformation pipelines that can be applied consistently across training and inference.
- Ensure transformations are parameterized by protected attributes during training but can be applied without them during inference.
- Implement efficient computations for large datasets, potentially using approximate techniques when exact transforms are computationally prohibitive.
-
Create appropriate validation splits to prevent overfitting the transformations to training data patterns.
-
Evaluation and Refinement:
-
Assess transformed data using both fairness metrics (independence from protected attributes) and utility metrics (preservation of predictive power).
- Compare performance across multiple transformation approaches to identify optimal techniques for your specific context.
- Iteratively refine transformations based on evaluation results, potentially using different techniques for different feature subsets.
- Document the fairness-utility trade-offs of different transformation configurations to support informed decision-making.
These methodologies integrate with standard ML workflows by extending feature engineering practices to explicitly address fairness concerns. While they add complexity to data preparation, they can simplify downstream modeling by reducing the need for complex fairness constraints during training or post-processing adjustments after prediction.
Implementation Challenges
When implementing distribution transformations, practitioners commonly face these challenges:
-
Information Loss vs. Fairness Trade-offs: More aggressive transformations may improve fairness metrics but reduce predictive performance. Address this by:
-
Implementing parameterized transformations that allow explicit control of the fairness-utility trade-off.
- Applying transformations selectively to features with the strongest problematic correlations rather than transforming all features.
- Using more sophisticated transformation techniques (like optimal transport) that minimize information loss for a given fairness improvement.
-
Documenting the Pareto frontier of fairness-utility trade-offs to enable informed business decisions.
-
Computational Complexity for Large Datasets: Some transformation techniques become computationally prohibitive at scale. Address this by:
-
Implementing approximate algorithms for large datasets where exact transformations are infeasible.
- Considering dimensionality reduction before transformation for very high-dimensional data.
- Developing batch processing approaches for iterative transformations of large datasets.
- Exploring more efficient implementations, potentially leveraging GPU acceleration for transformation computation.
Successfully implementing distribution transformations requires resources including statistical expertise to assess feature correlations properly, computational resources for implementing transformations (especially for large or complex datasets), and organizational willingness to accept potential trade-offs between fairness improvements and minor reductions in predictive performance.
Evaluation Approach
To assess whether your distribution transformations are effective, implement these evaluation strategies:
-
Independence Assessment:
-
Measure mutual information or predictability between transformed features and protected attributes.
- Calculate demographic parity metrics on predictions made using only the transformed features.
- Verify independence holds across different slices and intersections of protected attributes.
-
Establish acceptable thresholds for residual correlation based on application requirements.
-
Information Preservation Evaluation:
-
Compare predictive performance on the target variable before and after transformation.
- Assess preservation of rank ordering within groups when this property is desired.
- Measure information loss using reconstruction errors or mutual information with original features.
-
Evaluate performance impacts across different demographic groups to ensure transformations don't disproportionately affect certain populations.
-
Transformation Robustness Analysis:
-
Test transformation stability across different data samples and over time.
- Evaluate sensitivity to outliers and distribution shifts.
- Assess how transformations perform on new data not seen during transformation design.
- Verify that transformations maintain their fairness properties when combined with different modeling approaches.
These evaluation approaches should be integrated with your organization's broader fairness assessment framework, providing quantitative evidence that transformations effectively address bias concerns while maintaining acceptable utility.
4. Case Study: Job Recommendation Algorithm
Scenario Context
A technology company is developing a job recommendation algorithm to match job seekers with appropriate employment opportunities. The system analyzes user profiles, including skills, experience, education, and behavioral data on the platform, to predict which job postings would be most relevant to each user.
Initial fairness analysis revealed concerning gender disparities: the algorithm recommended higher-paying technical roles to men at substantially higher rates than to women with comparable qualifications. Data auditing identified that while the model didn't use gender directly, several features strongly correlated with gender in ways that influenced recommendations. These included:
- Language patterns in profile descriptions (use of certain adjectives correlated with gender)
- Engagement metrics with different types of content on the platform
- Educational institution and degree specialization (reflecting historical gender imbalances)
The company needs to address these biases while maintaining the recommendation system's ability to match users with genuinely relevant job opportunities. Key stakeholders include job seekers expecting fair treatment, employers seeking qualified candidates, product managers concerned about user engagement, and legal teams monitoring compliance with employment regulations.
Problem Analysis
Applying the distribution transformation concepts from this Unit reveals several key insights:
- Proxy Discrimination Analysis: The causal analysis showed that gender wasn't directly influencing recommendations, but correlated features were serving as effective proxies. For example, language style in profiles strongly predicted gender (mutual information of 0.42), and this same feature significantly influenced which jobs were recommended, creating an indirect path for gender bias.
- Multi-dimensional Feature Challenges: The bias didn't exist in individual features alone but in complex relationships between multiple features. For instance, education features alone showed moderate correlation with gender, but when combined with engagement metrics, they formed stronger predictive patterns. Simple univariate transformations would be insufficient.
- Legitimate Information Preservation: Many problematic features contained genuinely valuable information for job matching. For example, education specialization had legitimate relevance to job skills but also reflected historical gender imbalances in certain fields. Simply removing these features would significantly reduce recommendation quality.
- Intersectionality Effects: Further analysis revealed that the bias was particularly pronounced for specific intersectional groups. For instance, women with non-traditional career paths faced even stronger biases than those with conventional trajectories. Any transformation would need to address these intersectional effects.
The team recognized that distribution transformation approaches were ideal for this scenario because:
- The bias operated primarily through proxy discrimination rather than sampling imbalances.
- The features contained legitimate information that should be preserved.
- The correlations existed across multiple features, requiring sophisticated transformations.
- Simple removal of correlated features would substantially degrade recommendation quality.
Solution Implementation
To address these challenges through distribution transformation, the team implemented a structured approach:
-
For Feature Correlation Analysis, they:
-
Calculated mutual information between each feature and gender, identifying 12 features with strong correlations.
- Developed causal graphs showing how these features influenced recommendations, distinguishing legitimate pathways from problematic ones.
- Created visualizations of feature distributions across gender categories to understand specific patterns.
-
Quantified each feature's predictive power for relevant job matching, independent of gender correlations.
-
For Transformation Technique Selection, they:
-
Applied univariate disparate impact removal to features with simple, direct correlations to gender (e.g., certain profile metrics).
- Implemented optimal transport approaches for interconnected feature clusters where relationships between features mattered (e.g., education and experience features).
- Developed a LAFTR (Learning Adversarially Fair and Transferable Representations) model for text-based features like profile descriptions and skill listings.
-
Created a composite approach that combined multiple techniques for different feature subsets.
-
For Transformation Implementation, they:
-
Built a transformation pipeline that integrated all approaches while maintaining feature relationships.
- Ensured transformations were parameterized during development but applicable without access to gender during deployment.
- Optimized computational efficiency through batched processing and approximation techniques for larger feature sets.
-
Created a consistent transformation interface for both batch and real-time recommendation scenarios.
-
For Evaluation and Refinement, they:
-
Assessed independence from gender using predictability measures before and after transformation.
- Compared recommendation quality using both relevance metrics and user engagement feedback.
- Analyzed performance across intersectional groups to ensure fairness for all user segments.
- Iteratively refined transformation parameters to balance fairness improvements against utility preservation.
Throughout implementation, they maintained explicit focus on intersectional fairness, ensuring transformations addressed the unique challenges faced by women with non-traditional backgrounds or from underrepresented groups.
Outcomes and Lessons
The distribution transformation approach yielded significant improvements:
- Gender predictability from transformed features decreased by 87%, effectively eliminating most proxy discrimination pathways.
- The recommendation disparity between genders for technical roles decreased from 37% to 6% while maintaining 94% of the original recommendation relevance.
- User engagement with recommended jobs increased slightly (2.3%) across all demographics, suggesting the transformations removed noise rather than signal.
- Intersectional analysis showed consistent improvements across different demographic segments, with the largest gains for previously most-disadvantaged groups.
Key challenges encountered included:
- Computational complexity for optimal transport transformations on large feature sets, requiring approximation techniques.
- Finding appropriate parameterizations that balanced fairness gains against information preservation.
- Ensuring transformations remained effective as user behavior and job market conditions evolved over time.
The most generalizable lessons included:
- The importance of targeted transformations: Different feature types required different transformation approaches, with no single technique optimal for all features.
- The value of quantifying trade-offs: Explicit measurement of fairness-utility trade-offs enabled informed decisions about transformation intensity.
- The effectiveness of preservation-focused approaches: Techniques that explicitly preserved legitimate information (like optimal transport) outperformed simpler methods that focused solely on removing correlations.
These insights directly inform the Pre-processing Strategy Selector by highlighting when and how distribution transformation approaches can effectively address proxy discrimination while maintaining predictive utility.
5. Frequently Asked Questions
FAQ 1: Transformation Design Without Protected Attributes
Q: How can we design effective distribution transformations when we don't have access to protected attribute data during deployment?
A: This common scenario requires a two-phase approach: First, during transformation design, you use protected attributes to analyze correlations and develop appropriate transformations. The transformation parameters (like mapping functions or representation encoders) are learned during this phase using the protected attributes. Second, during deployment, you apply these pre-computed transformations to new data without requiring protected attributes as inputs. For example, with disparate impact removal, you learn the transform functions for each feature during development by analyzing their distributions conditioned on protected attributes. Once these transform functions are established, they can be applied to new instances without knowing their protected attributes. Similarly, with fair representation learning, you train encoders that create fair representations during development, but during deployment, these encoders transform features without needing protected attributes as inputs. This approach ensures transformations address bias during both training and inference, even when protected attributes are unavailable or legally restricted during deployment.
FAQ 2: Handling Multiple Protected Attributes
Q: How should distribution transformations address multiple protected attributes simultaneously, especially when they might require different or even conflicting transformations?
A: Addressing multiple protected attributes requires careful design choices based on your specific context. One effective approach is intersectional transformation, where you define transformation targets based on combinations of protected attributes rather than addressing each independently. For example, instead of separately making features independent of race and gender, transform them to be independent of race-gender combinations. This preserves legitimate differences between intersectional groups while removing discriminatory patterns. Another approach is hierarchical transformation, applying sequential transformations with carefully prioritized ordering based on legal requirements or ethical priorities. For truly conflicting requirements, explicit multi-objective optimization can help find optimal trade-offs, potentially using techniques like Pareto front analysis to identify transformations that balance multiple fairness criteria. Finally, causal modeling can help distinguish which attribute dependencies reflect legitimate relationships versus discriminatory patterns, guiding more nuanced transformations that address bias without removing necessary information. The best approach depends on your specific application, legal requirements, and the causal relationships in your data, which should be explicitly documented in your fairness analysis.
6. Project Component Development
Component Description
In Unit 5, you will develop the distribution transformation section of the Pre-processing Strategy Selector. This component will provide structured guidance for selecting and implementing appropriate distribution transformation techniques based on specific data characteristics, bias patterns, and application requirements.
The deliverable will include a decision framework for determining when distribution transformation is appropriate, a technique catalog matching specific bias patterns to optimal transformation approaches, and implementation guidelines for each technique.
Development Steps
- Create a Distribution Transformation Decision Tree: Develop a structured decision framework that guides users through determining whether distribution transformation is appropriate for their fairness challenge, which specific techniques to apply, and how to configure those techniques based on data characteristics and bias patterns.
- Build a Transformation Technique Catalog: Design a comprehensive catalog of distribution transformation techniques, including their mathematical foundations, implementation requirements, appropriate use cases, and known limitations. Ensure the catalog covers a range of approaches from simple univariate transformations to sophisticated representation learning.
- Develop Implementation Guidelines: Create practical guidance for implementing selected transformation techniques, including code patterns, parameter tuning approaches, computational considerations, and integration guidelines for incorporating transformations into existing ML workflows.
Integration Approach
This distribution transformation component will interface with other parts of the Pre-processing Strategy Selector by:
- Building on the bias patterns identified through data auditing techniques.
- Complementing the reweighting and resampling approaches by addressing different bias mechanisms.
- Providing transformation options that can be combined with other pre-processing techniques in comprehensive fairness strategies.
For successful integration, document clear decision criteria for when distribution transformation is preferred over or should complement other pre-processing approaches. Establish standard interfaces that allow transformation techniques to work with other components in consistent data processing pipelines.
7. Summary and Next Steps
Key Takeaways
This Unit has explored how distribution transformation approaches can effectively address fairness issues by modifying feature representations to reduce problematic correlations with protected attributes while preserving legitimate predictive information. Key insights include:
- Disparate impact removal provides a direct approach for transforming individual features to ensure their distributions are independent of protected attributes while maintaining rank ordering within groups.
- Optimal transport techniques offer a mathematically principled framework for transforming distributions with minimal information loss, particularly valuable for complex, multidimensional features.
- Fair representation learning enables the creation of entirely new feature spaces optimized for both fairness and utility, especially powerful for high-dimensional or unstructured data.
- Intersectional considerations require extending transformation approaches to address overlapping demographic categories rather than treating protected attributes in isolation.
These concepts directly address our guiding questions by providing concrete techniques for transforming feature distributions to mitigate bias while preserving predictive utility, along with the mathematical foundations and practical implementations of these approaches.
Application Guidance
To apply these concepts in your practical work:
- Begin with thorough feature correlation analysis to identify which features exhibit problematic associations with protected attributes, quantifying both these correlations and each feature's legitimate predictive power.
- Select appropriate transformation techniques based on feature characteristics: simple univariate transformations for independent features with direct correlations, optimal transport for feature clusters with internal relationships, and representation learning for complex or high-dimensional features.
- Implement transformations with explicit parameterization of the fairness-utility trade-off, allowing adjustment based on application requirements.
- Evaluate transformations using both independence metrics (to verify bias reduction) and utility preservation measures (to ensure predictive power is maintained).
For organizations new to distribution transformation, start with simpler techniques like univariate disparate impact removal before progressing to more sophisticated approaches. Document transformation decisions and their impacts to build organizational understanding of these techniques.
Looking Ahead
In the next Unit, we will build on these distribution transformation approaches by exploring fairness-aware data generation—techniques that create entirely new synthetic datasets with desired fairness properties. While distribution transformation modifies existing data, generation approaches offer alternatives when existing data is insufficient or too heavily biased for effective transformation.
The transformation techniques you've learned in this Unit will provide important foundations for understanding generative approaches, as many generation methods build on the same mathematical principles of creating distributions with specific statistical properties. By combining both transformation and generation in your fairness toolkit, you'll be prepared to address a wider range of pre-processing challenges.
References
Feldman, M., Friedler, S. A., Moeller, J., Scheidegger, C., & Venkatasubramanian, S. (2015). Certifying and removing disparate impact. In Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 259–268). https://doi.org/10.1145/2783258.2783311
Foulds, J. R., Islam, R., Keya, K. N., & Pan, S. (2020). An intersectional definition of fairness. In 2020 IEEE 36th International Conference on Data Engineering (pp. 1996–1999). https://doi.org/10.1109/ICDE48307.2020.00203
Jiang, R., Pacchiano, A., Stepleton, T., Jiang, H., & Chiappa, S. (2020). Wasserstein fair classification. In Uncertainty in Artificial Intelligence (pp. 862–872). http://proceedings.mlr.press/v115/jiang20a.html
Madras, D., Creager, E., Pitassi, T., & Zemel, R. (2018). Learning adversarially fair and transferable representations. In International Conference on Machine Learning (pp. 3384–3393). http://proceedings.mlr.press/v80/madras18a.html
Zemel, R., Wu, Y., Swersky, K., Pitassi, T., & Dwork, C. (2013). Learning fair representations. In International Conference on Machine Learning (pp. 325–333). http://proceedings.mlr.press/v28/zemel13.html
Lum, K., & Johndrow, J. E. (2016). A statistical framework for fair predictive algorithms. arXiv preprint arXiv:1610.08077. https://arxiv.org/abs/1610.08077
Creager, E., Madras, D., Jacobsen, J.-H., Weis, M., Swersky, K., Pitassi, T., & Zemel, R. (2019). Flexibly fair representation learning by disentanglement. In International Conference on Machine Learning (pp. 1436–1445). http://proceedings.mlr.press/v97/creager19a.html
Unit 4
Unit 4: Fairness-Aware Data Generation
1. Conceptual Foundation and Relevance
Guiding Questions
- Question 1: How can generative approaches create balanced datasets that preserve desired properties while mitigating bias patterns identified in original data?
- Question 2: What are the trade-offs between modifying existing data through reweighting or transformation versus generating entirely new synthetic data for fairness purposes?
Conceptual Context
When traditional pre-processing approaches like reweighting or feature transformation prove insufficient for addressing fairness concerns, generative methods offer a powerful alternative by creating entirely new, fairness-aware data. This approach becomes particularly valuable when existing datasets exhibit severe imbalances, contain limited examples of minority groups, or when privacy constraints prevent direct modification of original data.
Rather than merely adjusting existing instances, fairness-aware data generation creates synthetic samples that can address representation gaps, reduce problematic correlations, and provide more balanced training data. As Iosifidis and Ntoutsi (2018) note, "generation approaches can produce data that would be statistically improbable or even impossible to collect in the real world," enabling fairness improvements that traditional preprocessing cannot achieve.
This capability is crucial for addressing the fundamental tension you face when working with biased datasets: how to mitigate historical discrimination patterns while preserving legitimate predictive signals. Generation approaches can help resolve this tension by creating synthetic data that maintains informative relationships while removing discriminatory patterns.
This Unit builds directly on previous concepts—utilizing the auditing insights from Unit 1 to identify what fairness issues need addressing, and extending the reweighting (Unit 2) and transformation (Unit 3) approaches into the generative domain. Understanding when and how to apply generative techniques will complete your pre-processing toolkit, providing critical capabilities for the Pre-processing Strategy Selector you'll develop in Unit 5.
2. Key Concepts
Synthetic Data Generation for Fairness
Synthetic data generation provides a powerful mechanism for creating balanced, bias-mitigated datasets when original data exhibits problematic patterns. Unlike reweighting or transformation techniques that modify existing instances, generative approaches create entirely new samples that follow specified fairness constraints while maintaining other desirable data properties.
This generative approach connects to other fairness concepts by addressing fundamental limitations of traditional pre-processing methods. While reweighting can adjust instance influence and transformation can modify feature distributions, neither can effectively address severe underrepresentation or create counterfactual examples that would be statistically rare or nonexistent in original data. Synthetic generation fills this gap by creating examples that satisfy fairness requirements without being limited by the distribution of available data.
Recent advancements in generative models have dramatically expanded our capabilities in this domain. Xu et al. (2019) demonstrated that fairness-aware generative adversarial networks (GANs) can produce synthetic data with significantly reduced bias while maintaining high utility for downstream tasks. Their FairGAN approach simultaneously learned to generate realistic data and remove discriminative patterns, resulting in synthetic datasets where protected attributes were no longer predictable from other features.
For example, in a loan application scenario, a fairness-aware generator might create synthetic applicants with combinations of features (income levels, education backgrounds, geographical locations) that break historical correlations with protected attributes like race or gender. These synthetic examples can then be combined with original data to create a more balanced training set that maintains predictive utility while reducing discriminatory signals.
In your Pre-processing Strategy Selector, synthetic data generation will serve as a powerful option for scenarios where representation gaps are severe or where problematic correlations cannot be adequately addressed through less invasive techniques. The key insight is that generation can create examples beyond what exists in your original data, enabling fairness improvements that would be impossible through modification alone.
Conditional Generation for Group Fairness
Conditional generation techniques enable fine-grained control over synthetic data characteristics by explicitly conditioning the generation process on protected attributes and other relevant variables. This approach is particularly valuable for addressing group fairness concerns by ensuring balanced representation and consistent feature distributions across demographic categories.
This conditional approach interacts with previous concepts by providing a more controlled alternative to general synthetic generation. While basic generative methods might improve overall dataset balance, conditional approaches offer explicit guarantees about representation levels and feature distributions across specified groups. This capability directly addresses the group fairness definitions explored in Sprint 1, creating datasets where statistical parity or other fairness metrics are satisfied by design.
Research by Choi et al. (2020) on conditional tabular GANs demonstrated that explicitly conditioning generation on protected attributes allows for precise control over group proportions and feature distributions. Their approach enabled generation of synthetic datasets with specified demographic compositions while preserving complex relationships between non-sensitive variables.
For instance, in an employment dataset, conditional generation could create synthetic candidates across different gender and racial groups with similar qualification distributions. This approach ensures that each demographic group is equally represented and that correlations between qualifications and demographic attributes are reduced or eliminated, directly addressing potential sources of group-level discrimination.
The key advantage of conditional generation for your Pre-processing Strategy Selector is its ability to create training data with precise fairness properties. Rather than hoping that model training on modified data will result in fair predictions, conditional generation allows you to construct datasets where desired fairness criteria are explicitly satisfied, providing stronger guarantees about downstream fairness outcomes.
Counterfactual Data Augmentation
Counterfactual data augmentation explicitly creates "what if" scenarios by generating examples that alter protected attributes while preserving other legitimate characteristics. This approach directly operationalizes the counterfactual fairness concept introduced in Part 1, creating training data that helps models learn invariance to protected attributes along problematic causal pathways.
This counterfactual approach builds upon basic synthetic generation by incorporating causal understanding into the generative process. Rather than simply creating balanced data, counterfactual augmentation specifically targets the causal mechanisms through which discrimination operates, generating examples that break problematic causal dependencies while maintaining legitimate predictive relationships.
Kusner et al. (2017) introduced this approach in their work on counterfactual fairness, demonstrating how counterfactual examples can help train models that satisfy causal fairness definitions. By generating examples where protected attributes are changed while causally independent variables remain constant, they created training data that encouraged models to ignore discriminatory pathways.
Concretely, counterfactual augmentation might generate variants of each individual in a dataset with different protected attributes but identical qualifications. For example, in a resume screening context, this approach would create counterfactual examples that answer: "What would this resume look like if the candidate were from a different demographic group, but all causally independent qualifications remained the same?" These counterfactual pairs help models learn to make consistent predictions regardless of protected attributes.
For your Pre-processing Strategy Selector, counterfactual augmentation provides a direct connection between the causal understanding developed in Part 1 and the pre-processing interventions in this Part. This approach is particularly valuable when causal analysis has identified specific pathways through which discrimination operates, enabling targeted interventions that address root causes rather than symptoms of unfairness.
Domain Modeling Perspective
From a domain modeling perspective, fairness-aware data generation maps to specific components of ML systems:
- Data Requirements Analysis: Generative approaches start by identifying what characteristics the synthetic data must satisfy, including fairness constraints, diversity requirements, and utility needs.
- Generation Process Design: The core generation component determines how synthetic samples will be created, including model architecture, training approach, and evaluation criteria.
- Fairness Constraint Implementation: Specific mechanisms enforce desired fairness properties, whether through model constraints, objective functions, or post-generation filtering.
- Dataset Integration: Final synthetic data must be appropriately combined with original data or used independently, with considerations for weighting, validation, and transition strategies.
- Quality Assurance: Comprehensive evaluation ensures synthetic data satisfies both fairness requirements and utility objectives.
This domain mapping helps you understand how generative approaches fit within broader ML workflows rather than viewing them as isolated techniques. The Pre-processing Strategy Selector will leverage this mapping to guide implementation decisions across each component of the generation process.
Conceptual Clarification
To clarify these abstract generative concepts, consider the following analogies:
- Synthetic data generation for fairness functions like creating a custom recipe rather than modifying an existing dish. When a chef finds that available ingredients are imbalanced or have undesirable properties, rather than trying to salvage the problematic ingredients through selective use (reweighting) or transformation (processing techniques), they might create an entirely new dish from scratch with precisely controlled ingredients. Similarly, fairness-aware generation creates new data "from scratch" with exactly the properties you want, rather than struggling to fix problematic patterns in existing data.
- Conditional generation for group fairness resembles a customized manufacturing process that produces items with precisely specified characteristics. Rather than sorting and modifying existing inventory (like reweighting or transformation), a manufacturer can program production lines to create new items with exact specifications for different markets. Similarly, conditional generation lets you "program" the creation of synthetic examples with precise distributions of characteristics across different demographic groups, ensuring representation balance by design.
- Counterfactual data augmentation is comparable to creating parallel universe versions of the same individual. Imagine if, for a clinical trial, you could observe the exact same person in parallel universes where only their demographic characteristics differ but all other relevant medical factors remain identical. This would allow perfect isolation of demographic effects. Similarly, counterfactual augmentation creates these "parallel versions" of data points that differ only in protected attributes, helping models learn that these attributes should not influence predictions.
Intersectionality Consideration
Traditional data generation approaches often address protected attributes independently, potentially missing critical intersectional considerations where multiple attributes interact to create unique fairness challenges. Effective fairness-aware generation must explicitly model these intersections to ensure equitable representation and appropriate feature distributions across all demographic subgroups.
As Ghosh et al. (2021) demonstrate in their work on intersectional fairness in generative models, naively generating data to balance individual protected attributes can still leave intersectional subgroups underrepresented or stereotypically portrayed. Their research shows that explicitly modeling intersectionality during generation requires:
- Multi-attribute conditioning that simultaneously controls multiple protected characteristics.
- Subgroup-specific quality monitoring to ensure all intersectional groups receive high-quality synthetic examples.
- Explicit constraints that prevent stereotypical attribute combinations at demographic intersections.
- Evaluation metrics that assess representation quality across all relevant intersectional subgroups.
For example, in an employment dataset, addressing gender and race independently might improve overall representation for women and for racial minorities, but still leave women of color underrepresented or with stereotypical feature distributions. Intersectional generation would explicitly ensure adequate representation and appropriate feature distributions for each specific gender-race combination.
For your Pre-processing Strategy Selector, incorporating intersectional considerations means ensuring that generative approaches can handle multiple protected attributes simultaneously, with explicit controls and evaluation metrics for intersectional subgroups. This capability is essential for addressing the complex interactions between different forms of discrimination that can easily be missed by single-attribute approaches.
3. Practical Considerations
Implementation Framework
To effectively implement fairness-aware data generation, follow this structured methodology:
-
Requirements Analysis and Specification
-
Analyze existing data to identify specific fairness issues requiring generation (representation gaps, problematic correlations, etc.).
- Define clear fairness objectives for the synthetic data, including desired representation levels and eliminated correlations.
- Specify utility requirements that must be preserved, including important feature relationships and predictive signals.
-
Document the target characteristics and constraints in a comprehensive generation specification.
-
Generation Approach Selection and Design
-
Select appropriate generative models based on data characteristics and fairness objectives.
- Design the generation architecture, including model structure, training approach, and fairness enforcement mechanism.
- Implement conditioning mechanisms for controlling protected attribute distributions and relationships.
-
Develop evaluation methods for assessing both fairness and utility during generation.
-
Constraint Implementation and Training
-
Formulate fairness constraints as explicit model components or objective function terms.
- Implement appropriate regularization to prevent overfitting to original data biases.
- Train the generative model with both realism and fairness objectives.
-
Perform iterative refinement based on fairness and utility metrics.
-
Integration and Transition Strategy
-
Determine optimal combination of original and synthetic data based on fairness objectives.
- Develop appropriate weighting schemes for synthetic examples.
- Create clear documentation of synthetic data properties and generation process.
- Establish validation approaches for assessing downstream model performance on synthetic data.
This methodology integrates with standard ML workflows by providing a structured approach to generating synthetic data as part of the pre-processing pipeline. While it adds complexity compared to simpler pre-processing techniques, it offers capabilities for addressing fairness issues that cannot be resolved through less invasive methods.
Implementation Challenges
When implementing fairness-aware data generation, practitioners commonly face these challenges:
-
Balancing Fairness and Fidelity: Generated data must simultaneously satisfy fairness requirements while remaining realistic and useful. Address this by:
-
Implementing multi-objective optimization approaches that explicitly balance fairness and fidelity.
- Developing staged generation processes where realism is established before fairness constraints are applied.
- Creating comprehensive evaluation metrics that assess both dimensions.
-
Performing sensitivity analysis to identify optimal trade-off points.
-
Preventing Synthetic Data Artifacts: Generated data may contain unrealistic patterns or artifacts that negatively impact downstream models. Address this by:
-
Implementing robust validation procedures that check for unrealistic feature combinations.
- Using domain experts to review generated samples for plausibility.
- Incorporating domain constraints as explicit components of the generation process.
- Performing gradual integration of synthetic data to monitor for unexpected effects.
Successfully implementing fairness-aware generation requires resources including technical expertise in generative models, computational resources for training complex generative architectures, domain knowledge for validating synthetic data quality, and organizational willingness to adopt synthetic data in production pipelines.
Evaluation Approach
To assess whether your fairness-aware data generation is effective, implement these evaluation strategies:
-
Fairness Impact Assessment:
-
Measure fairness metrics on models trained with generated data compared to original data.
- Assess representation levels and feature distributions across protected groups.
- Evaluate correlation reductions between protected attributes and other features.
-
Measure counterfactual consistency in model predictions across synthetic variants.
-
Utility Preservation Verification:
-
Compare predictive performance on legitimate tasks between models trained on original versus generated data.
- Assess whether important feature relationships are maintained in the synthetic data.
- Measure the statistical similarity between original and generated distributions on non-sensitive features.
- Conduct ablation studies to identify any negative impacts from generation constraints.
These evaluation approaches should be integrated with your organization's broader fairness assessment framework, providing metrics that specifically assess the impact of synthetic data on both fairness and utility objectives.
4. Case Study: Healthcare Risk Prediction
Scenario Context
A healthcare provider is developing a machine learning system to predict risk of hospital readmission for patients after discharge. The algorithm will analyze medical history, demographics, treatment details, and social determinants of health to identify patients who might benefit from additional follow-up care. Initial data analysis revealed concerning disparities: the historical dataset contained fewer examples of certain demographic groups, particularly elderly patients from minority racial backgrounds and those from rural areas.
Standard fairness approaches like reweighting proved insufficient because some demographic intersections (e.g., elderly rural minority patients) had extremely limited representation—in some cases fewer than 10 examples. Additionally, the sensitive nature of healthcare data made it difficult to obtain more samples from these underrepresented groups.
Key stakeholders include clinical care teams who need accurate risk predictions to allocate limited follow-up resources, hospital administrators concerned about readmission rates and care quality, and patients who deserve equitable access to preventative care. Fairness is particularly critical in this context because unaddressed biases could perpetuate or worsen existing healthcare disparities by directing additional care resources away from already underserved populations.
Problem Analysis
Applying the concepts from this Unit reveals several ways that fairness-aware data generation could address the healthcare prediction challenges:
- Representation Gaps: The severe underrepresentation of certain demographic intersections makes traditional reweighting approaches insufficient—there simply aren't enough examples to upweight. Basic synthetic generation could create additional examples of underrepresented groups, but would need to preserve complex medical relationships while avoiding stereotypical patterns.
- Complex Feature Relationships: Healthcare data involves intricate relationships between medical conditions, treatments, and outcomes that vary across demographic groups due to both biological factors and social determinants of health. Generated data would need to preserve legitimate medical relationships while mitigating biases from historical care disparities.
- Causal Complexity: Some demographic disparities in the data reflect genuine biological differences in disease presentation, while others result from historical inequities in healthcare access. Counterfactual generation approaches would need to differentiate between these mechanisms, preserving the former while addressing the latter.
- Privacy Constraints: Healthcare data is subject to strict privacy regulations, limiting the ability to share or directly modify original data. Synthetic generation offers the potential to create training data that preserves statistical patterns without exposing real patient information.
From an intersectional perspective, the analysis becomes even more complex. The data revealed unique patterns for specific combinations of age, race, and geography that would be missed by addressing each attribute independently. For instance, older Black patients from rural areas showed unique readmission patterns that differed significantly from what would be predicted by examining each factor separately.
Solution Implementation
To address these challenges through fairness-aware data generation, the team implemented a multi-stage approach:
-
Requirements Analysis: The team began by defining specific fairness and utility objectives for the synthetic data:
-
Achieve balanced representation across all demographic intersections
- Eliminate correlations between social determinants and care quality indicators
- Preserve medically legitimate relationships between conditions and outcomes
-
Maintain overall predictive utility for readmission risk
-
Generation Approach Selection: After evaluating options, they selected a conditional variational autoencoder (CVAE) approach because:
-
It offered fine-grained control over demographic attributes
- The latent space representation helped capture complex medical relationships
- The conditional structure allowed for explicit fairness constraints
-
The probabilistic nature produced diverse yet realistic samples
-
Fairness Constraint Implementation: They incorporated multiple fairness mechanisms:
-
Conditional generation explicitly controlled demographic compositions
- Adversarial components prevented the model from learning biased patterns
- Causal constraints preserved legitimate medical relationships while removing discriminatory ones
-
Regularization techniques prevented overfitting to biased historical patterns
-
Synthetic Data Integration: The team developed a comprehensive integration strategy:
-
Created a hybrid dataset combining original data with synthetic examples
- Implemented importance weighting to balance the influence of real and synthetic samples
- Developed a gradual transition approach that incrementally increased synthetic data usage
- Established comprehensive validation protocols to verify model performance
Throughout implementation, they maintained explicit focus on intersectional fairness, ensuring generation quality across all demographic subgroups and monitoring performance at the finest granularity possible given data limitations.
Outcomes and Lessons
The fairness-aware generation approach yielded significant improvements:
- Models trained on the augmented dataset showed a 43% reduction in prediction disparities across demographic groups.
- The synthetic data enabled identification of previously undetected risk factors for underrepresented populations.
- Privacy concerns were addressed as the final model could be trained without requiring access to all original patient data.
- The approach created a more balanced baseline for evaluating future fairness interventions.
Key challenges included computational complexity of the generative models, difficulty validating medical realism of synthetic patients, and initial skepticism from clinical teams about using synthetic data for healthcare decisions.
The most generalizable lessons included:
- The importance of distinguishing between legitimate and problematic correlations in the generation process—not all demographic differences represent bias.
- The value of domain expert involvement throughout the generation process to validate synthetic data quality.
- The necessity of comprehensive evaluation across both fairness and utility dimensions to ensure improvements in one don't compromise the other.
These insights directly inform the development of the Pre-processing Strategy Selector in Unit 5, particularly in establishing decision criteria for when generative approaches are most appropriate and how they should be configured for different application contexts.
5. Frequently Asked Questions
FAQ 1: When to Generate Vs. When to Modify
Q: How do I determine whether to apply fairness-aware data generation versus simpler techniques like reweighting or feature transformation?
A: The decision between generating new data versus modifying existing data depends on several key factors. First, consider representation gaps—if certain demographic groups have extremely limited samples (typically fewer than 20-30 examples or less than 5% of their expected proportion), reweighting alone becomes statistically unreliable and generation provides a more robust solution. Second, assess correlation complexity—if problematic associations are deeply embedded across multiple features, transformation approaches may struggle to remove bias without sacrificing legitimate information, while generative approaches can reconstruct data without these problematic patterns. Third, evaluate data constraints—if privacy regulations or ownership issues restrict direct data modification, synthetic generation may be the only viable approach. Finally, consider resource availability—generation requires more technical expertise and computational resources than simpler methods, so ensure these are available before proceeding. As a practical decision rule, start with the least invasive approach (reweighting) for mild imbalances, progress to transformation for moderate correlation issues, and reserve generation for cases where representation gaps are severe, correlations are complex, or constraints prevent other methods.
FAQ 2: Validating Synthetic Data Quality
Q: How can I ensure that synthetic data genuinely improves fairness without introducing new biases or unrealistic patterns?
A: Comprehensive validation of synthetic data requires a multi-faceted approach addressing both fairness and quality dimensions. For fairness validation, first measure all relevant fairness metrics on models trained with generated data compared to original data, using held-out test sets to ensure improvements generalize beyond training. Examine not just overall metrics but also performance across intersectional subgroups to verify that fairness improvements are consistent. For quality validation, implement statistical tests comparing feature distributions between real and synthetic data across non-sensitive attributes, while using domain experts to review samples for plausibility and coherence. Particularly valuable are counterfactual consistency checks—if you generate variants that differ only in protected attributes, downstream models should produce consistent predictions across these variants. Additionally, implement progressive integration by gradually increasing the proportion of synthetic data in training and monitoring both fairness and performance impacts at each stage. Finally, establish ongoing monitoring systems that track model performance on real-world data after deployment, as synthetic data benefits sometimes diminish when models encounter genuine data distributions. The most reliable approach combines quantitative metrics with qualitative expert review, statistical distribution tests with practical performance evaluation, and pre-deployment validation with post-deployment monitoring.
6. Project Component Development
Component Description
In Unit 5, you will develop the fairness-aware data generation component of the Pre-processing Strategy Selector. This component will provide structured approaches for determining when generative techniques are appropriate and how they should be configured for different fairness challenges.
The deliverable will include selection criteria for choosing between different generation approaches, implementation guidelines for configuring generative models with fairness constraints, and evaluation frameworks for assessing synthetic data effectiveness.
Development Steps
- Create Generation Approach Decision Tree: Develop a structured decision framework that guides when to use synthetic data generation based on data characteristics, fairness objectives, and implementation constraints. Include specific criteria for selecting between different generative model architectures (GANs, VAEs, etc.) based on data types and fairness goals.
- Build Fairness Constraint Implementation Guide: Design a framework for incorporating fairness considerations into generative models, including approaches for conditional generation, adversarial constraints, and counterfactual rules. Provide configuration templates that can be adapted to different fairness definitions and application contexts.
- Develop Synthetic Data Integration Strategy: Create guidelines for effectively combining generated data with original data, including recommendations for appropriate mixing ratios, weighting schemes, and transition strategies. Address considerations for validating effectiveness and maintaining performance.
Integration Approach
This generation component will interface with other parts of the Pre-processing Strategy Selector by:
- Building on the auditing approaches from Unit 1 to identify scenarios where generation is appropriate.
- Providing alternative or complementary approaches to the reweighting (Unit 2) and transformation (Unit 3) techniques.
- Creating structured decision criteria that fit within the overall selector framework.
- Establishing evaluation approaches that compare generation effectiveness with other pre-processing options.
To enable successful integration, document the relative advantages and limitations of generative approaches compared to other techniques, create clear decision points for when to escalate from simpler methods to generation, and develop consistent interfaces between different pre-processing components.
7. Summary and Next Steps
Key Takeaways
In this Unit, you've explored how fairness-aware data generation provides powerful capabilities for addressing fairness challenges that cannot be adequately resolved through simpler pre-processing techniques. Key insights include:
- Generation capabilities extend beyond modification: Synthetic data generation allows you to create entirely new examples with specified fairness properties, overcoming fundamental limitations of reweighting and transformation approaches when dealing with severe representation gaps or complex bias patterns.
- Conditional approaches enable fine-grained fairness control: By explicitly conditioning generation on protected attributes and other variables, you can create datasets with precisely controlled demographic compositions and feature distributions, ensuring fairness by design rather than trying to retrofit it onto existing data.
- Counterfactual generation operationalizes causal fairness: Creating synthetic examples that vary protected attributes while maintaining other legitimate characteristics provides a direct implementation of the counterfactual fairness concept, helping models learn invariance to discriminatory factors.
- Generation approaches require careful validation: Synthetic data must be rigorously evaluated along both fairness and utility dimensions to ensure it genuinely improves fairness without introducing artifacts or sacrificing legitimate predictive power.
These concepts directly address our guiding questions by demonstrating how generative approaches can create balanced, bias-mitigated datasets while preserving desired properties, and by clarifying the trade-offs between modification and generation approaches for different fairness scenarios.
Application Guidance
To apply these concepts in your practical work:
- Start by determining whether fairness-aware generation is appropriate for your specific context. Consider using generation when: (a) representation gaps are severe, (b) bias patterns are complex and deeply embedded, (c) privacy or legal constraints prevent direct data modification, or (d) simpler approaches have proven insufficient.
- If generation is appropriate, select a generative approach based on your data characteristics—GANs often work well for image data, VAEs for structured tabular data, and statistical approaches for simpler scenarios. Implement explicit fairness constraints through conditioning, adversarial components, or specialized objectives.
- Develop a comprehensive validation strategy that assesses both fairness improvements and utility preservation. Combine quantitative metrics with qualitative expert review, and implement progressive integration to monitor effects carefully.
- Document the generation process thoroughly, including model architecture, fairness constraints, training approach, and validation results. This documentation is essential for transparency and for troubleshooting any issues that arise.
If you're new to fairness-aware generation, consider starting with simpler approaches like conditional statistical generation before progressing to more complex neural methods. These simpler techniques often provide a valuable baseline while requiring less technical expertise and computational resources.
Looking Ahead
In the next Unit, you will synthesize all the pre-processing approaches covered in this Part—from auditing through reweighting, transformation, and generation—into a comprehensive Pre-processing Strategy Selector. This selector will provide structured guidance for determining which pre-processing techniques are most appropriate for different fairness challenges, and how they should be configured and evaluated.
The generative approaches you've learned in this Unit will serve as powerful options within this selector, particularly for challenging scenarios where simpler approaches prove insufficient. By integrating generation with other pre-processing techniques, you'll develop a comprehensive toolkit for addressing fairness issues at the data level before model training even begins.
References
Choi, E., Biswal, S., Malin, B., Duke, J., Stewart, W. F., & Sun, J. (2017). Generating multi-label discrete patient records using generative adversarial networks. In Proceedings of the Machine Learning for Healthcare Conference (pp. 286-305). PMLR.
Ghosh, A., Chakraborty, A., Vempala, S. S., & Uppal, A. (2021). Removing disparate impact of differentially private stochastic gradient descent on model accuracy. arXiv preprint arXiv:2103.13775.
Iosifidis, V., & Ntoutsi, E. (2018). Dealing with bias via data augmentation in supervised learning scenarios. In Proceedings of the Workshop on AI For Societal Good.
Kusner, M. J., Loftus, J., Russell, C., & Silva, R. (2017). Counterfactual fairness. In Advances in Neural Information Processing Systems (pp. 4066-4076).
Sattigeri, P., Hoffman, S. C., Chenthamarakshan, V., & Varshney, K. R. (2019). Fairness GAN: Generating datasets with fairness properties using a generative adversarial network. IBM Journal of Research and Development, 63(4/5), 3:1-3:9.
Xu, D., Yuan, S., Zhang, L., & Wu, X. (2019). FairGAN: Fairness-aware generative adversarial networks. In 2019 IEEE International Conference on Big Data (pp. 1401-1410). IEEE.
Zhang, B., Lemoine, B., & Mitchell, M. (2018). Mitigating unwanted biases with adversarial learning. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society (pp. 335-340).
Unit 5
Unit 5: Pre-Processing Fairness Toolkit
1. Introduction
In Part 2, you learned about data auditing, reweighting, transformation approaches, and fairness-aware data generation. These techniques fix bias at its source: the data itself. Now you'll build a Pre-Processing Fairness Toolkit – the second component of the Sprint 2 Project - Fairness Intervention Playbook. This toolkit will help teams select the right interventions for specific bias patterns before model training even begins.
2. Context
Imagine you're a staff engineer at a mid-sized bank working with a team implementing a loan approval system. The causal analysis from Part 1 uncovered troubling patterns. Male applicants receive approvals at a 76% rate while equally qualified female applicants get approved only 58% of the time. This happens despite nearly identical repayment histories.
Your analysis pinpointed several mechanisms behind this gap:
- Career breaks create employment history gaps that penalize women
- Income differences stem partly from gender-based wage disparities
- Part-time status correlates with gender due to caregiving roles
The data science team now needs guidance. Which pre-processing techniques will most effectively address these issues? How should they configure these interventions? What trade-offs will they face?
You'll build a Pre-Processing Fairness Toolkit to guide them through these decisions. The toolkit will help any team tackle data-level biases in AI systems methodically and effectively.
3. Objectives
By completing this project component, you will practice:
- Matching bias patterns to specific data interventions.
- Creating decision frameworks that cut through complexity.
- Developing configuration guidelines for real-world constraints.
- Designing methods to measure intervention impact.
- Balancing fairness gains against information loss.
- Linking causal insights to practical data transformations.
4. Requirements
Your Pre-Processing Fairness Toolkit must include:
- A technique catalog documenting pre-processing approaches with their mathematical foundations, strengths, limitations, and use cases.
- A selection decision tree guiding choices based on bias patterns, fairness definitions, and constraints.
- Configuration guidelines for tuning techniques to specific contexts.
- An evaluation framework measuring impact on fairness, information preservation, and computational cost.
- User documentation explaining how to apply the toolkit.
- A case study showing the toolkit's application to a loan approval system.
5. Sample Solution
The following solution from a former colleague can serve as an example. Note that it lacks some key components your toolkit should include.
5.1 Technique Catalog
The Technique Catalog documents pre-processing approaches:
Reweighting Approaches:
- Instance Weighting:
- Description: Adjusts training example influence to balance representation.
- Use Cases: Fixes representation gaps when models support sample weights.
- Strengths: Keeps all data points; offers adjustable intervention strength.
- Limitations: Not all models support weights; can increase variance.
- Prejudice Removal:
- Description: Modifies labels to reduce correlation with protected attributes.
- Use Cases: Addresses historical bias in labels while preserving data distribution.
- Strengths: Targets label bias directly; maintains sample counts.
- Limitations: May introduce new biases; needs careful calibration.
Transformation Techniques:
- Disparate Impact Removal:
- Description: Transforms features to maintain rank order while minimizing protected attribute correlation.
- Use Cases: Addresses proxy discrimination in continuous features.
- Strengths: Preserves relative ordering within groups; offers adjustable transformation intensity.
- Limitations: May reduce predictive power; demands computation for high-dimensional data.
- Fair Representations:
- Description: Creates new feature space that masks protected attributes while preserving prediction signals.
- Use Cases: Tackles multiple bias types; handles complex feature interactions.
- Strengths: Manages non-linear relationships; scales to high-dimensional data.
- Limitations: Reduces interpretability; requires careful tuning.
5.2 Selection Decision Tree
The Selection Decision Tree guides key decisions:
Step 1: Bias Pattern Identification
- What bias patterns did your causal analysis reveal?
- Representation disparities → Go to Step 2
- Proxy discrimination → Go to Step 3
- Label bias → Go to Step 4
- Multiple bias types → Consider combined approaches
Step 2: Representation Disparities
- Does your model support instance weights?
- Yes → Instance Weighting
- No → Does your data have enough samples from underrepresented groups?
- Yes → Resampling
- No → Synthetic Data Generation
Step 3: Proxy Discrimination
- Can you identify the proxy features?
- Yes → Is interpretability crucial?
- Yes → Disparate Impact Removal
- No → Fair Representations
- No → Fair Representations or adversarial approaches
Step 4: Label Bias
- Does historical discrimination cause the bias?
- Yes → Prejudice Removal or Massaging
- No → Reconsider data collection processes
5.3 Configuration Guidelines
The Configuration Guidelines help tune each technique:
Instance Weighting Configuration:
-
Select weighting scheme based on fairness goal:
-
For demographic parity: Inverse frequency weighting
-
For equal opportunity: Conditional inverse frequency weighting
-
Set intervention strength:
-
Start with moderate weights (square root of inverse frequency)
- Increase gradually if fairness improvements fall short
-
Cap weights to prevent instability
-
Validate results:
-
Watch loss convergence for instability signs
- Check for overfitting in minority groups
- Verify fairness gains on validation data
Disparate Impact Removal Configuration:
-
Select features:
-
Target features strongly correlated with protected attributes
-
Keep critical predictive features with legitimate relationships
-
Set transformation intensity:
-
Begin with repair level of 0.5 (partial repair)
- Adjust based on fairness-utility trade-offs
-
Consider preserving rank within groups for sensitive applications
-
Validate results:
-
Measure protected attribute correlation reduction
- Check predictive power preservation
- Verify fairness improvements on validation data
5.4 Evaluation Framework
The Evaluation Framework assesses intervention effectiveness:
Fairness Assessment:
- Measure primary fairness metrics aligned with your chosen definition
- Check intersectional fairness across multiple protected attributes
- Run statistical significance tests on improvements
- Compare results across metrics to spot trade-offs
Information Preservation:
- Measure predictive performance changes (accuracy, AUC, F1)
- Check rank ordering preservation within groups
- Assess calibration consistency across groups
- Compare feature importance before and after intervention
Computational Efficiency:
- Document processing time and memory needs
- Test scaling with dataset size
- Measure training time with transformed data
- Assess deployment implications
6. Case Study: Loan Approval System
This case study shows the Pre-Processing Fairness Toolkit in action.
6.1 System Context
The bank's loan algorithm predicts default probability from applicant data. It shows a stark gender gap: 76% approval for men versus 58% for equally qualified women. Causal analysis found several culprits:
- Employment gaps that disproportionately affect women
- Income differences partly reflecting wage disparities
- Part-time status correlating with gender due to caregiving roles
- Industry sector patterns linked to occupational gender distribution
The bank wants equal opportunity: qualified applicants should have equal approval chances regardless of gender.
6.2 Step 1: Technique Selection
Following the decision tree:
-
Bias Pattern Analysis:
-
Multiple issues found: mediator discrimination (employment history, income) and proxy discrimination (part-time status)
-
This requires a combined approach
-
For Employment History:
-
Feature transformation chosen to replace "continuous employment" with "relevant experience"
-
For Income Level:
-
Reweighting selected to balance income's influence on predictions
-
For Part-Time Status:
-
Disparate impact removal chosen to transform this proxy feature
The toolkit recommends a three-pronged strategy:
- Transform employment history features
- Apply instance weighting for income disparities
- Use disparate impact removal on part-time status
6.3 Step 2: Configuration
Following the configuration guidelines:
Employment History Transformation:
- Created "relevant experience" metric counting total years regardless of gaps
- Added skill currency features that don't penalize caregiving breaks
- Verified predictive signal retention through repayment correlation tests
Income Level Reweighting:
- Applied conditional weighting focused on equal opportunity
- Used moderate intervention strength (0.6)
- Capped maximum weights at 2.5
Part-Time Status Transformation:
- Applied disparate impact removal at 0.7 repair level
- Preserved rank ordering within gender groups
- Converted to job stability indicators instead of raw part-time flags
6.4 Step 3: Evaluation
Using the evaluation framework:
Fairness Results:
- Equal opportunity gap shrank from 0.18 to 0.04
- Statistical tests confirmed significance (p < 0.01)
- Improvements held across gender × age intersections
Information Preservation:
- Default prediction accuracy dipped just 1.8%
- Approval rates stayed at target levels
- Calibration remained consistent across groups
- Key feature rankings held stable
Efficiency Analysis:
- Pre-processing added 2.1 minutes to pipeline
- Memory needs increased 12%
- No inference time impact in production
The intervention slashed gender disparities while maintaining predictive performance. This success shows how targeting specific causal paths with the right pre-processing techniques can address data-level fairness issues effectively.
Part 2 Appendix: Data-Level Fairness Interventions: Technical Approaches and Trade-offs
Key Pre-processing Techniques for AI Fairness
| Approach | Key Methods | Best For | Limitations | Intersectionality Considerations |
|---|---|---|---|---|
| Data Auditing | Statistical analysis, visualization, bias detection | Identifying sources and types of bias; prerequisite for all interventions | Not an intervention itself; requires domain expertise | Essential to stratify analysis by multiple protected attributes |
| Sampling Methods | Oversampling, undersampling, stratified sampling | Addressing representation disparities | May not address deeper structural biases; can reduce effective dataset size | Can specifically target small intersectional groups for improved representation |
| Reweighting | Instance weights, importance weighting | Fine-tuning influence without changing data structure | May be sensitive to outliers; requires careful calibration | Enables differential treatment of intersectional groups |
| Distribution Transformation | Disparate Impact Remover, Optimal Transport | Removing correlations between protected attributes and other features | More complex to implement; may reduce task performance | Can address complex correlation patterns across multiple attributes |
| Synthetic Data Generation | SMOTE, GAN-based approaches, Fair-VAEs | Augmenting representation of minority groups | Quality concerns; ethical questions about synthetic representations | Particularly valuable for generating examples of small intersectional groups |
Causal Perspective on Pre-processing Interventions
Pre-processing interventions can be understood as modifications to the data-generating process. From a causal perspective, these techniques:
- Data Auditing: Identifies problematic causal pathways from protected attributes to outcomes
- Sampling/Reweighting: Adjusts the distribution of protected attributes to reduce their influence
- Distribution Transformation: Breaks spurious correlations between protected attributes and features
- Synthetic Data: Creates alternative data from a hypothetical fair data-generating process
Implementation Decision Framework
When selecting a pre-processing approach, consider:
- Fairness Definition: Which definition (demographic parity, equalized odds, etc.) aligns with your use case?
- Data Characteristics: What types of bias exist in your data? Are there representation disparities?
- Domain Constraints: Are there regulatory requirements or domain-specific considerations?
- Intersectional Impact: How will the intervention affect smaller subgroups defined by multiple protected attributes?
- Downstream Process: Will the pre-processing approach integrate well with your modeling pipeline?
References
- Barocas, S., & Selbst, A. D. (2016). Big data's disparate impact. California Law Review, 104, 671-732.
- Feldman, M., Friedler, S. A., Moeller, J., Scheidegger, C., & Venkatasubramanian, S. (2015). Certifying and removing disparate impact. Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.
- Kamiran, F., & Calders, T. (2012). Data preprocessing techniques for classification without discrimination. Knowledge and Information Systems, 33(1), 1-33.
- Xu, D., Yuan, S., Zhang, L., & Wu, X. (2018). FairGAN: Fairness-aware Generative Adversarial Networks. IEEE International Conference on Big Data (Big Data).
